Алгоритм. Пример
Выше фактически уже описан алгоритм нахождения хотя бы одной вершины многогранника допустимых решений. Сведем вместе все необходимые построения.
Алгоритм.
Определим направление возрастания целевой функции и выделим грани многогранника допустимых решений, образующие верхнюю (нижнюю) его поверхность. Дополним ее возможными гранями — координатными плоскостями. Составим матрицу S косинусов углов между всеми нормалями к действительным и возможным граням сформированной поверхности многогранника допустимых решений. Если число r действительных граней верхней (нижней) поверхности не меньше n — размерности задачи, выполняем первый этап алгоритма, исключив из рассмотрения строки и столбцы матрицы S, соответствующие координатным плоскостям. Этот пункт является общим для первого и второго этапов. Выбрав произвольно грань или организовав перебор всех граней, или организовав параллельный анализ всех граней, выберем в соответствующей этой грани строке матрицы S n максимальных косинусов. В этой последовательности косинусов, кроме максимального косинуса угла между нормалью выбранной грани и ею же самой, не должно быть косинусов, равных 1 или -1. Таким образом, окажутся выделенными n возможных образующих некоторой вершины многогранника допустимых решений. Решаем совместно уравнения выделенных граней. Если решение существует и оно неотрицательно, произведем анализ: удовлетворяет ли найденная точка всем ограничениям задачи? Если удовлетворяет, точка действительно является вершиной многогранника. В противном случае необходимо продолжить анализ граней, то есть строк матрицы S. Если перебор всех строк матрицы S не привел к успеху на первом этапе выполнения алгоритма, переходим ко второму этапу, введя в рассмотрение координатные плоскости, т.е. начинаем анализ матрицы в полном объеме. Если успех не был достигнут на втором этапе, то, как указано ниже, можно испытать удачу на другой — нижней (верхней) поверхности многогранника допустимых решений. Ведь важно найти хоть какую-то вершину, пусть не столь близкую к вершине-решению.
Если мы и теперь не достигли успеха…
В рассматриваемом примере верхнюю поверхность (где следует искать решение) образуют грани (6.6). Поскольку переименование малого количества граней в соответствии с (6.7) не имеет смысла, составим для этих граней и их нормалей таблицу, включающую матрицу косинусов углов между нормалями. Соответствующие косинусы считаем по (6.9) и (6.10), таблицу строим по образу таблицы 6.1. Матрица S в таблице выделена.
Реализуем первый этап алгоритма поиска вершины, исключив из рассмотрения три последние строки и столбцы.
Выберем грань q1. Максимальные косинусы соответствующей (первой) строки матрицы S указывают на систему граней {q1, q2, q3}. Решаем уравнения граней совместно и проверяем решение на выполнение всех неиспользованных ограничений задачи. Получаем вершину E(13, 8, 4).
| q1 | N1 | l | 0,59 | 0,59 | 0,067 | 0,171 | 0,026 | 0,09 | -0,99 |
| q2 | N2 | 0,59 | 1 | 0,9 | -0,43 | -0,29 | -0,56 | 0,625 | -0,56 |
| q3 | N3 | 0,59 | 0,9 | 1 | -0,25 | -0,125 | -0,28 | 0,46 | -0,84 |
| q4 | N4 | 0,067 | -0,43 | -0,25 | 1 | 0,99 | -0,16 | -0,975 | -0,16 |
| q5 | N5 | 0,171 | -0,29 | -0,125 | 0,99 | 1 | -0,27 | -0,92 | -0,27 |
| q7 | N7 | 0,026 | -0,56 | -0,28 | -0,16 | -0,27 | 1 | 0 | 0 |
| q8 | N8 | 0,09 | 0,625 | 0,46 | -0,975 | -0,92 | 0 | 1 | 0 |
| q9 | N9 | -0,99 | -0,56 | -0,84 | -0,16 | -0,27 | 0 | 0 | 1 |
Для грани q3 получаем ту же систему образующих граней, т.е. ту же вершину E.
По строке табл. 6.4 (матрицы S), соответствующей q4, находим систему {q1, q4, q5}, решением которой является вершина L{6, 10, 4}.
Анализируя строку грани q5, вновь получаем ту же вершину.
Таким образом, мы добились успеха без рассмотрения координатных плоскостей. Однако для полноты анализа исследуем матрицу S полностью.
Анализ строк 1, 3, 4, 5 порождает те же результаты. Максимальные косинусы второй строки, соответствующей грани q2, указывают на систему {q2, q3, q8}. Решаем уравнения совместно и проверяем выполнение всех неиспользованных ограничений.
Получаем вершину D(6, 0, 2).
Со строкой, соответствующей q7, начинаются трудности, обусловленные следующими факторами:
Координатная плоскость — возможная, но не действительная грань. Именно нормали к координатным плоскостям образуют угол


Если, не зная, что делать с нулями, упорядочить только косинусы углов между нормалью к q7 (x = 0) и нормалями к граням-границам, то первые три косинуса невозрастающей последовательности укажут на грани {q1, q4, q7}. Однако точка (0, 11, 4) — решение этой системы — не является вершиной многогранника R, так как не удовлетворяет ограничению q6.
Для возможной грани q8, также не обращая внимание на нули, находим систему {q2, q3, q8}, решением которой является вершина D(6, 0, 2). (По-видимому, углы между нормалями не вышли из диапазона [0,

По последней строке, соответствующей возможной грани q9, находим систему {q4, q5, q9}, решением которой является вершина K(10, 10, 0).
(Неслучайность успеха в последних трех случаях нуждается в обосновании.)
Отметим, что нет гарантии получения всех вершин поверхности. Ведь группируя вместе грани, мы отдаем предпочтение вершинам с "пологими" склонами, выбирая максимальные значения косинусов. В частности, мы ни разу здесь не получили вершину F(17, 8, 0), в которой целевая функция принимает максимальное значение. Так что второй этап решения задачи ЛП неизбежен. Более того, необходимо не качественное, а аналитическое доказательство того, что рассмотренным путем при выполнении определенных условий будет получена хотя бы одна вершина многогранника R допустимых решений задачи. То есть необходимо доказать теорему существования.
Оценка сложности
Алгоритм поиска вершины многогранника допустимых решений предполагает ряд этапов.
Определение верхней (нижней) поверхности многогранника. Он заключается в проверке выполнения всех ограничений для точки начала координат. Сложность этого этапа можно оценить как O(nm). Число r граней-границ, образующих одну поверхность, не превышает m - 1,
r

Нахождение матрицы S косинусов углов между нормалями к действительным и возможным граням поверхности. Число таких косинусов для симметричной матрицы с учетом известных углов между осями координат составляет
 |
(6.13) |
Каждый косинус отыскивается в результате скалярного произведения единичных векторов нормалей, имеющего сложность O(6n). С учетом (6.12) можно оценить сложность алгоритма нахождения матрицы S как
O(3m2n + mn2). (6.14)
Выделение n максимальных косинусов в каждой строке матрицы S. Сложность этой операции упорядочения по одной строке можно оценить как
O((m + n)2) (6.15)
Наконец, для выделенных граней необходимо решить систему n линейных уравнений, соответствующих этим граням. Сложность алгоритма такого решения составляет O(n3). Общая сложность выполнения этого этапа для всех строк составляет
O(mn3 + n4). (6.16)
Как видим, сложность нахождения вершины (точнее, всех возможных вершин) полиномиальная. Сумма степеней основных параметров n и m в составе членов полинома не превышает четырех.
В заключение отметим, что наметился общий прием распараллеливания решения задач оптимизации. Это не просто прием распараллеливания вычислений. Он определяет стратегию коллективного поведения компьютеров вычислительной системы или вычислительной сети при совместном решении задачи.
Алгоритм решения задачи предполагает, на разных этапах или глобально, варианты поиска промежуточных или окончательных решений. Компьютеры "расходятся" по отдельным вариантам поиска. Отдельный компьютер может достичь или не достичь успеха, реализуя стратегию "проб и ошибок". Тот компьютер, что достиг успеха, оперативно извещает другие компьютеры, которые прерывают свои действия. Все компьютеры используют успех одного для продолжения выполнения задачи.
Такой прием используется для поиска смежной вершины (по разным ребрам) с "лучшим" значением целевой функции при решении задачи ЛП. Такой же прием может применяться и для нахождения опорного плана решения этой же задачи. Ведь грани верхней (нижней) поверхности многогранника допустимых решений могут распределяться между компьютерами. Компьютер может для взятой на обработку грани найти все косинусы между ее нормалью и нормалями с другими гранями, и здесь не следует бояться повторения счета отдельных косинусов на разных компьютерах. Затем компьютер может выбрать n максимальных косинусов и проверить выделенную таким образом точку. Как только вершина найдена, работа других компьютеров по аналогичному поиску может быть прервана.
Однако возможно, и это должно быть исследовано статистически, что себя оправдает такая стратегия, когда в результате нахождения нескольких вершин в качестве опорного плана будет взято решение, обеспечивающее "лучшее" значение целевой функции.
Все сказанное наилучшим образом согласуется с SPMD-технологией "одна программа — много потоков данных ".
Вместе с тем, отметим, что здесь предлагается "инженерное" решение задачи на основе ее "физического смысла". Работа по обоснованию и строгому доказательству основных положений должна быть продолжена. Скорее всего, мы наблюдаем интересные свойства выпуклого многогранника допустимых решений задачи ЛП, не всегда умея их строго доказать.

Основные предположения
Определение. Назовем плоскость в n-мерном пространстве образующей вершины A выпуклого многогранника R допустимых решений задачи ЛП, если ее уравнение входит в состав системы n линейных уравнений границ многогранника R, решением которой является точка A.
В общем случае каждая вершина многогранника R имеет не менее n образующих плоскостей. Часть из них может совпадать с координатными плоскостями.
Изменим обозначение плоскостей-граней, образующих исследуемую далее верхнюю (нижнюю) поверхность многогранника R:
Qверхн (Qнижн) ={p1, p2,... , pr, pr+1, ... ,pr+n}. (6.7)
Здесь

Сменим обозначение и коэффициентов уравнений плоскостей, выделив совокупность всех граней многогранника R — действительных и возможных, образующих исследуемую (верхнюю или нижнюю) поверхность:
p1 = d11 x1 + d12 x2 +... + d1n xn = 0
p2 = d21 x1 + d22 x2 +... + d2n xn = 0
...
pr = dr1 x1 + dr2 x2 +... + dr n xn = 0 (6.8)
pr+1 = x1 = 0
...
pr+n = xn = 0.
Найдем координаты единичных векторов нормалей Nj, j = 1,... , n+r, к плоскостям (6.8):
 |
(6.9) |
где
 |
(6.10) |
Тогда косинус угла между нормалями к двум граням верхней (нижней) поверхности R вычисляется как результат скалярного произведения единичных векторов нормалей:
 |
(6.11) |
Выскажем гипотезу, которая является основой теоремы существования:
Если плоскости pj и pq совместно не являются образующими какой-либо вершины верхней (нижней) поверхности выпуклого многогранника R допустимых решений задачи ЛП, а их нормали Nj и Nq образуют "угол"

Слово "угол" берем в кавычки в связи с тем, что любой угол измеряется в плоскости и видеть его мы можем в двух- и трехмерном пространстве.
В общем случае n-мерного пространства мы можем судить о величине угла по его косинусу, который отыскивается как результат скалярного произведения единичных векторов.
Отсюда следует, что геометрически мы можем продемонстрировать верность гипотезы в двух- и трехмерном пространстве. В общем же случае доказательство ее справедливости должно быть аналитическим.
Итак, поясним высказанное предположение "плоским" рис. 6.4.

Рис. 6.4. Соотношение углов между нормалями смежных граней
Выделим произвольную вершину A многогранника R. Она "окружена" образующими ее гранями (на плоскости — ребрами). Пусть pj — одна из них. Любая грань, не являющаяся образующей вершины A, например — грань (ребро) pq, добавляет угол излома поверхности в угол наклона ? ее нормали Nq. Точка пересечения pj и pq находится вне R. Тогда должна существовать образующая эту же вершину грань (ребро) pl, нормаль к которой Nl имеет меньший угол наклона, ? <
Представим (рис. 6.5) аналогичную картину в трехмерном пространстве.

