Что это?
ILM расшифровывается как «Управление жизненным циклом информации» (Information Lifecycle Management). Надо сказать, сам термин зарождался не как маркетинговый слоган — это была достаточно здоровая идея управления хранилищами данных. То есть упрощенная идеология ILM состоит в том, чтобы перемещать менее востребованные документы на менее скоростные носители, а после, возможно, и на ленточные библиотеки, если вам нужно хранить архив документации. Или, говоря другими словами, ILM — это состояние, когда администратор любыми средствами (вручную или автоматически) организует продуманную миграцию различных типов информации между несколькими носителями.
Можно сказать, что в сети реализована концепция ILM, даже если системный администратор просто раз в месяц переписывает почтовые базы данных пользователей на ленту. Если пользователь хранит на локальном диске текущие проекты, а старые записывает в сжатом формате на общем сервере, это тоже своего рода ILM. Как вы видите, понятие ILM очень размыто и, оперируя им, можно подразумевать совершенно разные вещи.
Поставщики систем хранения, как правило, под системами ILM понимают использование собственных продуктов, реализующих усовершенствованный документооборот. То есть, переводя работу отдела или компании на систему, например, Documentum от компании EMC, вы получите тщательную автоматизированную реализацию ILM (конечно, применительно к оборудованию EMC). Тогда в самой системе документооборота можно будет производить настройки архивации, миграции данных и применять политики использования систем хранения. Безусловно, все документы, используемые в рамках Documentum, будут со временем автоматически перемещаться с одного носителя на другой, достигая в итоге ленточной библиотеки или исчезая в небытие, что зависит лишь от политик, указанных администратором. Что касается остальных файлов, здесь вопрос спорный — при специфической настройке тоже можно добиться их миграции с одного носителя на другой, но выглядеть этот процесс будет несколько иначе.
Подобную концепцию реализует компания StorageTek. В данном случае мы имеем дело с виртуализацией дискового пространства. В рамках этой концепции для всех сетевых пользователей существует один сетевой диск, который содержит несколько систем хранения разных классов, между которыми организуется миграция файлов. Кстати говоря, для определения политик миграции администратору придется немало потрудиться, определяя различные профили для типов данных и пользователей. Впрочем, при наличии виртуального ресурса в продуктах таких компаний, как EMC, StorageTek и некоторых других крупных поставщиков систем хранения с поддержкой ILM, наиболее эффективным будет совместное использование самих систем хранения с какой-либо системой документооборота. Вместе с тем она должна передавать данные системе хранения, чтобы последняя начинала миграцию тех или иных файлов согласно политикам системы документооборота.
ILM: еще одна дорогая игрушка?
Андрей Шуклин
"Экспресс Электроника"
Многие производители жестких дисков продвигают сегодня концепцию ILM, предлагая реализовать ее практически на любом оборудовании. Однако в презентациях вендоров никогда не заходит речь о том, что будет представлять собой ILM, если отбросить все рекламные уловки.
Рынок накопителей довольно интересен, главной тенденцией происходящего на нем может считаться массовое использование жестких дисков в бытовой технике. Это касается разнообразных устройств, начиная с миниатюрных аудиоплееров и заканчивая встраиваемыми системами для автомобилей. И хотя до сих пор основную прибыль приносят продажи дисков для компьютерных систем, все большая доля рынка приходится именно на бытовые устройства. Поставки дисков для индустриальных систем продолжают расти, по оценкам TrendFOCUS, за 2005 год было поставлено на 11% больше жестких дисков для больших предприятий, чем за 2004 год, но в то же время удельная цена системы хранения снижается.
Производители систем хранения оказались в ситуации, когда они поставляют все больше емкостей, но прибыль при этом не растет, а в некоторых случаях даже снижается. Вполне логично начать продавать с системами хранения нечто, способное увеличить их ценность, а значит, и стоимость. В результате многими производителями была взята на вооружение концепция ILM.