Рис. 6.5. Соотношение углов между нормалями в трёхмерном пространстве
Пусть p2 и p3 не являются смежными на данной поверхности многогранника R, то есть не имеют общего ребра и, следовательно, совместно не являются образующими какой-либо вершины. Тогда существует одна или более разделяющих их граней, здесь, например — грань p1, нормаль к которой N1 образует с нормалью N2 угол ? меньший угла
Минуя формальное и строгое доказательство, продолжим пояснение гипотезы на качественном уровне.
Грани p1 и p2 являются образующими двух вершин A и B. Для гарантии смежности этих граней, то есть того, что они совместно являются образующими какой-то вершины, можно в основу выбора такой вершины положить минимальный угол между нормалями к ним. То есть будем считать, что если для фиксированной грани pj найден минимальный из углов между нормалью Nj к этой грани и нормалями ко всем другим граням этой же поверхности, — угол между нормалью Nj и нормалью Nl, то две грани pj и pl совместно являются образующими хотя бы одной вершины этой поверхности.
Чтобы найти третью грань — третье уравнение для нахождения точки в трехмерном пространстве, следует искать такую грань (например, p4 на рис. 6.5), между нормалью к которой и нормалями N1 и N2 углы также меньше тех углов, которые N1 и N2 образуют с нормалями несмежных граней.Такая грань будет смежной и p1, и p2.
Теорема. Пусть p — произвольная грань верхней (нижней) поверхности многогранника R допустимых решений задачи ЛП. Составим неубывающую последовательность углов между нормалью к этой грани и нормалями всех граней этой же поверхности (включая нормаль к этой же грани; этот угол равен нулю). Первые n минимальных отличных от нуля углов этой последовательности указывают на n граней, являющихся образующими некоторой вершины многогранника R.
Доказательство. Пусть среди выделенных таким образом граней есть грань, не являющаяся совместно с другими образующей одной вершины. Тогда, по теореме-гипотезе, существует образующая ту же вершину грань, не параллельная первой и такая, нормаль к которой составляет с нормалью к p угол, меньший, чем выделенный по указанной последовательности. Это противоречит правилу выбора n минимальных углов.
Особенности применения косинуса как функции меры угла
О величине угла в n-мерном пространстве мы можем судить только по его косинусу. Однако косинус не является монотонной функцией и в общем случае может служить мерой угла, если диапазон изменения этого угла не превышает
Составим по (6.11) симметричную матрицу S, включенную в табл. 6.1
косинусов углов между всеми нормалями к граням верхней (нижней) поверхности выпуклого многогранника R.
Таблица 6.1.
ГраньНормальN1 N2... Nr+n| p1 | N1 | 1 | cos(N1,N2) | ... | cos(N1,Nr+n) |
| p2 | N2 | cos (N2,N1) | 1 | ... | cos(N2,Nr+n) |
| ... | ... | ... | ... | ... | ... |
| pr | Nr | cos(Nr,N1) | cos(Nr,N2) | ... | cos(Nr,Nr+n) |
| pr+1 | Nr+1 | cos(Nr+1,N1) | cos(Nr+1,N2) | ... | cos(Nr+1,Nr+n) |
| ... | ... | ... | ... | ... | ... |
| pr+n | Nr+n | cos(Nr+n, N1) | cos(Nr+n,N2) |
... | 1 |
Выберем строку, соответствующую некоторой грани. Для комплектации граней, совместно с выбранной образующих общую вершину, выделим в этой строке n минимальных отличных от 0 и
Поясним выбор последовательности n косинусов.
Выбранная грань может быть параллельна некоторой другой грани или координатной плоскости, т.е. угол между их нормалями может быть равен либо нулю, либо
На рис. 6.6 Qнижн={p1, p2, p3, p4}.

Рис. 6.6. Пример, показывающий, когда грани не могут быть образующими одной вершины
Таблица косинусов углов имеет вид
Таблица 6.2.
ГраньНормальN1 N2N3 N4| p1 | N1 | 1 | 0 | 1 | 0 |
| p2 | N2 | 0 | 1 | 0 | 1 |
| p3 | N3 | 1 | 0 | 1 | 0 |
| p4 | N4 | 0 | 1 | 0 |
Из первой строки, допуская лишь одну единицу cos(N1,N1)=1), находим возможные образующие {p1, p2}. При этом поиск элементов последовательности ведем слева направо. Проверка подтверждает правильность выбора вершины A.
Аналогично, из второй строки находим {p2, p1}, что определяет ту же вершину. Третья строка определяет возможное множество образующих {p3, p2}, что не подтверждается проверкой. Четвертая строка также не определяет правильный выбор образующих {p4, p1}.
Обратим внимание на то, что все вышесказанные предположения и теоремы касаются граней, о которых доподлинно известно, что они входят в состав поверхности многогранника допустимых решений. Важным источником неприятностей являются координатные плоскости. Ведь мы не знаем, являются ли они действительными гранями, и вынуждены относить их к возможным. Отсюда и возможная ошибочность выводов.
На рис. 6.7 Qнижн={p1, p2, p3, p4, p5}.

Рис. 6.7. "Критические" случаи
Таблица косинусов углов имеет вид
Таблица 6.3. ГраньНормальN1 N2N3 N4 N5
| p1 | N1 | 1 | 0 | -1 | -v2/2 | v2/2 |
| p2 | N2 | 0 | 1 | 0 | v2/2 | v2/2 |
| p3 | N3 | -1 | 0 | 1 | v2/2 | -v2/2 |
| p4 | N4 | -v2/2 | v2/2 | v2/2 | 1 | 0 |
| p5 | N5 | v2/2 | v2/2 | -v2/2 | 0 | 1 |
Действительно, по первой строке формируется предполагаемое множество образующих {p1, p4}. Однако пересечение этих прямых не дает искомую вершину. И так — по всем строкам. Если бы было установлено, что ось y не входит в состав поверхности R, то соответствующий косинус можно бы было игнорировать, что привело бы к правильному выбору множества образующих {p1, p2}.
Анализ этого примера наводит на мысль: обязательно ли формировать верхнюю (нижнюю) поверхность до конца, присоединяя координатные плоскости? Ведь количество действительных граней, составляющих ее, достаточно для осуществления поиска вершины. А именно, если в выражении (6.7) r

двух последних строк и столбцов. Легко видеть, что поиск вершины осуществляется успешно.
На рис. 6.8 демонстрируется случай, когда, несмотря на выполнение указанного выше неравенства, к поиску вершины необходимо подключать координатные плоскости.

Рис. 6.8. Необходимость анализа координатных плоскостей
Три плоскости p1, p2, p3 совместно не являются образующими одной вершины. Только включение в рассмотрение плоскостей z = 0 или y = 0 позволяет найти вершины многогранника допустимых решений.
Грань может иметь нормаль, угол которой с нормалями некоторых "далеких" граней превышает

Тогда воспользуемся следующим предположением:
На верхней (нижней) поверхности выпуклого многогранника R существует грань, нормаль к которой составляет с нормалями ко всем другим граням этой поверхности углы, не превышающие
Это — предположение об обязательном существовании некоторых "срединных" граней, нормали к которым близки к середине диапазона изменения таких нормалей, — диапазона

На рис. 6.9 отражена попытка представления некоторых крайних случаев, иллюстрирующих на плоскости существование "срединных" граней для разных выпуклых многогранников.

Рис. 6.9. К существованию углов, не превышающих pi
Так, в многограннике R1 (треугольник) угол между нормалью N1
и другими нормалями не превышает
максимальный угол, например, между нормалью N2 и другими нормалями, составляет
составляет со всеми нормалями угол, меньше
Таким образом, мы предположили существование хотя бы одной грани, при анализе которой с помощью косинусов удается избежать искажений в определении того, в каком отношении находятся углы, которые нормаль к этой грани образует с нормалями к другим граням поверхности. Исключается случай, когда большему углу соответствует и больший косинус. Это приводит к необходимости одновременного параллельного анализа многих граней поверхности в качестве начальных, так как успех может быть достигнут не всегда.
Параллельное решение "плоской" задачи НП
Постановка задачи:
f(x,y)

при ограничениях
g1(x,y)
... gm(x,y)
Могут быть условия x,y
Предположим:
Все ограничения разрешимы относительно всех переменных. Ограничения и, возможно, условия неотрицательности решения образуют область R, ограниченную со всех сторон (рис. 6.2).

Рис. 6.2. "Плоская" нелинейная задача оптимизации с нелинейными ограничениями
Предположим, как на рисунке, m = 4. (Одно ограничение, x-c
Решая попарно все равенства (границы R), полученные по ограничениям, и проверяя точки пересечения на удовлетворение остальным неравенствам-ограничениям, найдём все вершины, в нашем примере — {A, B, C, K}.
Координаты найденных вершин дают начальную информацию (прямоугольник показан пунктиром) о "минимальном" прямоугольнике D, включающем в себя область R. Однако некоторые кривые, ограничивающие R, сопряженные с двумя вершинами, могут, имея экстремум по некоторым координатам между ними, "выходить" из этого прямоугольника. Точки такого выхода надо найти, проверить на принадлежность R, если они существуют, и расширить D.
Для каждого i = 1, ... , m, разрешим gi
относительно x. Получим (возможно, неоднозначную) функцию
x =

Найдем множество экстремумов этой функции, решив уравнение
x' =
Для каждой точки экстремума проверяем, принадлежит ли она области R, т.е. выполняются ли для нее все ограничения. Такой точкой на рисунке является точка E.
Теперь то же самое надо проделать, разрешив все функции gi
относительно y,
y = ? i (x)
Найдем множество экстремумов этой функции, удовлетворяющих всем ограничениям. На рисунке это точки G, F, M, L.
Теперь мы нашли все точки, которые помогут нам очертить прямоугольник D, полностью вмещающий область R — область возможных решений задачи. Границы этого прямоугольника определяются минимальными и максимальными значениями координат всех найденных точек — точек пересечения кривых ограничений и точек экстремумов этих кривых, удовлетворяющих всем ограничениям задачи.
В нашем примере пусть A = (xA, yA), B = (xB, yB) и т.д. Тогда
xD1 = min{xA, xB, xG, xC, xF, xE, xM, xK, xL } = xA = xB,
xD2 = max{xA, xB, xG, xC, xF, xE, xM, xK, xL} = xE ,
yD1 = min{yA, yB, yG, yC, yF, yM, yE, yK, yL} = yK,
yD2 = max{yA, yB, yG, yC, yF, yM, yE, yK, yL} = yG.
Воспользуемся методом "сеток". Покроем область D сеткой с шагом ? x по x и ? y по y. Испытывая каждый узел на принадлежность R, и находя в нем значение f(x, y), выберем максимальное.
Допускается обобщение метода решения для произвольной размерности.
Параллельное решение задач НП при линейных ограничениях
Пусть решается задача
f(x1, ... ,xn)
при ограничениях
g1(x1, ... ,xn)
g2(x1, ... ,xn)
...
gm(x1, ... ,xn)
и при условиях: gi — линейны, xi
Предположим, что гиперплоскости gi, i = 1, ... ,m, возможно, совместно с координатными плоскостями, образуют в n-мерном пространстве выпуклый многогранник R допустимых решений, т.е. область задания функции f.
Определим, как и ранее, все вершины {X1, ... ,Xn}, Xl
=(x1(l) , ... ,xn(l) ), l = 1, ... ,N, этого многогранника в результате решения Cm + nn систем n линейных уравнений на основе всех заданных и возможных его граней

Тогда множество точек X = (x1,x2, ... ,xn) этого многогранника описывается как



а целевая функция на многограннике R становится функцией параметров f(x1, ... ,x_n) = f*(k1, ... ,k_{N-1}).
Т.е., задавая разные значения k1, k2, ... ,k_{N-1} так, чтобы выполнялось условие 0

мы можем организовать перебор всех точек R с некоторым шагом h по всем параметрам. Этим мы накладываем N-мерную "сетку" на многогранник R. В каждой точке-узле этой сетки мы будем находить значение функции f* и выберем максимальное. Шаг h должен быть выбран так, чтобы обеспечить необходимую точность решения задачи.
Распараллеливание возможно на двух этапах решения:
Распределение систем линейных уравнений между процессорами для нахождения всех вершин многогранника допустимых решений. (Эквивалентно прямому перебору при решении задачи линейного программирования.) Распределение между процессорами узлов сетки — точек многогранника допустимых решений для нахождения и анализа в них значений целевой функции.
Метод допускает развитие и совершенствование.
Например, движение в сторону возрастания функции f может быть направленным, определяемым с помощью конечно-разностных значений частных производных по параметрам kl в точке текущего анализа
функции f. Это вариант так называемого градиентного метода. Эти же значения частных производных могут определять переменный шаг h.
Пример (рис. 6.1)
f(x,y)=x2+y
при ограничениях
-x-2y+12
-3x-y+21
и при условии x,y

Рис. 6.1. Нелинейная задача с линейными ограничениями
Решая попарно уравнения границ, находим
Xl=(0,0), X2=(0,6), X3=(6,3), X4=(7,0).
Уравнение многогранника R:

Пусть h — шаг изменения каждого ki для получения испытываемой точки X многогранника R. Будем перебирать точки
k1 = 0, k2 = 0, k3 = 0 (тем самым k4 = 1);
k1 = h, k2 = 0, k3 = 0 (k4 = 1-h);
k1 = h, k2 = h, k3 = 0 (k4 = 1-2h);
k1 = h, k2 = h, k3 = h (k4 = 1-3h);
k1 = 2h, k2 = h, k3 = h (k4 = 1-4h);
...
Однако нам надо следить, чтобы величина k4 = 1 - k1 - k2 - k3
оставалась неотрицательной.
Выполнив такой перебор, например, для h = 0,1, получим max f(x,y) = f*(k1 = 0, k2 = 0, k3 = 0, k4 = 1) = f(7,0) = 49.
Предпосылки метода
Ниже предлагается метод нахождения вершины многогранника допустимых решений задачи линейного программирования для начала процесса параллельного поиска оптимального решения. В основе метода лежит предположение, что для некоторых вершин образующие их грани имеют нормали, которые составляют с каждой из этих нормалей минимальные углы. При обобщении на произвольное пространство обсуждается возможность использования косинусов углов между нормалями в качестве функции меры.
Параллельный алгоритм решения задачи линейного программирования (ЛП) ориентирован на применение SPMD-технологии ("одна программа — много потоков данных"), наиболее эффективной при организации распределенных (в локальной вычислительной сети) и параллельных (в многопроцессорной вычислительной системе) вычислений. Метод базируется на отказе от традиционного ввода свободных переменных. Поиск решения производится непосредственно в n-мерном пространстве, что сохраняет наглядность "физического смысла" задачи.
Суть метода в следующем. Первоначально должна быть известна некоторая вершина многогранника допустимых решений вместе с системой уравнений границ на основе ограничений и возможных границ — координатных плоскостей, которым эта вершина удовлетворяет. Эта вершина определяет начальный или опорный план. Далее с помощью множества процессоров вычислительной системы или рабочих станций вычислительной сети производится одновременное и независимое смещение вдоль ребер, исходящих из вершины, для поиска одной или более вершин с "лучшим" (большим или меньшим, в зависимости от поставленной задачи) значением целевой функции. Процессоры переключаются на новую вершину, и процесс продолжается до решения задачи.
Нетрадиционность этого подхода обусловлена высокой размерностью задачи и необходимостью распараллеливания. Распараллеливание требует, в свою очередь, пересмотра алгоритмов, ранее ориентированных только на сокращение количества операций и не обеспечивающих эффективную, одновременную загрузку оборудования, тем более — локальной вычислительной сети.
В лекции 4 курса "Архитектура параллельных вычислительных систем" даются рекомендации по параллельному нахождению опорного плана на основе прямого перебора. На задачах малой размерности, рассматриваемых в качестве примеров, это вполне допустимо, однако практическая задача размерности n = 36 и с числом ограничений m = 18 привела к недопустимому времени счета. Компьютеры стали бы искать опорный план не один месяц, что связано с экспоненциальной сложностью такого перебора.
Таким образом, необходимо найти "быстрый" параллельный алгоритм нахождения опорного плана.
Здесь можно было бы воспользоваться одним из известных "традиционных" методов. Однако желание максимально использовать "физический смысл" задачи и потому остаться в n-мерном пространстве сулит выявление замечательных свойств выпуклого многогранника допустимых решений, которые скрыты при традиционном абстрагировании.
Принцип внешней точки
Итак, поставлена задача ЛП
Z = c1x1 + c2x2 + ... + cnxn
при ограничениях
q1 = a11x1 + ... + a1nxn
... qm = am1x1 + ... + amnxn
и при условии
x1
Если в ограничениях заменить знак "
Таким образом, грани многогранника R формируются на основе множества m действительных и n возможных границ:
q1 & = a11x1 + ... + a1n xn - b1 = 0
...
qm = am1x1 + ... + amnxn - bm = 0 (6.2)
qm+1 = x1 = 0
...
qm+n = xn = 0.
Здесь обозначение qi используется для названия соответствующих плоскостей и ограничений.
Тогда принципиально возможен выбор комбинаций по n уравнений из (6.2) и их совместное решение. Если решение существует, оно не отрицательно и удовлетворяет всем не использованным при этом ограничениям (6.1), то это решение определяет координаты одной из вершин многогранника R. Однако, как говорилось выше, нет гарантированных оценок времени получения первой вершины, а полный перебор Cnm + n систем n уравнений обладает экспоненциальной сложностью.
Локализуем поиск вершины многогранника R, освободившись от некоторых "лишних" уравнений из (6.2).
Установим направление роста целевой функции, записав ее дифференциал:
dZ = c1dx1 + c2dx2 + ... + cndxn.
Сообщив одинаковое положительное приращение dx всем переменным, получим
dZ = (c1 + c2 + ... + cn )dx.
Следовательно, сумма коэффициентов целевой функции (в отличие от более точной оценки с помощью градиента) определяет направление ее роста: если
 |
(6.3) |
Z растет, удаляясь от начала координат, если
 |
(6.4) |
Z растет, приближаясь к началу координат.
Случай

Выберем точку начала координат O (0, 0, ... , 0). Если все ограничения (6.1) в ней выполняются, эта точка является вершиной многогранника R, и наш поиск хотя бы одной вершины может быть успешно закончен.
В противном случае будем считать эту точку внешней точкой, удобной для рассмотрения многогранника R "со стороны".
А именно, выделим множество

выпуклого многогранника R допустимых решений задачи ЛП. Координатные плоскости включаются в рассмотрение, для того чтобы можно было исследовать вершины R, принадлежащие этим плоскостям.
Аналогично, остальные плоскости (грани), для которых в точке O не выполняются ограничения (6.1), дополненные координатными плоскостями, образуют нижнюю поверхность Qнижн многогранника R.
Очевидно, если сумма коэффициентов целевой функции положительна, то есть Z растет, удаляясь от точки O, то решение задачи ЛП следует искать среди вершин многогранника R на его верхней поверхности. В противном случае — на нижней поверхности.
Проследим на приведенном в лекции 4 курса "Архитектура параллельных вычислительных систем" примере рассматриваемые здесь построения. Для этого повторим постановку и дополним графическую интерпретацию представленной там задачи.
Задача формулировалась следующим образом:
Z = 26x + 20y + 21z
при ограничениях
q1 = 2x + 7y - 76z + 222
q2 = -8x + 9y - 8z + 64
q3 = -8x + 13y - 24z +96
q4 = -x - 6y - z + 70
q5 = -2x - 7y - 2z + 90
q6 = 33x + 3y + 22z - 165
и при условии неотрицательности переменных, о чем в дальнейшем можно не упоминать.
Так как сумма коэффициентов целевой функции положительна, то нас будет интересовать верхняя поверхность многогранника R допустимых решений. При x = y = z = 0 справедливы неравенства для q1
,... , q5. Следовательно,
Qверхн = {q1, q2, q3, q4, q5, q7, q8, q9}. (6.6)
На рис. 6.3 3 ребра верхней поверхности выделены. Координаты точек выбраны при построении примера и приведены для контроля. Считаем их неизвестными; их необходимо получить.

Рис. 6.3. Многогранник допустимых решений с выделенными рёбрами
В данном случае мы получили малый выигрыш, исключив из рассмотрения единственную грань с образуемыми ею вершинами. Однако в произвольном случае форма R может быть разнообразной, и подобное сокращение рассматриваемых ограничений, то есть связанных с ними граней, может быть существенным. Да и сейчас мы видим, что число вершин, среди которых необходим поиск, весьма сократилось — до шести отмеченных на рисунке.
Развитие стратегии решения задачи ЛП
Выделяя на многограннике R допустимых решений верхнюю и нижнюю поверхности, мы на деле не столько стремимся "подобраться" поближе к вершине-решению, сколько стремимся расчленить задачу, локализовать поиск опорного плана. Если мы с помощью указанных косинусов начнем исследовать совместно всю совокупность граней многогранника, то окажемся во власти неразрешимых коллизий. Ни о каком упорядочении углов в этом случае не может быть речи, так как во всем диапазоне [0, 2
Более того, выбранная таким образом поверхность не всегда может привести к успеху.
Например, на рис. 6.6 верхнюю поверхность образуют грань (ребро), противоположная вершине A, и, возможно, координатные плоскости (оси).
Поскольку при анализе этой поверхности другие грани исключены из рассмотрения, то нет системы двух уравнений, результатом решения которой стали бы вершины, образуемые этой гранью. Мы зашли бы в тупик, если бы не позволили себе рассмотреть и другую, нижнюю, поверхность.
Кстати, в нашем примере нижняя поверхность определяется следующим образом:
Qнижн = {q6, q7, q8, q9}.
Составим для нее матрицу S косинусов в составе табл. 6.5.
Таблица 6.5.
ГраньНормаль N6 N7 N8 N9| q6 | N6 | 1 | 0,83 | 0,23 | 0,56 |
| q7 | N7 | 0,83 | 1 | 0 | 0 |
| q8 | N8 | 0,23 | 0 | 1 | 0 |
| q9 | N9 | 0,56 | 0 | 0 | 1 |
В результате анализа первой строки, соответствующей грани q6, находим грани {q6, q7, q9}, возможно, образующие некоторую вершину. В результате решения выделенной системы уравнений получаем точку (0, 55, 0). Эта точка не удовлетворяет ограничениям q4
В результате анализа строки, соответствующей грани q7
(игнорируя нули), находим только грани q6 и q7. Однако для нахождения третьей грани придется все же организовать перебор (именно перебор) нулей. Проверим комбинацию граней {q6, q7, q8}. Их совместное решение определяет точку (0, 75, 0), не удовлетворяющую тем же ограничениям. Комбинация {q6, q7, q9} уже рассматривалась.
Анализ следующей строки приводит к необходимости проверки комбинаций {q6, q7, q8} и {q6, q8, q9}. Первая комбинация уже исследовалась, а вторая приводит к получению точки (5, 0, 0), удовлетворяющей всем ограничениям (точка B на рис. 6.3).
Анализ последней строки приводит к необходимости проверки комбинаций {q6, q7, q9} и {q6, q8, q9}. Обе комбинации уже рассматривались: первая — как неудачная, вторая — повторно образующая вершину.
Легко видеть, что если бы мы не выполняли перебор комбинаций нулей, то так и не получили бы вершину, так как при первой возможной комбинации, обусловленной алгоритмом, она ни разу не обнаружилась.
Отсюда вывод: в общем случае необходимо избегать анализа строк матрицы S, соответствующих координатным плоскостям. Помимо того, что это — лишь возможные, но не действительные грани, углы, образуемые нормалями к ним и нормалями к другим граням, могут превышать
Так, в рассмотренном примере анализа верхней поверхности многогранника R достаточно было исследовать первые пять строк матрицы S ( табл. 6.1), опираясь на предположение о наличии "срединных" граней. Ведь в результате этого анализа вершины были найдены.
Напомним, что, выделяя верхнюю и нижнюю поверхности, мы некоторые вершины делаем недоступными для предлагаемого метода. Это — вершины "на стыке" поверхностей. В данном случае это, например, вершины, образуемые комбинациями {q1, q6, q8}, {q4, q6, q9} и др.
Рассмотренный пример анализа нижней поверхности многогранника R приводит к уточнению алгоритма нахождения опорного плана.
Нули — косинусы углов между осями координат — не всегда удается игнорировать. Это характерно для того случая, когда действительных граней, образующих рассматриваемую поверхность, недостаточно (r < n) или анализ соответствующих им строк матрицы S не приводит к успеху. Тогда приходится анализировать строки, соответствующие координатным плоскостям, "добирая" нулевые значения косинусов до общего количества n таких косинусов. При этом неизбежен перебор всех возможных комбинаций таких нулей.
Можно было бы сделать здесь вывод о том, что при подозрении о таких трудностях немедленно следует приступить к поиску опорного плана на другой поверхности. Однако мы не доказали, что хотя бы одна вершина обязательно будет найдена. Это приводит к необходимой готовности воспользоваться, в случае неудачи, одним из проверенных, традиционных методов нахождения опорного плана решения задачи ЛП, — более сложного и практически не распараллеливаемого.
Граф-схемы параллельных алгоритмов
Представим себе программу решения задачи, которая отображает последовательное изложение алгоритма на машинном языке, ассемблере или ЯВУ. Предположим, что, анализируя эту программу, нам удалось разбить её на отдельные модули и выделить для каждого из них множества входных и выходных данных так, чтобы установить взаимодействие модулей по информации.
Например, программа F представляется как
F = F1(X1 , X2 ; X3 , X4 ) F2 (X2 ; X5 ) F3 (X3 ; X6 ) F4 (X1 , X4 ; X7 ) F5 (X3 , X4 , X5 ; X8 ) F6 (X3 , X4 , X7 ; X9 ) F7 (X5 , X7 ; X10) F8 (X6 , X8 , X9 , X10 ; Y), где точкой с запятой отделены входные данные от выходных, X = {X1, X2} — исходные данные задачи, Y — выходные данные или результат.
Итак, мы разбили заданный алгоритм решения задачи на ряд модулей, операторов, работ и установили информационную взаимосвязь этих работ. Чтобы подчеркнуть общность задач и методов распараллеливания, не ограничивающуюся применением только для ВС, будем пользоваться термином работа.
Для решения задач оптимального выполнения работ многими исполнителями (т.е. процессорами ВС) нам понадобятся временные оценки выполнения как программы в целом, так и каждого выделенного модуля, т.е. каждой работы. Эти оценки могут быть выполнены как экспериментально, так и на основе количества операций и производительности процессоров, предполагаемых к использованию.
Пусть относительно данного алгоритма и предполагаемой ВС нам известны следующие оценки T = {t1, t2, ... , t8}.
Тогда, чтобы отразить прохождение обрабатываемой информации и выявить возможности распараллеливания, представим информационную граф-схему алгоритма или информационный граф G (рис. 7.1). Вершины соответствуют работам. Дуги отражают частичную упорядоченность работ.

Рис. 7.1. Информационный граф алгоритма
А именно, если работа ? использует в качестве входной информации результат выполнения работы
Граф G — взвешенный, ориентированный и не содержит контуров. (Т.к. время выполнения алгоритма конечно, то программные циклы либо погружены внутрь работ, либо развёрнуты.)
Например, представим себе информационный граф, соответствующий скалярному умножению векторов заданной длины: A = B ? C способом "пирамиды", В = {b1 , ... , b8}, C = {c1 , ... , c8}. Схема счёта показана на рис. 7.2.

Рис. 7.2. Схема счёта "пирамидой"
Примем время сложения равным единице. Время умножения пусть превышает время сложения в четыре раза. Информационный граф G, соответствующий счёту способом "пирамиды", представлен на рис. 7.3.

Рис. 7.3. Информационный граф — "пирамида"
Мы рассмотрели составление информационных графов. Можно рассматривать информационно-логические графы, если учитывать альтернативные ветви алгоритмов.
Например, может быть целесообразным следующее разбиение программы (алгоритма) на модули (работы):
F = F1(X1; X2) if A then F2(X2; X3) else F3(X1;X4) F4(X1, X3, X4; Y).
Информационно-логический граф G — на рис. 7.4.

Рис. 7.4. Информационно-логический граф
Преемственность информации (1
Рассмотрение информационно-логических графов сильно усложняет решение задач оптимизации параллельных вычислений. Практически ограничиваются планированием выполнения самой сложной, трудоемкой ветви алгоритма или решают её для разных ветвей отдельно, — т.е. сводят оптимизацию к рассмотрению только информационных графов.
Для формальных исследований информационный граф G представляется матрицей следования S, или, с добавлением столбцов весов, — расширенной матрицей следования S*. При этом, т.к. граф G не содержит контуров (циклов), то S может быть сведена к треугольной "правильным" выбором нумерации вершин. Ниже (рис. 7.5) приведены матрицы S и S* для графа, представленного на рис. 7.1, и для некоторых известных значений весов.