Надо отдать должное маркетингу компаний — сегодня термин ILM действительно на слуху, правда, зачастую потребители не знают о нем ничего, кроме «ILM — это современный подход к построению систем хранения данных» и «ILM позволяет оптимизировать затраты на системы хранения». Конечно, в условиях, когда IT-отделу нужно просто освоить выделенный бюджет, таких данных более чем достаточно, чтобы начать внедрение системы, но если разбираться в реальной потребности компании в подобных инструментах, масштабности их применения и отличиях ILM от разных производителей, необходимо серьезно задуматься: что же представляет собой эта новомодная концепция?
Кому это нужно?
Таким образом, система класса ILM будет полезной только для тех компаний, которые уже задумались о структуризации сети, начали регламентировать права доступа пользователей к сетевым ресурсам. То есть концепция ILM — для тех, кто наводит порядок в сети и стремится привести инфраструктуру к приемлемому виду, чтобы можно было разобраться, где хранятся те или иные отчеты или документы.
Сколько это стоит?
Но следует понимать, что ILM — это не просто красивая идея, а, в случае ее практической реализации, серьезный интеграционный проект, который включает упорядочивание систем хранения, создание единых политик для всех пользователей сети, настройку сетевых хранилищ и внедрение системы электронного документооборота. Все это не только занимает большое количество времени, но и требует серьезных вложений, размер которых варьирует в зависимости от поставщика и комплектации системы.
Концепция ILM может быть реализована и собственными силами IT-отдела, особенно если он достаточно большой и насчитывает несколько серьезных специалистов. Цена проекта, как правило, становится ниже (равно как и качество), а время внедрения увеличивается.
В Россию с любовью
Никто не говорит, что организация автоматической миграции данных в рамках корпоративной системы хранения — это плохо. Напротив! Это очень хорошо, в значительной степени оптимизирует затраты на содержание хранилища данных и позволяет навести порядок в системе хранения. Однако правомерно сказанное только для больших компаний. Плюс ко всему реализация концепции ILM «с нуля» и до полной автоматизации процессов требует дополнительных изменений, средств и времени.
Таким образом, если в компании уже используются система хранения EMC, единое виртуальное дисковое пространство и программная среда Documentum, то внедрение ILM действительно становится лишь вопросом установки нескольких «галочек» в консоли управления и прописывания политик миграции данных. В остальных случаях от компании требуется целая последовательность действий, включающая как организационные, так и инфраструктурные изменения.
Но далеко не все российские компании готовы к внедрению ILM. В нашей стране не столь критичны требования к условиям хранения данных, и не всегда в компании имеются ленточные библиотеки. Кроме этого, не каждая компания готова к внедрению системы документооборота, поскольку не способна внятно регламентировать критерии, по которым нужно производить миграцию данных. И в конце концов, при внедрении какого-либо продукта, носящего имя ILM, следует понимать, что начать процесс придется с обучения сотрудников и определения прав доступа к тем или иным ресурсам, чтобы необходимые файлы сохранялись именно там, где нужно, а не попадали случайно в корень диска D или, того лучше, на флэш-брелок пользователя.
Но есть и весьма удачные решения ILM на базе стандартного оборудования крупных производителей. Так, компания Hewlett-Packard предлагает пользователям оборудования для хранения данных применять дополнительный функционал ILM. В качестве хранилища первого уровня, которое вмещает актуальную информацию, письма и файлы, могут выступать как продукты HP StorageWorks XP, так и массивы MSA или модульные системы хранения Enterprise Virtual Array.
Для создания «справочного» хранилища, вмещающего все данные, которые не обязательно иметь для работы, но необходимо хранить для справок или согласно требованиям буквы закона, предусматривается использование HP Reference Information Storage System (RISS). Данное решение имеет хорошую масштабируемость благодаря grid-архитектуре, что позволяет распределить систему хранения не только между несколькими массивами, но даже между несколькими зданиями, работая с ней как с единым виртуальным пространством при помощи ПО HP Storage Essentials Enterprise Edition.
Согласно заявлениям специалистов НР, данная система управления интегрируется с HP OpenView, что позволяет управлять большой частью IT-инфраструктуры из одного окна. Но что важнее, система хранения на базе RISS самостоятельно организует миграцию файлов согласно настройкам политики безопасности. Безусловно, подобные готовые решения будет гораздо легче внедрять как благодаря их целостности, так и благодаря всесторонней поддержке со стороны производителя.