Рис. 7.5. Матрица следования с задающими связями
Определение 1. Назовём все связи по информации, обусловленные исходным видом графа G, задающими связями.
Определение 2.
Путями в графе G будем называть последовательности вершин вида a1, a2 , ... , as такие, что для любой пары соседних вершин ai и ai+1 существует дуга, исходящая из вершины ai и входящая в вершину ai+1.
Будем считать все пути в графе G допустимыми, т.е. реально существующими ветвями отображаемой программы.
Определение 3. Длиной пути в информационном графе G назовём сумму весов вершин, составляющих этот путь.
Определение 4. Путь максимальной длины Tкр в информационном графе G назовём критическим.
В одном графе может быть несколько путей равной длины, являющихся критическими.
Если в графе G есть дуга, исходящая из вершины a и входящая в вершину b, т.е. существует задающая связь a
Определение 5. Множество связей, которые введены направленно внутри всех пар работ, принадлежащих одному пути в графе G и не связанных задающими связями, назовём множеством транзитивных связей.
Транзитивные связи полностью определяются задающими связями.
Алгоритм 1 дополнения треугольной матрицы S транзитивными связями.
Организуем просмотр сверху вниз строк матрицы следования S. В очередной i-й строке организуем просмотр элементов в порядке увеличения j номеров столбцов. Если (i, j)=1, складываем строки i и j по операции дизъюнкции. Если исходная матрица следования S нетреугольная, последовательный просмотр её строк производится неоднократно до установления факта неизменности окончательно полученной матрицы.)
Конец алгоритма.
В представленном выше примере после введения всех транзитивных связей матрица следования S примет вид, представленный на рисунке 7.6)рисунке 7.6 (введённые транзитивные связи выделены курсивом).

Рис. 7.6. Матрица следования с транзитивными связями
С помощью введения транзитивных связей в нетреугольной матрице следования устанавливается наличие контуров в графе G. О наличии контуров свидетельствуют появившиеся ненулевые диагональные элементы, указывающие на связь вида a
Например, пусть задан граф G на рис. 7.7.

Рис. 7.7. Граф алгоритма и матрица следования
После первого шага преобразования S принимает вид, показанный на рис. 7.8.

Рис. 7.8. Первый шаг обнаружения контура
После второго шага преобразования S принимает вид, показанный на рис. 7.9.

Рис. 7.9. Обнаружение контура
Т.к. на главной диагонали матрицы появились единицы, то граф G содержит циклы (контуры). Из рисунка графа виден цикл 2
Определение 6. Работы a и b будем называть взаимно независимыми, если в матрице следования S выполняется условие (a, b) = (b, a) = 0.
Определение 7. Работы {ai}, i = 1, ... , s, образуют полное множество взаимно независимых работ (ПМВНР), если для любой работы j


Например, для графа G, представленного на рис. 7.1, после введения транзитивных связей, что учтено в матрице следования на рис. 7.6, можно установить следующие ПМВНР: {1,2}, {2,3,4}, {3,4,5}, {2,3,6}, {3,5,6,7}, {8}.
Неформальная постановка задач параллельного программирования ВС
Высокая производительность ВС достигается структурными методами, основанными на параллельной обработке информации. ВС содержит несколько процессоров или операционных устройств, способных одновременно, но с необходимой синхронизацией, выполнять доли возлагаемых на них работ по реализации алгоритма решения задачи.
Проблема её программирования — это проблема планирования распараллеливания. Это требует разбиения алгоритма на, в общем случае, частично упорядоченное множество работ, назначения этих работ на процессоры с учетом синхронизации их выполнения в соответствии с обязательным порядком следования.
С ориентацией на достижение максимальной производительности ВС, а также на специальное применение в составе конкретных систем, например, в составе сложных систем управления, различают две взаимно-обратные задачи параллельного программирования.
Задача 1. Для заданного комплекса информационно и по управлению взаимосвязанных задач (частично упорядоченного множества задач), для заданной архитектуры ВС (наличие многих процессоров в однородной ВС, наличие процессоров разной специализации или производительности в неоднородной ВС, наличие или отсутствие ООП и т.д.), а также для заданного ограничения на допустимое время вычислительного процесса, выбрать комплектацию ВС минимальной стоимости.
Под стоимостью понимают вес каждого типа процессоров, который необходимо учитывать при выборе оптимальной комплектации. В частности, это стоимость разработки или цена одного процессора.
В однородной ВС задача 1 вырождается в задачу нахождения минимального числа процессоров, необходимого для решения данного комплекса взаимосвязанных задач за время, не превышающее заданное.
Задача 2. Найти план решения за минимальное время данного комплекса информационно и по управлению взаимосвязанных задач на данной ВС.
Нижняя оценка минимального числа
Алгоритм 5.
Первоначально полагаем n = 0.
Организуем перебор всех отрезков [?1, ?2]

[0, T] в порядке

Всего таких отрезков T(T+1)/2.
Для очередного анализируемого отрезка времени [?1, ?2] находим значение

Если n' > n, выполняем операцию n := n'. После перебора всех отрезков окажется найденным значение n, которое равно максимальному из значений, удовлетворяющих (7.2).
Пример. Нахождение оценки n.
Нахождение

увеличить изображение
Рис. 7.19. Нахождение нижней оценки числа исполнителей
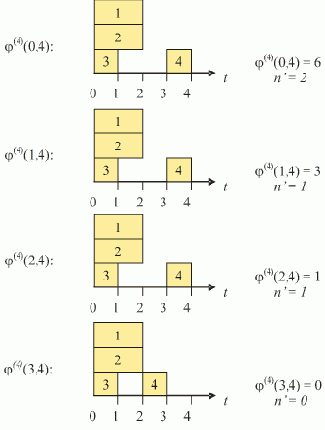
Рис. 7.19. Окончание
В результате анализа всех отрезков находим n = max n' = 2.
Нижняя оценка минимального времени выполнения данного алгоритма на ВС
Алгоритм 6.
Первоначально полагаем

Организуем перебор всех отрезков [?1, ?2]
[0, T] в той же последовательности, что и в предыдущем алгоритме. (В процессе выполнения данного алгоритма значение T может увеличиваться, что при данном порядке перебора не приведёт к усложнению алгоритма.)
Для очередного анализируемого отрезка времени [?1, ?2] находим значение
d =
Если d > 0, выполняем операцию T := T + ] d/n [. Полагаем ?2j(T) := ?2j(T) + ] d/n [ , j = 1 , ... , m.
После перебора всех отрезков [?1, ?2] окажется найденным окончательное значение T — нижняя оценка минимального времени выполнения данного алгоритма на данной ВС.
Пример.
Произведём оценку T для графа G, рассмотренного в предыдущем примере, и ВС, состоящей из двух процессоров, n = 2 (рис. 7.20).

увеличить изображение
Рис. 7.20. Оценка снизу минимального времени выполнения работ

Рис. 7.20. Окончание
Первоначально находим

После перебора всех отрезков, с учётом уточнения оценки времени в процессе этого перебора, окончательно находим T = 4.
Решение задачи 1 распараллеливания для однородных ВС
Формулировка задачи: Для данного алгоритма, которому соответствует информационный граф G, и для времени T, отведённого для его выполнения, найти наименьшее число n процессоров, составляющих однородную ВС, и план выполнения работ на них.
Метод точного решения задачи (метод "ветвей и границ") основан на следующей основной теореме.
Теорема. Для того чтобы значение n являлось наименьшим числом процессоров однородной ВС, которая выполняет алгоритм, представленный информационным графом G = (X, P, Г ), за время, не превышающее заданное значение T, необходимо и достаточно, чтобы n было наименьшим числом, для которого можно построить граф G' = (X, P, Г'), объединив вершины, соответствующие работам каждого ПМВНР, который содержит r > n работ r - n ориентированными дугами в n путей не содержащих общих вершин. При этом длина критического пути в графе G' не должна превышать значение T.
Алгоритм 7 решения задачи 1 — нахождения графа-решения G'
Для графа G и времени T находим значения ранних {?1j} и поздних {?j(T)}, j = 1 , ... , m, сроков окончания выполнения работ. (Если задача поставлена корректно, то

Находим оценку минимального числа n процессоров, которое необходимо для выполнения заданного алгоритма за время, не превышающее T.
Пусть ? — номер шага решения задачи. Полагаем ? = 1.
Находим наименьшее значение t? такое, что
F(?11, ?12 , ... , ?1m, t? ) = r? > n.
Если такого t? нет, то n — решение задачи.
Выделяем множество работ A? = {
?1j? - tj?
т.е. тех работ, которые "порождают" данное значение F. Множество A является подмножеством некоторого ПМВНР.
Предположим, что мы можем упорядочивать комбинации дополнительных связей внутри множества A?. Введём очередную комбинацию r - n связей, как указано в теореме — так, чтобы длина критического пути в изменившемся при этом графе G не превысила T. Если такая комбинация найдена, выполняем операцию ? := ? + 1, уточняем значения {?1j} и {?2j(T)} с учётом введённых связей, переходим к выполнению 4. Если такой комбинации связей не существует, либо все они уже испытаны, выполняем операцию ? := ? - 1. Если ? = 0, т.е.
на первом же шаге сглаживание загрузки процессоров не приводит к подтверждению того, что n — решение, выполняем операцию n := n + 1 и переходим к выполнению 3. Если ?

Конец алгоритма.
Таким образом, суть алгоритма в том, что, реализуя общий подход, который называется метод "ветвей и границ", мы, выбрав начальное расписание, где все работы занимают на оси времени крайнее левое положение, продвигаемся шаг за шагом и находим точки на оси времени, в которых функция плотности загрузки превышает первоначально испытываемое n. Пытаемся сгладить значение этой функции, введя дополнительные связи между работами, допускаемые ограничением T. В случае неудачи вернёмся на шаг назад и попытаемся ввести другую комбинацию связей. При переборе всех комбинаций связей на первом шаге, не приведших к успеху, увеличим предполагаемое число процессоров и начнём процесс сглаживания функции плотности загрузки сначала.
Примечания
Как упорядочить вводимые комбинации связей?
Пусть A? — множество взаимно независимых работ, между которыми нужно ввести r - n связей по условию теоремы, т.е. построить некоторый граф, связывающий вершины A?. Построим матрицу следования L?, соответствующую этому графу. Первоначально эта матрица — нулевая. Вводим r? - n единиц так, чтобы:
граф, соответствующий получаемой при этом матрице, не содержал контуров (отсюда, в частности, следует, что диагональные элементы всегда должны быть нулевыми); в каждой строке и в каждом столбце матрицы не должно содержаться больше одной единицы (следует из Теоремы о возможных путях, не содержащих общих работ).
Перемещая последнюю единицу сначала по строке, затем по столбцам, затем перейдя к предпоследней единице и т.д., осуществляем перебор всех возможных комбинаций связей между работами множества A?.
Можно рекомендовать следующий способ сокращения перебора: введение дополнительных связей в пункте 6 алгоритма производить не только по критерию допустимого увеличения длины критического пути, но и по значениям функции минимальной загрузки отрезка.
А именно, вводя очередную комбинацию связей на ?-м шаге сглаживания функции плотности загрузки, не приводящую к увеличению длины критического пути сверх заданного T, необходимо вновь пересчитать значение функции
(Напомним, что метод "ветвей и границ", как метод перебора, обладает экспоненциальной сложностью, является NP-трудным. Поэтому сокращение перебора — очень важная задача.)
Пример.
Найдём минимальное число n процессоров, необходимое для выполнения алгоритма, который представлен графом G на рисунке 7.21а, за время T = 7.

Рис. 7.21. Последовательные действия при точном решении задачи 1
По алгоритму 4 найдёем нижнюю оценку n = 2, исследовав 28 значений
= ?14 = 2, ?15 = ?16 = 4, ?17 = 5, ?21(7) = ?22(7) = 4, ?23 (7) = ?24(7) = ?26 (7) = 6, ?25(7) = ?27 = 7. Мы не собираемся впредь иллюстрировать нахождение функции минимальной загрузки, поэтому не будем приводить динамически уточняемые значения поздних сроков окончания выполнения работ.
F(?11 , ... , ?17) = 4 > 2, т.е. t1 = 0. В формировании этого значения участвуют работы 1, 2, 3, 4. Составим квадратную матрицу L1 (рис. 7.21в) с первоначально нулевыми элементами. Постараемся последовательно ввести в неё два единичных элемента. Первая возможная комбинация двух таких элементов соответствует связям 3
1 также приводит к недопустимому увеличению длины критического пути. Единичные элементы, соответствующие отвергнутым связям, на рисунке зачёркнуты.
Вновь меняем вторую связь, полагая равным единице первый элемент третьей строки матрицы L1. Новая комбинация связей 2
Найдём t2 = 3 такое, что F(3, 2, 5, 2, 6, 5, 6, 3) = 3 > 2. Данное значение функции плотности загрузки определяется выполнением работ 3, 5, 6. Составляем матрицу L2 (рис. 7.21д) и стараемся ввести в ней единственный единичный элемент. Однако перебор всех возможных способов введения такого элемента приводит к длине критического пути в образующемся графе, превышающей 7. Возвращаемся на шаг назад к анализу матрицы L1 и пробуем ввести другую допустимую комбинацию связей. Такой комбинацией является 2
представлена диаграмма выполнения алгоритма при уточнённых ранних сроках окончания выполнения работ ?11 = 3, ?12 = ?14 = 2 ?13 = 4, ?15 = ?17 = 6, ?16 = 5
Вновь находим значение t2 = 3 такое, что F(3, 2, 4, 2, 6, 5, 6, 3) = 3 > 2. (Совпадение значений t2 и выделенных работ с ранее исследованными является скорее случайным.) Вновь формируем матрицу L2 (индекс указывает номер шага, новая матрица L2 в общем случае ничем не схожа с аналогичной ранее рассмотренной матрицей), и находим первую из допустимых связей — связь 6
3 (рис. 7.21ж).
Вновь (рис. 7.21з) находим значение t3 = 5, где плотность загрузки превышает значение 2. Составляем матрицу L3 (рис. 7.21и). Находим в ней единственную единицу, соответствующую допустимой связи 5
Собственно расписание определяется найденными на последнем шаге значениями {?1j} .
Решение задачи 2 распараллеливания для однородных ВС
Формулировка задачи: Для данного алгоритма, которому соответствует информационный граф G, найти минимальное время T и план выполнения этого алгоритма на данной однородной ВС, содержащей n процессоров.
Теорема. Для того, чтобы T было минимальным временем выполнения алгоритма, представленного информационным графом G = (X, P, Г), на однородной ВС, состоящей из n процессоров, необходимо и достаточно, чтобы T было наименьшей из возможных длин критических путей в графах вида G'= (X, P, Г'), что получены из данного объединением вершин, соответствующих работам каждого ПМВНР, который содержит r > n работ, r - n ориентированными дугами в n путей, не содержащих общих вершин.

Рис. 7.22. Информационный граф распараллеливаемой задачи
Алгоритм 8 решения задачи 2 — нахождения графа-решения G'
По алгоритму 5 находим оценку T = T0 минимального времени выполнения данного алгоритма на ВС, содержащей n процессоров. Опыт подсказывает, что в подавляющем большинстве случаев полученная оценка совпадает с минимальным временем выполнения алгоритма на данной ВС. Чтобы сократить объём вычислений, целесообразно с помощью алгоритма 6 решения задачи 1 установить, способны ли n процессоров выполнить данный алгоритм за время T0. Если T0 — не решение задачи 2, используем следующий метод. Полагаем ? = ? = 1, T? = ?, где ? — заведомо большое число, например, максимально допустимое на используемой ЭВМ.
Находим наименьшее значение t? такое, что F(?11 , ... , ?1m, t?) = r? > n.
Если такого значения t? нет на первом же шаге сглаживания плотности загрузки (при ? = 1), то значение Tкр — решение задачи 2. Если такого значения больше нет при ? > 1, то увеличиваем значение ? на единицу и полагаем T? = max {?11
, ... , ?1m} , т.е. длине критического пути в графе G', построенном в соответствии с условиями теоремы. Не меняя значение ?, переходим к выполнению 6. (Если T? = T0 + 1, то т.к. T0 — не решение задачи, искать значение T < T? нецелесообразно, т.е. найденное значение T? — решение задачи 2).
Если значение t?, обеспечивающее неравенство в пункте 4, найдено, выделяем множество работ A? = {
?1j? - tj?
Множество A? является подмножеством некоторого ПМВНР.
Введём очередную, ещё не испытанную комбинацию r? - n связей, как указано в теореме, так, чтобы длина критического пути в полученном при этом графе G' была меньше T?. Если такая комбинация связей существует, увеличиваем ? на единицу, уточняем новые значения {?1j} , j = 1 , ... , m, переходим к выполнению 4. Если такой комбинации связей не существует или все они уже перебраны и при этом ? > 1, уменьшаем ? на единицу и переходим к 6. Если же испытаны все комбинации связей при ? = 1, то последнее значение T? определяет искомое T = T?.
Конец алгоритма.
Пример.
Пусть заданы 6 задач (m = 6), заданы их частичная упорядоченность графом G, заданы времена решения (веса вершин). Требуется найти расписание выполнения этих задач на двух процессорах (n = 2) — такое, чтобы время решений этих задач было минимальным.
Найдём нижнюю оценку длины расписания T.
Первоначально полагаем

По алгоритму 6, испытывая значения функции минимальной загрузки, найдём, что


Без учета реально доступного количества процессоров составим (рис. 7.23) временную диаграмму решения всей совокупности задач — такую, при которой каждая из задач решается как можно раньше, и определим загрузку как бы неограниченного числа процессоров:

Рис. 7.23. Временная диаграмма решения задач
находим первый момент времени, при котором по этой диаграмме нам требуется более двух процессоров: при t=1 это количество F(1)=3. Выделим образующие это значение F задачи: {2, 3, 4} и составим матрицу L1 (рис. 7.24а). Первой испытываемой связью является связь 3

Рис. 7.24. Первый шаг распределения: а — матрица следования, б — временная диаграмма
Т.к. больше нет значений функции плотности загрузки, превышающих 2, то мы предполагаем возможное решение, но продолжаем перебор связей для поиска более короткого расписания.
следующей испытываемой связью по матрице L1, определяющей длину критического пути, меньшую 8, является связь 4

Рис. 7.25. Введение новой связи: а — матрица следования, б — временная диаграмма
вновь находим первый момент времени, при котором нам требуется более двух процессоров: при t = 2 это количество F(2) = 3. Выделим образующие это значение F задачи: {2, 3, 6} и составим матрицу L2 (рис. 7.26а). Первой возможной связью, не приводящей к длине критического пути, равной 8 или выше, является связь 2

Рис. 7.26. Введение последней связи: а — матрица следования, б — окончательный вид временной диаграммы
Т.к. значение функции плотности загрузки больше не превышает значение 2, то мы нашли оптимальное расписание, ибо его длина не превосходит нижней оценки — значения 7.
Задачи точного распараллеливания в настоящей лекции освещаются только для однородных систем исполнителей, когда все такие исполнители "умеют" всё и каждую работу выполняют за одинаковое время. Это предполагает применение методов для однородных вычислительных систем. Однако при более широком применении методов распараллеливания в управлении и экономике актуальна постановка этих задач для неоднородного состава исполнителей, в частности — когда исполнители обладают разной специализацией. Достаточно рассмотреть управление строительством или уборочной кампанией. Алгоритмы точного решения задач распараллеливания для неоднородных систем представлены в [3].
Временные оценки на информационных графах
Информационный граф отображает порядок следования работ. Тогда очевидно, что момент окончания выполнения любой работы (если началом отсчёта времени является момент начала выполнения работ — начало выполнения алгоритма) не может быть меньше максимальной из длин всех путей, которые заканчиваются вершиной, соответствующей этой работе.
Таким образом, для каждой i = 1 , ... , m работы алгоритма, представленного информационным графом, можно найти ранний срок ?1i окончания её выполнения. Если же выполнение алгоритма ограничено временем T < Tкр, то для каждой работы можно найти и поздний срок ?2i(T) окончания её выполнения. Окончание выполнения i-й работы позже этого срока приводит к тому, что выполнение других работ, следующих за данной, не может быть закончено до истечения времени T. Иначе говоря, поздний срок окончания выполнения данной работы не может превышать разности между значением T и максимальной из длин путей, в первую вершину которых входит дуга, что исходит из вершины, соответствующей данной работе. Без задания значения T (ограничения на длительность вычислительного процесса) определение позднего срока окончания выполнения работы не имеет смысла.
При T = Tкр ранние сроки окончания выполнения работ, составляющих критические пути, совпадают с поздними сроками окончания их выполнения.
Прежде чем рассмотреть алгоритм нахождения ранних и поздних сроков окончания выполнения работ по расширенной матрице следования S*, отметим, что учёт транзитивных связей увеличивает число необходимых действий. Так как граф G не содержит контуров, то матрица следования S может быть преобразована в треугольную. Однако при построении алгоритмов решения задач распараллеливания не представляется удобным преобразовывать матрицу следования. Поэтому будем считать, что в общем случае матрица S не треугольная.
Алгоритм 2 нахождения ранних сроков окончания выполнения работ.
Полагаем первоначально ?11 = ?12 = ... = ?1m
= 0. Производя циклический обзор строк матрицы S, находим очередную из необработанных строк.
Если все строки обработаны, выполнение алгоритма заканчивается. Пусть j — номер найденной необработанной строки. Если j-я строка не содержит единичных элементов, полагаем ?1j = tj. Переходим к выполнению шага 6. Если j-я строка содержит единичные элементы, выбираем элементы множества {?11 , ... , ?1m}, соответствующие номерам единичных элементов j-й строки.
Если все выбранные таким образом элементы, образующие множество {?1j(?)}, ? = 1, ... , kj, отличны от нуля, полагаем ?1j = max ?1 j? + tj.
Если хотя бы один из выбранных элементов нулевой (соответствующий ранний срок ещё не найден), выполняем шаг 2.
Обработанную j-ю строку метим, чтобы исключить её повторную обработку. Переходим к выполнению шага 2.
Примечание. Если граф G не содержит контуров, зацикливание при этом невозможно.
Конец алгоритма.
Если матрица S треугольная, то никогда не складываются условия для многократного циклического обзора строк. Тогда ранние сроки окончания выполнения работ находятся за один последовательный просмотр строк матрицы S.
Очевидно, что Tкр = max {?11 , ... , ?1m}.
По матрице S* ( S — треугольная) на рис. 7.5 (граф G — на рис. 7.1) находим
?11 = t1 = 2, ?12 = t2 = 3, ?13 = ?11 + t3
=3, ?14
= ?11 + t4 = 4, ?15 = max {?11, ?12 + t5= 7, ?16 = max {?11, ?14} + t6 = 8, ?17 = max {?12,?14 } + t7 = 6, ?18 = max {?13, ?15, ?16, ?17} + t8 = 9; Tкр = 9.
Чтобы рассмотреть пример с нетреугольной матрицей следования, выберем граф G без контуров с "неправильно" пронумерованными вершинами (рис. 7.10).

Рис. 7.10. Информационный граф с не треугольной матрицей следования
После обработки первой строки ?11 = 1. Попытка обработать вторую строку неудачна, т.к. ?13 и ?14 ещё не найдены. После обработки третьей строки ?13 = ?11 + t3 = 3. Обработка четвёртой строки даёт ?14 = 2. После обработки пятой строки ?15 = ?13 + t5 = 4. Попытка обработки шестой строки неудачна, т.к. не найдено значение ?12. Приступаем к следующему циклу обзора необработанных строк S. Обрабатываем вторую строку: ?12 = max {?13, ?14} + t2 = 6.
После обработки шестой строки ?16 = ?12 + t6 = 7. Tкр = 7.
Для удобства представления наряду с другими способами будем пользоваться наглядными диаграммами выполнения работ при заданных значениях времени начала или окончания их выполнения. Работы обозначаются прямоугольниками с постоянной высотой и длиной, равной времени выполнения. Стрелки, связывающие прямоугольники-работы, соответствуют дугам в графе G. На рис. 7.11 представлена диаграмма выполнения работ, отраженных графом G на рис. 7.1 и расширенной матрицей следования на рис. 7.5 — при ранних сроках выполнения работ.

Рис. 7.11. Временная диаграмма выполнения работ при ранних сроках окончания
Алгоритм 3 нахождения поздних сроков окончания выполнения работ при заданном значенииТ.
Полагаем первоначально ?21(T) = ... = ?2m(T) = 0. Производя циклический обзор справа налево столбцов матрицы S, находим очередной из не обработанных ещё столбцов. Если все столбцы обработаны, выполнение алгоритма заканчивается. Пусть j — номер найденного необработанного столбца. Если j-й столбец не содержит единичных элементов, полагаем ?2j(T) = T. Переходим к выполнению шага 6. Если j-й столбец содержит единичные элементы, выбираем элементы множества { ?21(T) , ... ,?2m(T) }, соответствующие номерам единичных элементов j-го столбца.
Если все выбранные таким образом элементы {?2j?}(T)}

?2j (T) = min {?2j? (T) - tj? }.
В противном случае выполняем шаг 2.
Обработанный j-й столбец метим с целью исключения его повторной обработки. Переходим к выполнению шага 2.
Конец алгоритма.
Если матрица S — треугольная, то поздние сроки окончания выполнения работ находятся за один просмотр столбцов.
Для матрицы S* (матрица S — треугольная) на рис. 7.5 и для T = 10 за один просмотр находим
?28(10) = 10, ?27(10) = ?28(10) - t8 = 9, ?26(10) = ?28(10)- t8 = 9, ?25(10) = ?28(10) - t8 = 9 , ?24 = min {?26(10), - t6, ?27(10) - t7} = 5, ?23(10) = ?28(10) - t8 = 9, ?22(10) = min {?25(10) - t5, ?27(10) - t7 } = 5, ?21(10) = min {?23(10) - t3, ?24(10) - t4, ?25(10) - t5, ?26(10) - t6} = 3.
Для нетреугольной матрицы S на рис. 7.10 при T = 10 находим ?26(10) = ?25(10) = 10. Обработка четвёртого столбца откладывается, т.к. не найдено значение ?22(10). По этой же причине не обрабатывается третий столбец. После обработки второго столбца находим ?22(10) = ?26(10) - t6 = 9.
Обработка первого столбца невозможна, т.к. ещё не найдено значение ?23(10). Продолжаем циклический обзор столбцов. После обработки четвёертого столбца получаем ?24(10) = ?22(10) - t2 = 6. Обработка третьего столбца даёт ?23(10) = min {?22(10) - t2, ?25(10) - t5} = 6. После обработки первого столбца находим ?21(10) = ?23(10) - t3 = 4.
Диаграммы выполнения работ при поздних сроках окончания, по графам на рис. 7.1 и 7.10, при T = 10 представлены на рис. 7.12 — (а) и (б), соответственно. (Стрелки, соответствующие дугам в графах, опущены в связи с их избыточностью.)