Адресуемые пространства
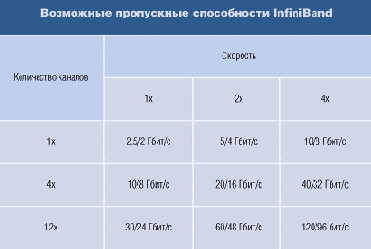
Что касается количества подключаемых через InfiniBand устройств, то протокольных ограничений для него не существует. Главное реальное ограничение - 24-битный адрес устройства LID (локальный идентификатор - Local ID). Этот адрес используется при маршрутизации. Соответственно, адресное пространство целевых узлов, обслуживаемых одним маршрутизатором, ограничивается примерно 16 млн. устройств.
В современных решениях применяется динамическая трехэтапная маршрутизация. После получения ответа на широковещательный запрос абсолютного адреса целевого узла (GUID), поступающий извне, маршрутизатор сообщает LID, под которым у него зарегистрирован ответивший узел.
В качестве развития этой технологии предусмотрена маршрутизация между подсетями с помощью 16-байтного (96-битного) GID. GID - это тот же GUID, но с префиксом адреса подсети. Очевидно, что такое осуществление маршрутизации ориентируется на протокол IPv6.
Как уже говорилось, обмен ведется отдельными сообщениями - их размер составляет до 4 кб. Кроме сообщений сданными, предусмотрено также большое количество служебных сообщений, отвечающих за безопасность или качество доставки. Сам обмен данными происходит в трех режимах: прямого удаленного доступа к памяти (RDMA), операций чтения и записи в канал, а также в режиме транзакций с возможностью подтверждения или обращения к журналу отката.
За передачу данных отвечают канальные процессоры, почти такие же, как в мейнфреймах. На стороне сервера эти адаптеры называются НСА (Host Channel Adapter), а на стороне устройства хранения - ТСА (Target Channel Adapter).
Адаптеры СА - достаточно интеллектуальные устройства, которые способны самостоятельно устанавливать защищенное соединение или договариваться о предоставлении качества обслуживания (QoS).
Архитектура бесконечных возможностей
Арсений Чеботарев, Сети и телекоммуникации
Все большее применение в центрах обработки данных находит технология InfiniBand, созданная для подключения сетевых систем хранения. На чем же основана столь широкая популярность?
Вопрос о том, как освободить центральный процессор компьютерной системы от выполнения операций обмена данными, до сих пор остается открытым. Особенно это актуально для серверов или производительных рабочих станций. Так, мейнфреймы IBM всегда располагали канальными процессорами, основная функция которых заключалась в обмене данными с устройствами ввода-вывода. Правда, в обычных ПК такая функциональность в той или иной мере представлена различными контроллерами.
Сегодня организация вычислений (в частности, центры обработки данных) требует использования сетевых накопителей и так называемых "сетей хранения" (SAN – Storage Area Network). Устройства SAN обладают достаточным интеллектом для того, чтобы создавать виртуальные тома, разделяя дисковое пространство накопителей между серверами, а также для резервного копирования данных или самодиагностики.
В результате разделения пространства (как и для любой технологии виртуализации) достигается более эффективное использование ресурсов, обеспечиваются дополнительные возможности для масштабирования систем, а также снижаются эксплуатационные затраты. То есть если все диски вычислительного центра разместить в отдельные стойки, то их замена или обслуживание будут осуществляться намного проще. Сами виртуальные тома легче динамически перераспределить между серверами в зависимости от возникающей нагрузки.