Рис. 7.12. Диаграммы выполнения работ при поздних сроках окончания: а — для графа на рис. 7.1,б — для графа на рис. 7.10
Пусть ?j — произвольное значение момента окончания выполнения j-й работы, j =1 , ... , m,
?1j
Меняя значения {?j}, j = 1 , ... ,m, но соблюдая при этом порядок следования работ, мы получим множество допустимых расписаний выполнения работ.
Нашей конечной целью является выбор таких расписаний, которые позволяют решить задачи 1 и 2.
Определение 7. Функцию

назовём плотностью загрузки, найденной для значений ?1 , ... , ?m.
Для заданных ?1 , ... , ?m значение функции F в каждый момент времени t совпадает с числом одновременно (параллельно) выполняющихся в этот момент работ.
Например, по диаграмме на 7.11, т.е. для ?1 = ?11, ?2 = ?12, ... , ?8 = ?18, функция F(2, 3, 3, 4, 7, 8, 6, 9, t) имеет вид, представленный на рис. 7.13а. Для допустимого расписания, определяемого набором значений ?1 = 2, ?2 = 4, ?3 = 3, ?4 = 4, ?5 = 8, ?6 = 9, ?7 = 7, ?8 = 10, функция F(2, 4, 3, 4, 8, 9, 7, 10, t) имеет вид, представленный на рис. 7.13б.

Рис. 7.13. Графики функции: а — для ранних сроков окончания работ,,б — для некоторого допустимого расписания
Для графического представления функции F удобно пользоваться временной диаграммой, которая для второго случая, например, имеет вид, представленный на рисунке 7.14..

Рис. 7.14. Временная диаграмма функции F
Пусть данный граф G, в котором учтены транзитивные связи, образует l полных множеств взаимно независимых работ (ПМВНР). (Каждая пара таких множеств может иметь непустое пересечение.) Обозначим ri, i = 1 , ... , l, число работ, образующих i-е полное множество и найдём
R = max {r1 , ... , rl}.
Тогда

т.к. возможно и такое распределение выполняемых работ во времени, задаваемое набором ?1 , ... , ?m, (т.е. допустимое расписание), когда на каком-то отрезке времени выполняются все работы, составляющие ПМВНР с числом R работ.
Например, для графа на рис. 7.1 мы нашли ПМВНР {3,5,6,7}, включающее четыре работы. Тогда существует допустимое расписание, например, ?1 = 2, ?2 = 3, ?3 = 5, ?4 = 4, ?5 = 8, ?6 = 8, ?7 = 6, ?8 = 9 такое, при котором максимальное значение плотности загрузки F равно четырём (рис. 7.15).

Рис. 7.15. Максимальное значение плотности загрузки
Таким образом, справедливо утверждение
Лемма. Минимальное число n процессоров одинаковой специализации и производительности (т.е. в однородной ВС), способных выполнить данный алгоритм за время T
Определение 8. Функцию

назовём загрузкой отрезка [?1, ?2]
Функция Ф определяет объём работ (суммарное время их выполнения) на фиксированном отрезке их выполнения при заданном допустимом расписании.
Так, для отрезка времени [0, 4]
Ф = 10 и т.д.
Определение 9. Функцию

назовём минимальной загрузкой отрезка [?1, ?2]
Функция определяет минимально возможный объём работ, который при данном T и при различных допустимых значениях (расписаниях) ?1 , ... , ?m
должен быть выполнен на отрезке времени [?1, ?2]
мы не выбрали, объём работ, выполняемых на отрезке времени [?1, ?2], не может быть меньше значения
Теорема 1. Для того чтобы T было наименьшим временем выполнения данного алгоритма однородной вычислительной системой, состоящей из n процессоров, либо чтобы n процессоров было достаточно для выполнения данного алгоритма за время T, необходимо, чтобы для данного отрезка времени [?1, ?2]
 | (7.1) |
Доказательство. Нетрудно видеть, что если при данном наборе ?1 , ... , ?m — сроках окончания выполнения работ, в том числе и при таком наборе, при котором обеспечивается минимальное или заданное T = max {?1
, ... , ?m}, для реализации алгоритма достаточно n процессоров, то

Отсюда, для любого отрезка времени [?1, ?2]

что и требовалось доказать.
Необходимость, но не достаточность условия (7.1) покажем на примере. Пусть алгоритму соответствует граф G на рис. 7.16а. Пусть T=3, и одна из возможных диаграмм выполнения алгоритма — на рис. 7.16б.

Рис. 7.16. Пример: минимальная плотность загрузки не соответствует действительной: а — информационный граф, б — временная диаграмма загрузки
Оценим на основе (7.1) число n процессоров, достаточное для выполнения алгоритма в указанное время. Из (7.1) имеем общее соотношение
 | (7.2) |
 | (7.3) |
Находим минимальное n = 2, удовлетворяющие (7.3). Однако из рисунка видно, что не существует плана выполнения работ на двух процессорах за время T=3. Минимально достаточное число процессоров здесь n = 3.
Функция
Предварительно определим функцию

Тогда значение ?(?1j - ?1) характеризует условный объём части работы j на отрезке времени [?1, ?2] при условии ?1j
- tj
Значение ? (?2 - ?2j(T) + tj) характеризует аналогичный объём работы j при максимальном смещении времени выполнения работы j вправо. Это соответствует, например, ситуации, изображённой на рис. 7.17б.

Рис. 7.17. Нахождение минимальной плотности загрузки отрезка: все различные случаи соотношения времени выполнения работ и сроков
Если для работы j оба указанных выше значения функции ? отличны от нуля, но не превышают значение tj и ?2 - ?1, то максимально разгрузить отрезок [?1, ?2] от работы j можно смещением времени его выполнения в сторону, обеспечивающую меньшее из двух указанных выше значений ? (рис. 7.17в).
Существуют два случая, когда работа j не может быть хотя бы частично смещена с отрезка [?1, ?2] :
а) ?1
?2, в этом случае очевидно, что tj
(рис. 7.17г), и объём работы j, выполняемой на отрезке, совпадает с объёмом tj всей этой работы;
б) ?1j
(рис. 7.17д), и объём части работы j, выполняемой на отрезке [?1, ?2] совпадает со значением ?2 - ?1.
Приведённый ниже алгоритм объединяет все возможные указанные выше случаи.
Алгоритм 4 нахождения значения функции
1. Предполагаем, что для каждой работы j = 1, ... , m, известны значения tj, ?1j, ?2j(T). Полагаем равным нулю значение переменной
2. Организуем последовательный анализ работ j = 1, ... , m.
3. Для каждой работы j полагаем
После перебора всех работ
Конец алгоритма.
Выше было получено соотношение (7.2) , которое можно использовать для нижней оценки количества n процессоров, необходимых для выполнения данного алгоритма за время, не превышающее T.
Приведём аналогичное соотношение для нижней оценки минимального времени Т.
Теорема 2. Пусть заданный алгоритм выполняется на ВС, состоящей из n процессоров, и T* — текущее значение оценки снизу времени выполнения алгоритма. Пусть на отрезке времени [?1, ?2]
Тогда минимальное время T выполнения алгоритма удовлетворяет соотношению
 | (7.4) |
Теоремы 1 и 2 на основе анализа такой локальной характеристики параллельного алгоритма, как значение функции
числа n процессоров при заданном ограничении на длительность T процесса; минимального времени T, необходимого для реализации данного алгоритма при заданном числе n процессоров.

Рис. 7.18. К примеру нахождения нижней оценки числа исполнителей
Централизованное диспетчирование
В более сложном виде задача диспетчирования возникает в централизованных ВС. В чем она заключается?
Пусть некоторый супервизор, например, в системе реального времени, определил множество информационно взаимосвязанных задач (частично — упорядоченное множество задач), которые должны решаться циклически, а возможно, и единственный раз процессорами ВС. Известны временные оценки решения задач.
Пусть задан взвешенный ориентированный граф, не содержащий контуров, отражающий частичную упорядоченность работ (задач, процессов, макроинструкций, процедур, операторов и т.д.), которая обусловлена их информационной преемственностью (рис. 8.3).

Рис. 8.3. Информационный граф и расширенная матрица следования
Показана соответствующая ему матрица следования S и расширенная матрица следования S*, содержащая и столбец весов.
Универсальным критерием, используемым при решении задачи диспетчирования как задачи распараллеливания, является минимум времени выполнения совокупности работ, распределяемых между процессорами.
Формально: пусть задано множество работ A = {

Задачей диспетчера является распределение работ

Далее будут изложены достаточно простые диспетчеры на основе эвристических методов решения задачи оптимального распараллеливания — задачи высокой сложности. Такие алгоритмы используют достаточно эффективные решающие правила, приближающие расписания к оптимальным.
Децентрализованное диспетчирование в многоканальном и многоциклическом режиме
Рассмотрим схему организации параллельного вычислительного процесса в реальном времени.
Система управления обслуживает в многоканальном режиме ряд однотипных объектов. Одновременно обслуживаемые объекты могут находиться на разных стадиях обслуживания. По каждому объекту циклически и в разных комбинациях решаются задачи из некоторого заранее установленного множества информационно взаимосвязанных задач. Частичная упорядоченность задач задается расширенной матрицей следования S*.
Рассмотрим случай, когда задачи решаются в цикле одной длительности.
Супервизор формирует матрицу S', которая отражает множество решаемых задач по всем объектам (или по всем занятым каналам обслуживания), обслуживаемым в данное время, и список или очередь Q, содержащий информацию о решаемых задачах (рис. 8.4).

Рис. 8.4. Информация для одноциклического режима обслуживания
(Для этого из матрицы S* для каждого объекта исключаются строки и столбцы, соответствующие нерешаемым задачам, и блочно-диагональным наращиванием строится S'.)
Каждая задача характеризуется именем, номером i канала или объекта, по которому она решается, относительным приоритетом p, значением t времени решения, контрольным временем t0, по истечении которого следует сделать вывод об аварийной ситуации.
При обращении процессора к очереди, назначение очередной задачи на процессор производится на основе анализа S*. Из множества задач, которым соответствуют нулевые строки этой матрицы, выбирается еще не назначенная задача с максимальным приоритетом (минимальное значение p) из тех, которые по времени выполнения укладываются в ресурс процессора в цикле (см. далее). Если таких задач с одинаковым приоритетом несколько, из них выбирается задача с максимальным временем выполнения. Назначенная задача отмечается, чтобы исключить повторное назначение.
После решения любой задачи и исключения информации о ней из S* могут оказаться "открытыми" задачи, обладающие более высоким приоритетом, чем некоторые из тех, которые уже решаются.
В этом случае возможен один из вариантов, когда диспетчер того процессора, на котором закончилось решение некоторой задачи, после назначения (себе) очередной задачи производит попытку дополнительного назначения другим процессорам. Находится готовая к решению задача с максимальным приоритетом и для него — с максимальным временем t. Процессоры последовательно опрашиваются. По опросу прерывается работа того процессора, который решает задачу с приоритетом меньшим, чем приоритет найденной задачи, и с текущим ресурсом времени в цикле
Попытка дополнительного назначения производится до тех пор, пока не будут исчерпаны все задачи, готовые к решению (входы S*, соответствующие еще не назначенным задачам), или пока не будет закончен однократный опрос всех процессоров.
Циклическая работа процессоров организуется с помощью прерывания от системы синхронизации (таймера или СЕВ). В этом случае восстанавливается исходный вид матрицы S* и очередь Q. Процесс решения задач повторяется, если супервизор не внес коррективы в их состав.
Многоциклический режим. Пусть часть задач решается в цикле длительности k1
При составлении комплексного задания объединяют его части, относящиеся к циклам одинаковой длительности. Каждая часть заканчивается признаком "конец задания для kj
После этого диспетчеры производят дополнительное назначение в соответствии с готовыми к решению более приоритетными задачами, т.е. начинают новый цикл по возможности с более приоритетных задач.

Рис. 8.5. Многоциклический режим параллельного решения задач
Выбор процессором новой задачи, как говорилось выше, производится с учетом того ресурса времени, которым обладает данный процессор до момента обязательного окончания решения данной задачи. Должна учитываться необходимость прерывания решения этой задачи ради задач с более высоким приоритетом, т.е. ради задач, решаемых в циклах меньшей длительности.
Как же считается и учитывается этот ресурс? Рассмотрим его как переменный ресурс времени Rij, которым располагает i-й процессор, i = 1, ... , n, в цикле длительности kj
Пусть первоначально, до назначения на процессор задач i-й процессор в цикле длительности k1
— ресурсом Ri2 = k2
Запишем оператор определения нового значения вычислительного ресурса в цикле длительности kj

Здесь ресурс оценивается приближенно, без учета дискретности работ, соразмерности длительности циклов и неточности определения t
Таким образом, прежде чем производить назначение другой задачи,?, решаемой в цикле длительности kj ?, на i-й процессор, необходимо проверить, располагает ли он ресурсом Rij
Это и было отражено выше при рассмотрении назначения в одно- и многоциклическом режиме решения задач.
Классификация
ВС делятся на централизованные и децентрализованные. Это связано с реализованными в них способами управления, или диспетчирования.
Централизованное диспетчирование (ему соответствует централизованная ВС) реализуется управляющим процессором или периодически включаемой в состав очереди задачей наивысшего приоритета. При централизованном диспетчировании существует возможность более полного охвата и прогнозирования состояния всех средств ВС и тщательного выбора плана дальнейшей загрузки процессоров.
Децентрализованное диспетчирование (ему соответствуют децентрализованные ВС) предусматривает возможность самостоятельного обращения каждого процессора к общей очереди для выбора заданий. Обращение к очереди происходит по мере освобождения процессора или по прерыванию. Учет ресурсов всей ВС и оценка в связи с этим различных вариантов назначения отсутствуют. Полностью реализуется виртуальность процессоров. Сокращаются затраты времени (полезной производительности) на диспетчирование, но не используются методы оптимального планирования совместной работы процессоров. Децентрализованное диспетчирование обеспечивает высокую надежность, живучесть ВС. Однако полностью независимой работы процессоров добиться нельзя хотя бы по причине необходимости контроля и реконфигурации ВС при отказе ее модулей, а также в связи с необходимостью возврата заданий в очередь с отказавших процессоров для их перезапуска.
Таким образом, в чистом виде децентрализованное диспетчирование не применяется.
Комбинированное диспетчирование в ВС с очередью
Рассмотрим более детально, применительно к сложным системам обработки информации или к АСУ, как организуется параллельный процесс в таких системах. При этом мы увидим, что в реальных системах принципы централизованного и децентрализованного управления причудливо переплетаются. Будем ориентироваться на ВС с очередью, обеспечивающей виртуализацию вычислительного ресурса (процессоров), что характерно для семейства "Эльбрус". Такие ВС в значительной степени обеспечивают децентрализованное диспетчирование.
Итак, специально организованная программа, выступающая как самостоятельно, так и во взаимодействии с другими подобными программами, как указывалось выше, соответствует некоторому процессу. Если данный процесс прерывается, то текущее состояние стека процессора, который его выполнял, а также состояние ряда регистров необходимо запомнить. Поставим в соответствие состояние стека процессора, выполняющего данный процесс, в том числе то состояние, которое предшествует выполнению (если процесс только сформирован, но еще не начал выполняться), этому процессу, дополнив его состоянием необходимых регистров. Иными словами, введем понятие стека процесса, которым обладает каждый процесс, о чем говорилось выше. Стек процесса может переходить из пассивного состояния в активное и обратно. Отсюда — понятия активного и пассивного стека процесса. Активный стек связан с оборудованием или "наложен" на оборудование и, следовательно, находится в состоянии изменения. Пассивный стек — это "моментальный снимок", временной срез прерванного (или не начавшегося, или кончившегося) процесса, ждущего дальнейшего выполнения (или уничтожения).
Таким образом, стек процесса отражает текущее состояние процессора, выполняющего данный процесс. Стек процесса можно запомнить на момент прерывания, и хранимой в нем информации при обратном "наложении" на оборудование — на любой свободный процессор достаточно для продолжения выполнения этого процесса. Ранее рассматривалась структура пассивного стека процесса.
Стек процессора обладает активным оборудованием, на которое налагается стек процесса для его активизации (рис. 8.6), т.е. для выполнения процесса.
Рис. 8.6. Комбинированное диспетчирование в ВС с очередью
Следовательно, рассматривая абстрактно стеки процессов, можно говорить о закреплении за ними ресурсов (процессоров) для их активизации. При этом исключается необходимость привязки к конкретным стекам процессоров. Реализуется виртуальный вычислительный ресурс.
Ранее говорилось, что информационной основой работы процессоров ВС является очередь процессов "к процессору", которую составляют пассивные стеки процессов. Из очереди процессов процессоры выбирают задания по мере окончания выполнения принятых ранее или при необходимости их прерывания. Очередь процессов может формироваться на основе любого числа элементов процессов. Естественно, при реализации это число приходится ограничивать. В соответствии с готовностью к выполнению и выполнением различают три состояния процессов: активен, т.е. стек данного процесса находится на стеке одного из процессоров и, следовательно, этот процесс выполняется; готов к выполнению, т.е. данный процесс не выполняется только из-за отсутствия свободного процессора; ждет, т.е. процесс не может выполняться, пока не произойдет некоторое событие, обусловленное приоритетом или информационной взаимосвязью процессов. В частности, если в ВС реализован механизм семафоров, регулирующий частичную упорядоченность процессов, то процесс может находиться в состоянии ожидания открытия семафора ("висеть" на семафоре).
Очередь процессов формируется в виде списка, где готовые к выполнению процессы выстраиваются по приоритетам. Каждый процесс, еще не выполнявшийся или прерванный, представлен своим стеком. Ждущие процессы, по мере выполнения условий задержки (например, открытия семафоров), занимают место в соответствии со значением приоритета (или вырабатываемым значением приоритета) в очереди процессов. Процессор выбирает процесс из головы очереди.
В каждом элементе очереди хранится указатель на очередной элемент. Благодаря этим указателям очередь сплетается в нужном порядке.
Исследуя динамическое управление составом очереди и порядком следования в ней процессов, можно организовать различные способы работы ВС. Например, можно периодически подставлять в очередь процессы, реализующие процедуры контроля состояния средств ВС, опроса терминальных устройств, работ по организации памяти, уничтожения процессов и т.д. Возможны различные альтернативные способы влияния на состав очереди. Способ постановки в очередь особенно оправдан при низких требованиях к точности определения момента инициализации работ. Если такие требования высоки, то на помощь приходит механизм прерываний.
На рис. 8.7 отражен текущий вид очереди, а также те связи (штриховыми линиями), которые возникнут, если откроются семафоры A и B выполняемыми на процессорах процессами.

Рис. 8.7. Учёт приоритета задач в очереди
Приоритеты процессов могут периодически изменяться, если это необходимо. Например, система может повышать приоритет тех процессов, у которых достаточно частый обмен информацией с внешним полем. Это увеличивает эффективность мультипрограммной обработки, т.к. прерывание для обменов все равно потребует включения в решение других задач, а окончание обменов позволит вернуться к решению прерванных.
Для повышения надежности и универсальности используемых ресурсов стеки процессоров могут быть нежестко закреплены за процессорами (см. идею решающих полей!). В стеке процессора в основном концентрируются устройства памяти процессоров, основные регистры, над которыми производятся операции. Операционные устройства могут быть отделены от собственно процессора и рассматриваться отдельно. Собственно процессором остается устройство управления, ведающее обработкой потока инструкций, их назначением для выполнения. Это допускает перекоммутацию (показана штриховой линией на рис. 8.8) связи процессор-стек процессора в случае отказов процессоров, т.к.
стек отказавшего процессора соответствует пассивному стеку некоторого процесса. При этом может быть учтен приоритет решаемых процессорами задач.

Рис. 8.8. ВС с управляющими процессором и стеком
Для оперативного продолжения одними процессорами работ, выполнение которых уже начато на других процессорах, целесообразно, чтобы стеки процессоров составляли общую память, доступную всем процессорам. В то же время, эти стеки должны быть в разных блоках этой памяти, что должно допускать одновременное обращение, т.е. должны быть минимизированы взаимные помехи при работе процессоров. Связь с закрепленными за ними стеками процессоры могут осуществлять с помощью специально выделенных базовых регистров, адреса которых различимы для специальных команд, ведающих коммутацией, и неразличимы для процессоров: часть адреса такого регистра является общей для всех процессоров.
В частности, возможна следующая процедура продолжения работы ВС в случае отказа или отключения одного из процессоров.
Прерывается работа головного процессора. Запускается на нем процедура анализа активных процессов.
Данная процедура находит среди всех активных стеков стек выполняемого процесса с минимальным приоритетом. При этом возможны два случая:
процесс из стека отказавшего процессора оказывается в числе процессов с минимальным приоритетом, тогда этот процесс переводится в очередь процессов; минимальным приоритетом обладает активный процесс, не выполнявшийся на стеке отказавшего процессора. Тогда изменяется содержимое базового регистра выполнявшего этот процесс процессора для подключения его к стеку отказавшего процессора, стек прерванного процесса становится пассивным и переводится в очередь.
Т.к. внутри системы накапливаются разнообразные функции управления (режимами прохождения задач, ресурсами, обеспечением надежности), то слежение за работой ВС должно осуществляться с устойчивым периодом. Одним из вариантов такого устойчивого вмешательства управляющих средств является не только назначение одного из процессоров управляющим, но и формирование в системе специального управляющего стека процессора (рис. 8.8).
После прерывания управляющего процессора с частотой, с которой производится анализ состояния системы, осуществляется коммутация этого процессора с управляющим стеком процессора, чтобы избежать работы стандартной процедуры переключения на новый вид работ, которая может быть значительно более трудоемкой. В управляющем стеке процессора работы по управлению могут быть всегда подготовлены (в результате предыдущего включения) к продолжению с момента переключения на них управляющего процессора.
Элемент же децентрализованного управления ВС может осуществляться с помощью периодического включения в состав очереди управляющего процесса, объединяющего ряд процедур управления. При каждом включении этого процесса подготавливается его следующее включение вновь. С таким процессом может быть связан семафор C, открытие которого может производиться по достижении таймером некоторого значения времени T = t + ?, где t — время настоящей активации управляющего процесса; ? — период его активации (период или такт управления). Тогда управляющий процесс должен начинаться с процедуры ЖДАТЬ (С,Т) и включать в себя процедуру ЗАКРЫТЬ (С).
Очевидно, что такое решение не обеспечивает оперативной и синхронной работы средств ВС и чревато возможностью отказа ВС без выхода на процедуры управления. Поэтому подстановку управляющих процессов в очередь все же целесообразно поручить управляющему процессору (считая, что им может быть один из процессоров ВС, решающий и основные задачи из очереди). На рис. 8.9 это — управляющие процессы УП1 и УП2. Но это, как говорилось ранее, — когда отсутствуют жесткие требования к моменту принятия решения.

Рис. 8.9. Два управляющих процесса в очереди
Управляющий процессор реагирует на сигналы прерывания, поступающие в жестком временном режиме — с периодом ?. По поступлении на управляющий процессор сигнала прерывания может быть произведена его перекоммутация на управляющий стек процессора или подстановка в очередь необходимого управляющего процесса. В этом случае обработка управляющих процессов производится так же, как и других процессов, теми процессорами, которые их выбрали для выполнения в соответствии с виртуализацией вычислительного ресурса.
Подводя итог анализу способов организации управления вычислительным процессом в ВС, можно выделить три возможности:
1) управление через очередь, при котором управляющий процесс периодически подставляется в очередь и реализуется процессором, выбравшим его в соответствии с дисциплиной обслуживания очереди. Такой способ управления приемлем, например, для таких работ, как реорганизация памяти, оценка состояния средств и др.;2) выполнение одним из процессоров функции головного или управляющего. Его работа по обслуживанию очереди периодически прерывается для выполнения функций управления ВС;3) наличие в системе специального управляющего процессора (иногда называемого ХОСТ-процессором), в силу назначения и исполнения не участвующего в обслуживании очереди. В многопроцессорных ВС, совмещающих различные режимы обработки информации и нуждающихся в сложном планировании использования ресурсов, целесообразно включение в состав ВС специализированных управляющих процессоров.
Общая схема параллельных вычислений при обслуживании потока заявок (в АСУ)
Рассмотрим схему организации параллельного вычислительного процесса, характерную для автоматических или автоматизированных систем управления (рис. 8.1).

Рис. 8.1. Схема параллельного вычислительного процесса
Общий алгоритм функционирования АСУ в виде макропрограммы отображен блоком 1.
Каждая макроинструкция может заключать большой объем работ. Это — отдельные операторы, задачи (функциональные модули), задания, процессы и др. Макропрограмма либо содержит макроинструкции, которые соответствуют логическим операторам, влияющим на выбор ее ветви, либо имеет специальный блок управления. В результате выполнения этих операторов формируется (блок 2) поток макроинструкций (очередь), подлежащих выполнению процессорами. При этом могут учитываться значения логических переменных, как рассчитанные по макропрограмме (внутреннее управление), так и выработанные на основе внешнего воздействия: управляемым объектом, параметрами управляемого технологического процесса, оператором с пульта или терминала. Т.е. на этом уровне вырабатывается непосредственно поток заданий.
Затем (блок 3) формируется некоторая интерпретация потока заданий (макроинструкций) для диспетчера.
Блоки 2 и 3 могут входить в состав супервизора, определяющего необходимые действия системы управления в процессе ее функционирования.
Диспетчер 4 распределяет работы между процессорами 5 — производит распараллеливание. При этом естественно используется обратная связь от процессоров с сообщениями о ходе выполнения назначенных макроинструкций. Макроинструкции, поступившие на процессор в результате распараллеливания, выполняются в режиме интерпретации - запускаются соответствующие заранее загруженные, т.е. известные всем процессорам, программы (процессы).
Особенности параллельного вычислительного процесса в системе реального времени
Работа АСУ в системе реального времени характеризуется жесткой временной привязкой приема и выдачи информации, поскольку речь идет об управлении некоторыми объектами (например, движением летательных аппаратов) или технологическими процессами.
В целом АСУ реального времени на основе использования ВС является многоканальной системой массового обслуживания, поскольку, как правило, управление производится сразу большим числом объектов (множеством летательных аппаратов, множеством вырабатываемых изделий и т.д.). Общая схема организации вычислительного процесса та же, что и выше.
Однако, чтобы нагляднее подвести к проблемам построения управляемого параллельного вычислительного процесса, рассмотрим, как решаются задачи в реальном времени.
Возьмем возможную временную диаграмму (рис. 8.2).