Будущее InfiniBand
InfiniBand предоставляет целый ряд преимуществ по сравнению с коммуникационными технологиями. В частности, поддержка Remote DMA (когда данные перемещаются между ОЗУ компьютеров без участия процессоров и ОС) обеспечивает важные прерогативы при построении кластеров с массовым параллелизмом, например, на основе Linux. Несмотря на то, что стоимость реализации этой технологии в сотни раз меньше по сравнению с аналогичными по мощности суперкомпьютерами, это вовсе не дешевые решения. На цене сказывается использование специального оборудования, наличие множественных портов ввода-вывода и такого же количества маршрутизаторов. Большинство компаний среднего масштаба по-прежнему предпочитает адаптировать все технологии к привычным Ethernet и TCP/IP. Несмотря на то, что Ethernet, как наиболее близкую из конкурирующих технологий, отличают огромный опыт внедрения, обширнейшая инсталляционная база, а также поддержка сотнями производителей оборудования, ее возможности, причем даже в версии 10 Гбит/с, несопоставимы с потенциалом InfiniBand.
С предлагаемыми сегодня и пока не очень многочисленными продуктами InfiniBand для построения сетей можно ознакомиться на сайте InfiniBand Trade Association по адресу infinibandta.org. Распространение InfiniBand на рынке может достигаться за счет применения в кластерных решениях. В частности, эта технология интегрируется с HyperTransport (разработка компании AMD), благодаря чему полученный HyperTunel может использоваться для прозрачного обмена в рамках кластера. Таким образом, InfiniBand предназначена для наиболее важных приложений, и по мере распространения параллельных и сетевых вычислений она может стать массово применяемой.
Практика производительных вычислений
И наблюдения, и (намного чаще) моделирование работы сети нередко показывают неравномерность нагрузки. Вообще, ИТ-специалисты предпочитают асимметричные схемы, иерархические структуры и т.п. Но на самом деле в основе этих подходов лежит более сложное программирование сетевых вычислителей. Поэтому системы с симметричными вычислениями достаточно распространены, хотя они применяются только тогда, когда действительно можно использовать все преимущества этого подхода.
Что касается маршрутизаторов, то в идеале они могли бы набираться из отдельных портов. Но это невозможно, поскольку проводники не могут быть достаточно длинными и одновременно поддерживать высокую скорость передачи. Таким образом, чем меньше проводников и чем они короче, тем лучше для пропускной способности. В качестве компромиссного решения можно представить 24-портовые маршрутизаторы Cisco InfiniBand, которые могут подключаться также к обычным сегментам сети с помощью модулей расширения Fiber Channel или Gigabit/10 Gigabit Ethernet.
Когда InfiniBand служит для связи процессоров в схемах с общей памятью, логично размещать адаптеры InfiniBand в непосредственной близости от модулей памяти, и, как следствие, от самих процессоров. Чтобы использоваться в подобных решениях (вроде кластерных компьютеров Cray), сетевые контроллеры непосредственно вмонтированы в материнские платы. Но в данном случае о "конструкторе из недорогих компонентов" речь уже не идет.
Принципы архитектуры
В процессе создания стандартной технологии, получившей название InfiniBand, было выработано несколько основных принципов реализации каналов. Один из них базируется на современном подходе к распределению нагрузки. InfiniBand, как правило, не реализуется в одном (и достаточно дорогом) устройстве, которое контролирует все операции. Вместо этого применяются множество небольших и сравнительно недорогих строительных узлов, которые могут быть подключены в различных комбинациях. С их использованием можно наращивать производительность системы. Например, один физический канал можно заменить четырьмя, притом с точки зрения приложения эти каналы будут работать как одно целое. Также можно реализовать двенадцать каналов с соответствующим увеличением пропускной способности. В пресс-релизах производителей возможность наращивания пропускной способности рассматривается как готовность к будущему, которая не оплачивается сегодня. К тому же демонтаж и замену модульных систем технически и экономически осуществить проще, и они могут проводиться без прекращения обслуживания. Сегодня, когда модернизация блейд-серверов и кластерных модулей производится практически постоянно, это особенно важно.
В отличие от других шинных архитектур, в которых пропускная способность шины строго фиксирована, InfiniBand позволяет строить любое количество избыточных каналов между двумя точками. Маршрутизация осуществляется динамически, то есть сеть сама определяет наилучший маршрут прохождения (кратчайший маршрут выбирается первым).
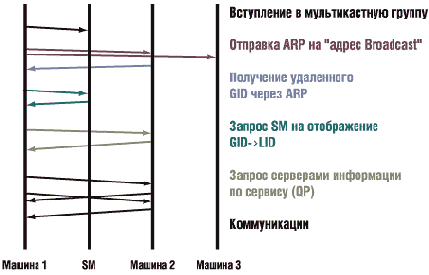
Динамическая маршрутизация проходит в несколько этапов
Этот принцип позволяет понимать буквально приставку Infini- ("бесконечно"). Пропускная способность такой сети в большей мере определяется финансовыми возможностями заказчика. Правда, свои ограничения накладывает и специфика функционирования сетевых узлов.
Еще один принципиальный момент - избыточность. Правильно настроенный кластер будет продолжать работу даже при выходе из строя части узлов. К тому же кластер сам может частично отключать (освобождать) свои узлы в зависимости от динамически возникающей нагрузки. Отключенные узлы могут поступить в распоряжение другого виртуального кластера, благодаря чему уровень использования ресурсов приблизится к стопроцентной отметке.
Дополнительной особенностью InfiniBand является наличие механизмов защиты трафика и обеспечения качества обслуживания. Это позволяет, в частности, осуществлять доставку медиаконтента по заказу.
Протокол обмена опирается на новое поколение интерфейсов. Обмен данными основан не на традиционной для шинных архитектур операции "загрузить-сохранить", а на более гибкой схеме циркуляции управляющих сообщений. Благодаря этому появляется возможность реализовать часть операций (как, например, поиск, резервное копирование или запись изменений) на самих системах хранения, и, как следствие, исключить большую часть паразитного трафика.
Проблема связи
Основной проблемой для систем хранения данных становится недостаток пропускной способности в каналах связи, посредством которых SAN подключается к "внешнему миру". Еще десять лет назад такие системы должны были обеспечивать обмен данными со скоростью 50 Мб/с, как и при подключении обычных SCSI-дисков, чтобы пользователи не ощущали разницы в работе с локальными дисками. Для производительных RAID-массивов могла потребоваться скорость в 300 Мб/с. Надо сказать, что ни одна сетевая технология не предлагала в то время такой пропускной способности. Номинально гигабитную производительность обеспечивала технология Gigabit Ethernet. Однако на практике скорость передачи данных оказывалась (и оказывается) меньше заявленной.
Сегодняшние дисковые интерфейсы позволяют достигать скорости до 1,5-3 Гбит/с. Последние поколения жестких дисков, как, например, Seagate Barracuda ES емкостью 750 Гб, оснащаются интерфейсом SATA II, обеспечивающим передачу 300 Мб/с.
Реальная скорость такого интерфейса с учетом накладных расходов составляет около 1,7 Гбит/с. В то же время с увеличением объемов циркулирующих данных даже возможностей такой технологии, как 10 Gigabit Ethernet, через какое-то время может оказаться недостаточно.

В оборудовании компании Cisco Systems наряду с Ethernet
поддерживается технология InfiniBand
Первые специализированные коммутационные решения для систем хранения основывались на фирменных вариантах волоконно-оптических и медных сетей. Для повышения скорости производители прибегали к разного рода ухищрениям вроде огромных кэшей, реализуемых в контроллерах, или алгоритмов предварительного чтения read-ahead, используемых приложениями. Позже определились две конкурирующие группы производителей, каждая из которых предлагала свое решение: Future I/O у Compaq, IBM и Hewlett-Packard, а также Next Generation I/O у Intel, Microsoft и Sun. Впоследствии флагманы индустрии объединились, чтобы создать новый стандарт скоростных сетей для подключения систем хранения.
Протоколы высокого уровня
Конечно, чтобы реализовать такие возможности, архитектура InfiniBand требует наличия определенных программных инструментов и поддержки со стороны операционной системы. Традиционно система воспринимает накопители SAN как обычные диски SCSI (iSCSI). Как вариант может рассматриваться подключение посредством NAS (Network Attached Storage) с методами доступа NFS/CIFS.
Традиционные сетевые файловые системы являются блокирующими. Из соображений целостности данных они ограничивают одновременный доступ к взаимосвязанным данным. Соответственно, операции записи для определенного файла доступны только одному внешнему процессу. Обеспечить параллельный доступ к данным этого файла невозможно.