Рис. 8.2. Схема параллельных вычислений в реальном времени
Пусть ВС состоит из двух процессоров. Общий алгоритм управления разбивается на частные задачи, решаемые в циклах двух длительностей
Примечание. О многоциклическом режиме решения задач в АСУ.
Предположим, мы управляем каким-то "быстрым" объектом или процессом. Нам надо с большой частотой выдавать управляющие воздействия. Они вырабатываются (на некотором временном интервале) по одним и тем же алгоритмам, т.е. циклически решаются одни и те же задачи. Их решение привязывается к сигналам прерывания, которые выдаются с одной и той же частотой. Но могут решаться периодически и другие задачи, для точности результатов которых достаточна более низкая частота: задачи оценки состояния среды, меняющейся плавно, задачи отображения и т.д. Таким образом, в целом в системе одновременно циклически решаются много задач, но в циклах разной длительности.
В общем случае решаемые задачи информационно взаимозависимы.
Строго говоря, они взаимозависимы и по управлению, т.е. от результатов решения одних задач может зависеть и состав далее решаемых задач. Мы будем считать, что состав задач определен на протяжении значительного времени функционирования. Более того, состав решаемых задач определяет супервизор, и внутри одного цикла (или такта) управления этот состав не меняется. Информационная зависимость отображается взвешенным информационным графом, как представлено в примере.
Процессор передачи данных ППД для каждого цикла управления в последовательности, показанной на диаграмме, производит опережающий прием исходной информации в память ВС и последующую выдачу результатов вычислений на объекты управления. Разная толщина стрелок показывает, что объем обмена различен для циклов разной длительности.
Из диаграммы видно, что в момент начала цикла длительности
(отмечен светлым). В результате его работы возможна смена состава решаемых задач. Если в системе есть и диспетчер, его работа может быть учтена увеличением времени работы супервизора.
Предполагают, что задачи, решаемые в каждом цикле меньшей длительности (
Загрузка процессоров ВС может быть организована по правилам мультипрограммной обработки с учетом частичной упорядоченности задач и их относительного приоритета.
Процессор 1 сначала выбирает для решения задачу 1. Из готовых к решению задач процессор 2 может выбрать лишь задачу 6. После решения задачи 1 появляется возможность решения высокоприоритетных задач 2 и 3. Задача 2 выбирается процессором 1, а процессор 2 прерывает задачу 6 и приступает к решению задачи 3. (Неизбежен циклический анализ очереди на появление задач, приоритет которых выше приоритета решаемых задач.) После решения задачи 3 начинается решение задачи 5, а после решения задачи 2, с учетом того, что к этому моменту решена и задача 3, начинается решение задачи 4.
После окончания решения задачи 5 продолжается решение задачи 6, затем начинается решение задач 7 и 8. Однако их решение прерывается началом выполнения следующего цикла длительности
Из примера видно, что частичная упорядоченность задач (задан обязательный порядок следования некоторых задач, обусловленный информационной преемственностью) препятствует полной загрузке процессоров, несмотря на высокие требования к использованию всех вычислительных ресурсов. Она определяет основную трудность решения задач оптимального распараллеливания.
Распараллеливание в МВК. Семафоры
Распараллеливание для полного использования ресурсов МВК осуществляется двумя путями:
на основе естественного существования независимых задач пользователей; на основе существования сложных программных систем, которые состоят из взаимосвязанных процессов, допускающих параллельное выполнение.
Синхронизация информационно взаимосвязанных процессов производится с помощью механизма семафоров.
Пусть существует множество величин - примитивов синхронизации, имеющих тип "семафор" и принимающих в простейшем случае два значения: "открыт" и "закрыт". (В другой версии семафор — счетчик; закрытию соответствует его увеличение на единицу, а открытию — уменьшение на единицу.)
В состав ОС входит ряд процедур, которые обеспечиваются аппаратными средствами и отражаются на входном языке, т.е. доступны пользователю. Минимально необходимый набор таких процедур:
ОБЪЯВИТЬ (С) — объявляется список семафоров C, выделяется память и задается тип переменной при трансляции.
ЗАКРЫТЬ (С) — присваивает семафорам, перечисленным в списке C, значение "закрыт".
ЖДАТЬ (С) — в случае, если в C указаны семафоры со значением "закрыт", прерывает выполняемый процесс. Стек процесса условно дополняет очереди к закрытым семафорам, перечисленным в списке C. Таким образом, если с данной процедуры начинается выполнение некоторой работы, то оно будет поставлено в зависимость от условий выполнения каких-то других работ. Концом выполнения процедуры является переход к анализу очереди процессов для последующей загрузки процессора.
ОТКРЫТЬ (С) — семафорам, указанным в списке C, присваивается значение "открыт" и процессоры из очередей к данным семафорам переводятся в очередь для продолжения их выполнения.
Очередь процессов, конечно, одна, но в ней процессы, "зависшие" на семафорах, соответствующим образом помечаются.
Пусть параллельная программа имеет структуру, представленную на рис. 8.11
информационно-логическим графом (тонкие стрелки — связи по информации, толстые — по управлению).
Обозначение процедуры выше вершины с номером процесса означает, что процесс начинается с нее. Если процедура изображена ниже вершины, значит, процесс заканчивается ее выполнением. Штриховой линией отмечен возможный переход на повторное решение задачи.
Рис. 8.11. Синхронизация распараллеливания с помощью семафоров
Выше рассмотрен механизм семафоров для информационно взаимосвязанных или взаимодействующих процессов. Однако семафоры применяются и для синхронизации обращений к общим данным и другим общим ресурсам. Рассмотрим вариант, применяемый в МВК "Эльбрус-2".
Участок программы, использующий (считывающий или модифицирующий) общие для нескольких процессов данные, называется критическим блоком(иногда — критической секцией).
Для синхронизации (соблюдения последовательности) обращения к общим данным семафоры сопровождают массивы данных и указываются в их дескрипторах. В семафоре предусмотрено поле, в котором указано, сколько процессов пользуются в данный момент этим массивом. Очередной процесс перед считыванием из массива увеличивает на единицу значение этого поля, а при выходе из критического блока уменьшает его на единицу. Ненулевое значение поля означает, что семафор "закрыт по считыванию".
Процесс, который должен модифицировать общие данные — этот же массив, — "закрывает семафор по записи", засылая в него соответствующий признак. Попытка закрыть по записи уже закрытый семафор приводит к прерыванию, конфликт разрешает ОС. После модификации общих данных процесс "открывает" семафор.
Таким образом, семафор состоит из двух частей. В одной части содержится счетчик для закрытия по считыванию, в другой — признак (двоичная переменная) для закрытия по записи.
Указанных операций достаточно для решения различных задач синхронизации при использовании общих ресурсов.
Реализация конвейера на симметричной ВС
В СССР существовал опыт построения ВС конвейерного типа на основе систем типа MIMD. Такая система ("Украина"), названная рекурсивной машиной, разрабатывалась под руководством В.М. Глушкова в ИК АН УССР. Этот опыт уже тогда продемонстрировал общность принципа симметричных ВС, хотя направленность разработки на параллельное выполнение циклов типа "пересчет", по нашему мнению, раскрыта не полностью.
Представим себе систему управления в реальном времени, где заявки на обслуживание поступают с максимальной частотой, определяющей минимальную длительность цикла управления (такт) T, по истечении которого на один из объектов должно быть послано управляющее воздействие.
Пусть, однако, длительность решения задач управления одним объектом в несколько раз превосходит значение T, а характер решаемых задач не допускает их распараллеливания.
Тогда единственным способом привлечения многих процессоров для совместного эффективного решения задач, т.е. для организации распараллеливания, является организация обслуживания заявок на конвейере.
Пусть обслуживание одной заявки разбито на n (по числу процессоров) этапов, по возможности — одинаковой длительности. Максимальную из таких длительностей, не превосходящую темпа поступления заявок на обслуживание, примем за такт обслуживания и работы системы. Каждому этапу соответствует программа или программный комплекс. Процессоры ВС специализируются по этапам обслуживания, т.е. каждый из них выполняет какой-то один этап обслуживания заявок.
Свяжем теперь процессоры ВС в один конвейер, на первую станцию которого будем подавать заявки на обслуживание с максимальной частотой, обусловленной тактом, а с последней станции будем снимать результаты обработки информации — с той же частотой (рис. 8.12).

Рис. 8.12. Организация конвейера
В этом режиме возможны некоторые издержки, связанные с тем, что при постановке задачи организации управляющей системы может возникнуть требование немедленной, не более чем через такт, выдачи результата реакции системы. В данном же случае обработка одной заявки требует n тактов, т.е. задержка составляет n-1 тактов. Но если обработка одной заявки не распараллеливается, то либо нужны кардинальные изменения алгоритмов управления, либо необходимо ждать существенного прогресса в развитии вычислительной техники.
Некоторый выход из положения виден в том случае, когда в рассмотренном режиме производится управление одним объектом. Тогда на основе "физики" процесса может быть справедливым предположение, что каждый результат обработки информации, полученный в i+n-1 -м такте, на основе некоторой пролонгации соответствует данным, как бы полученным не в i-м, а в i+n-2 -м такте. Т.е. необходимо исследовать возможность пролонгации "устаревших" результатов на тот такт, в котором они получены. Такой пролонгацией на последней станции конвейера должен заканчиваться последний этап обработки заявки.
Технология data flow на уровне процедур и процессов в симметричной ВС
"Идеальные" модели data flow (системы, управляемые потоком данных, потоковые ВС) не нашли практического воплощения. Вместе с тем, каждый разработчик, реализовавший при распараллеливании какой-то метод синхронизации частично упорядоченного множества работ, которое представляет собой любая программа или программный комплекс, утверждает, что он создал архитектуру data flow. Это традиционно увеличивает престиж разработки.
Следуя все же изначальной идее, мы под принципом data flow будем понимать такой способ синхронизации параллельного вычислительного процесса, когда отдельные составляющие его работы — программные модули, процессы, процедуры, инструкции, команды — имеют возможность распознавания и заявления о наличии всех данных для своего выполнения. Исполнительные устройства также имеют возможность распознавать работы, для которых существуют все необходимые наборы исходных данных, и выбирать эти работы для выполнения. После выполнения они влияют на состав исходных данных других работ, пополняя их. Все это способствует синхронизированному, осмысленному процессу, максимальной загрузке оборудования, автоматическому использованию всех возможностей реализуемых алгоритмов по распараллеливанию.
Принцип data flow также можно использовать на двух уровнях распараллеливания вычислительного процесса.
Рассмотрим возможность его воплощения на симметричных ВС с помощью механизма синхронизации "почтовых ящиков" (рис. 8.13).

Рис. 8.13. Схема data flow с помощью "почтовых ящиков"
Процессы могут быть причудливо связаны между собой, обмениваясь через "почтовые ящики". Однако следует не допускать "зацикливания", т.е. информационный граф, соответствующий этой структуре и описывающий частичную упорядоченность работ, не должен содержать контуров.
Итак, мы уже изобразили очередь заданий "к процессору", которая может быть дополнена на основе механизма приоритетов, дополнительными средствами синхронизации с помощью семафоров — для реализации замысла пользователя при построении специализированных систем, а также возможностью "порождать" и "убивать" процессы.
Отметим также, что целесообразно совмещать принцип data flow с принципом децентрализованных ВС. Это вновь оказывается совместимым с основной идеологией семейства "Эльбрус".
Управление процессами в МВК семейства "Эльбрус"
Специально организованная программа, выступающая как самостоятельно, так и во взаимодействии с другими подобными программами, на которые разбита задача, соответствует некоторому процессу. Структуризация программы — разбиение на процессы — может быть предусмотрена заранее, статически. Но возможна и динамическая структуризация. Она основана на том, что процесс может "порождать" другие процессы (процессы-"сыновья") или "убивать" их.
Если выполняемый на процессоре процесс прерывается, то текущее состояние стека процессора, на котором он выполняется, а также состояние некоторых регистров, можно рассматривать, как стек процесса. Он может переходить из активного состояния в пассивное и обратно. Активный стек "наложен" на оборудование и, следовательно, находится в состоянии изменения. Пассивный стек — это "фотография" в области ОП прерванного (или не начавшегося) процесса, ждущего дальнейшего выполнения.
Стек пассивного процесса (рис. 8.10) состоит из шапки и активной области.

Рис. 8.10. Стек активного процесса
В шапке хранится информация о данном процессе; есть место для хранения содержимого регистров выполнявшего его процессора в момент прерывания для возможности дальнейшего продолжения выполнения процесса. Активная область полностью совпадает с состоянием стека процессора в момент прерывания.
Рассматривая абстрактно стеки процессов, можно говорить о закреплении за ними ресурсов для их активизации. При этом исключается необходимость привязки к конкретным стекам процессоров. Процессоры выступают в роли ресурса для активизации стеков процессов. В этом выражается идея виртуальных процессоров.
Информационной основой работы процессоров МВК является очередь процессов (" к процессору " ), которую составляют указатели на пассивные стеки процессов. Очередь упорядочена по приоритетам. Из очереди процессоры выбирают задания (процессы) по мере окончания выполнения принятых ранее или при их прерывании. В очереди есть и так называемые "ждущие" процессы, которые по мере выполнения условий задержки (например, открытия семафоров) занимают место в соответствии со значением приоритета.
В каждом элементе очереди хранится указатель на следующий элемент, т.е. очередь представляет списковую структуру. Свободный процессор выбирает процесс из "головы" очереди.
ОС может динамически менять приоритеты в режиме мультипрограммного выполнения с разделением времени (в интерактивном режиме). При этом, в частности, реализуется многоочередная дисциплина квантованного обслуживания.
Каждой задаче доступна математическая память размером 232
слов, разбитая на страницы по 512 слов. При выполнении процессов одной задачи в порядке поступления заявок в физической памяти каждой математической странице выделяется сегмент, соответствующий реальному размеру заявки (физических страниц не существует!). При переполнении ОП ОС пересылает часть физических сегментов во внешнюю память (барабаны, диски) и возвращает их по мере необходимости.