Решать проблему параллельного доступа можно двумя путями. Первый - это поддержка параллельных копий файла с последующей синхронизацией (рекомбинацией). Второй - блокировка на уровне более мелких элементов информации, таких, как сегменты или блоки файлов, или же блокировка записей базы данных или объектов. Параллельный доступ с рекомбинацией метаданных обеспечивают объектные файловые системы Lustre или Раnasas, а прямой доступ с блокировками - Oracle Cluster Filesystem, Veritas, XFS, iBRIX и еще несколько конкурирующих схем хранения.
Техническая реализация
Когда речь идет о том, что InfiniBand не использует общую шинную архитектуру, имеется в виду, что шина не используется в традиционном режиме разделения и блокировок (когда одно устройство захватывает шину, и до окончания операций с ней остальные ждут завершения обмена). Для этой технологии более приемлемой оказалась топология "логической шины" (switched fabric). Данное словосочетание можно перевести как "коммутируемая канва", но чаще (и неверно) оно переводится как "коммутируемая фабрика".
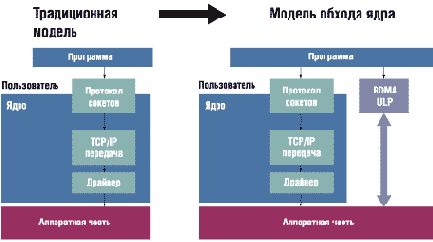
C RDMA вычислительный ресурс на одном сервере получает доступ к памяти программы
на удаленном сервере, не задействуя ядро процессора
Подобная топология ранее была известна также как FC-SW, где FC обозначает Fiber Channel, а SW - SWitch. Принцип осуществления коммутации в рамках этой топологии заключается в том, что каждый из узлов (серверов) связывается с каждым из хранилищ данных через группу коммутаторов.
Коммутаторы и подключения составляют один логический канал и называются "зоной". Когда серверу необходимо установить связь с конкретным хранилищем, он автоматически осуществляет поиск свободного коммутатора и начинает работать только с ним. Как следствие, отдельный канал не разделяется между несколькими передачами, а поскольку количество физических линий равно всем возможным соединениям, то передача всегда идет в полнодуплексном режиме.
Сами маршрутизаторы соединяются друг с другом специальной шиной Inter Switch Link (ISL) через E-port (E -Expansion). Очевидно, что две точки могут захватить более одного физического канала связи, так что скорость может наращиваться пропорционально наличию избыточных маршрутов.
Чтобы оценить суммарную скорость передачи, нужно принять во внимание следующие соображения. Один канал, используемый InfiniBand, изначально определен как последовательное экранированное соединение. В нем обеспечивается передача около 2,5 Гбит/с в каждом направлении. В зависимости от возможностей среды передачи InfiniBand может устанавливаться удвоенная и учетверенная скорость передачи, то есть 5 Гбит/с и 10 Гбит/с соответственно.
Поскольку каждый байт сопровождается двумя контрольными битами, реальная пропускная способность составляет 80% от номинальной, то есть могут формироваться потоки в 2 Гбит/с, 4 Гбит/с или 8 Гбит/с полезного трафика, причем обмен потоками происходит в полнодуплексном режиме.
Спецификация предусматривает объединение четырех или двенадцати каналов в один логический. В случае объединения двенадцати четырех скоростных физических каналов достигается номинальная скорость 120 Гбит/с (или 96 Гбит/с полезного трафика).
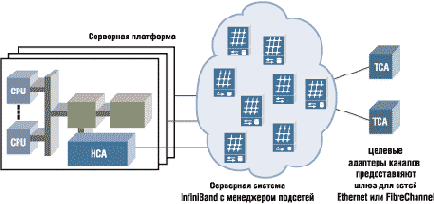
Технология InfiniBand предполагает использование множества узлов,
которые могут быть подключены в разных комбинациях
Такие величины, разумеется, нужно рассматривать только как теоретически определенные максимумы. Даже для критических приложений и конфигураций существуют "моменты отсечения", то есть пиковый трафик, на который не рассчитывают при проектировании пропускной способности. Можно сконфигурировать систему, способную пропускать любой трафик, но ее стоимость будет слишком высокой.
Особенно важным для межпроцессорного взаимодействия (IPC) параметром является время задержки, или латентность. Приемлемыми считаются значения не более 10 мс. Современные системы InfiniBand обеспечивают задержку до 4 мс. В других архитектурах, вроде локальной технологии AMD HyperTransport, применяющейся в кластерах Cray XD1, достигаются значения задержек до 1,5 мс. Но это достаточно специфическое и дорогое решение, которое к тому же не может массово использоваться в центрах обработки данных. В качестве естественного расширения Cray уже использует вариант "HyperTransport поверх InfiniBand", который скоро должен оформиться как отраслевой стандарт HyperTunnel.
Альтернативные технологии
В ответ на новые тенденции в рамках стандартизирующей организации Storage Networking Industry Association в феврале 2001 года был образован специальный форум SNIA IP Storage Forum. Миссия форума заключается в развитии стандартов для решений, связанных с блочным обменом данными по IP-сетям. Форум разделен на три подгруппы, соответственно трем основным технологическим направлениям: FCIP, iFCP и iSCSI.
iSCSI — полностью основанный на TCP/IP протокол, позволяющий установить взаимодействие и управлять устройствами хранения, серверами и клиентами, построенными на идеях IP. Это самый революционный подход к преображению SAN, предлагающий использовать для SCSI транспортный протокол, оперирующий поверх TCP. В частности, он предусматривает новый механизм для передачи инкапсулированых в пакеты команд SCSI. Протокол iSCSI предполагает разработку нового поколения устройств, полностью отказываясь от Fibre Channel в пользу «чистого» TCP/IP. FCIP — основанный на TCP/IP туннельный протокол, позволяющий объединить географически разнесенные сети хранения, построенные по технологии Fibre Channel. Иногда его называют также Fibre Channel over TCP/IP. Данный подход ориентирован на объединение IP-сетями изолированных сетей хранения, построенных по технологии Fibre Channel. Таким образом, формируются сети хранения на уровне LAN, MAN или WAN. Как следует из названия, спецификация является сочетанием двух подходов; из трех вариантов это наименее радикальное решение. В нем необходимая функциональность распределена между Fibre Channel и TCP/IP. iFCP — основанный на TCP/IP протокол для объединения в сеть устройств или сетей, выполненных по технологии Fibre Channel, использующий инфраструктуру IP вместо коммутирующих и маршрутизирующих элементов Fibre Channel. Таким образом, образуется шлюз, который использует верхний уровень протокола Fibre Channel для SCSI и переносит его на TCP/IP. Таким образом, удается исключить коммутатор Fibre Channel и подключать существующие накопители Fibre Channel к IP-сети.
Каждая из подгрупп, входящих в состав SNIA IP Storage Forum, разрабатывает свой собственный стек протоколов под общим патронажем IETF. Членами форума являются свыше сорока компаний-участников SNIA.
FCIP
Если бы удалось увеличить расстояния между отдельными фрагментами сетей Fibre Channel SAN, то появилась бы возможность решить целый ряд задач, в том числе создание резервных центров и возможность для эффективного использования ресурсами провайдеров услуг хранения (SSP — storage service provider). Такая форма услуги представляется очень разумной, поскольку позволяет пользоваться неограниченными по возможностям, высоконадежными и профессионально обслуживаемыми накопителями. Существует несколько теоретических возможностей для создания туннелей между отдельными фрагментами сетей хранения.
Fibre Channel по DWDM (dence wavelength division multiplexing — «плотное волновое мультиплексирование») является приемлемым решением для асинхронных операций, в основном для зеркалирования в городских сетях, но отличается высокой стоимостью. Fibre Channel по SONET (Synchronous Optical NETwork) обладает примерно такими же характеристиками, как и Fibre Channel по DWDM. Fibre Channel по ATM в зависимости от класса обслуживания (ATM Class of Service — CoS) может использоваться для асинхронных и синхронных операций; также относится классу дорогих. Fibre Channel по IP (FCIP) признано наиболее удачным сочетанием технологий для обеспечения традиционных сетевых соединений для передачи данных и образования сетей хранения.
Сравнение технических характеристик различных способов передачи данных в контексте их использования для интеграции можно найти в [6].
FCIP интегрирует отдельные острова сети хранения средствами нижележащей глобальной сети по протоколу IP, таким образом удается не только расширить функциональные возможности и повысить экономическое значение существующих хранений, построенных по технологии Fibre Channel, но при этом еще и сохранить сделанные в них инвестиции. Для подключения SAN к WAN служит интерфейсный модуль, преобразующий кадры Fibre Channel в IP-пакеты и адреса Fibre Channel Fabric Domain в IP-адреса. Обычно эту функцию выполняет оптический маршрутизатор, стоящий на границе FC-IP.
Таким образом, SAN «переходит» границу IP- сети без каких бы то ни было изменений в функционировании серверов, накопителей и других устройств и программ, работающих в пределах сети хранения. Очевидно, что это решение проще и дешевле других и может быть востребовано пользователями, уже имеющими определенный задел в SAN.
FCIP определен как туннелирующий протокол для прозрачного объединения географически разнесенных построенных по технологии Fibre Channel сетей хранения по IP-сетям. Он использует TCP/IP только в качестве транспорта, не затрагивая коммутацию, реализуемую Fibre Channel Fabric. Стандарт FCIP обеспечивает работу по IP под управлением средств, используемых в существующих сетях хранения. При разработке этого стандарта рабочая группа IETF IPS Working Group ставит перед собой следующие задачи [7]:
определение правил инкапсуляции кадров Fibre Channel для их транспортировки по TCP/IP; определение правил инкапсулированных данных для установления виртуальных соединений Fibre Channel, связывающих устройства и коммутаторы Fibre Channel; определение правил для спецификации среды TCP/IP, поддерживающей виртуальные соединения Fibre Channel и обеспечивающей туннелирование трафика Fibre Channel по IP-сетям, включая обеспечение безопасности и целостности данных.
Для установления соединений между удаленными сетями хранения по локальным, территориальным и глобальным сетям FCIP использует соответствующие службы, но при этом, контролируя переполнение канала FCIP, опирается на TCP/IP, а в обработке ошибок в данных и восстановлении данных — на Fibre Channel.
В отличие от iSCSI в данном случае не приходится решать всего комплекса проблем, связанных с надежностью и безопасностью: они решаются стандартными средствами TCP/IP. Задача пользователя ограничивается выбором канала соответствующей пропускной способности (скажем, ОС-12 или ОС-48), а затем магистральные маршрутизаторы свяжут отдельные фрагменты в единую сеть. Важно, что средства управления, используемые в глобальных сетях, полностью и автоматически могут быть приложены к FCIP.
Можно выделить пять областей применения FCIP [8].
1. Объединение нескольких корпоративных сетей хранения в пределах, географически ограниченных размерами предприятия или учреждения (обычно такую область называют кампусом по примеру университетских городков). В какой-то момент существования корпоративной сети хранения перед специалистами с неизбежностью встает вопрос, как именно дальше развивать инфраструктуру — ограничиться технологией Fibre Channel или воспользоваться средствами FCIP. Часто последнее решение оказывается более оправданным экономически.
2. Ставшие в последнее время особенно востребованными решения, обеспечивающие резервирование информации и создание катастрофоустойчивых конфигураций.
3. Более эффективное распространение контента. По мере роста объемов передаваемых данных, особенно с появлением аудио- и видеоинформации, все более актуальной становится задача обмена информацией между теми инфрастрактурами, которые ее хранят, и потребителями — напрямую, без участия серверов. Это в некотором смысле реинкарнация на новом уровне одной из базисных идей SAN — обеспечить возможность взаимодействия между накопителями без вмешательства в этот процесс серверов.
4. Появление услуги хранения данных силами провайдеров SSP. По мере снижения стоимости дисков и других типов накопителей наиболее актуальными становятся задачи снижения стоимости управления системами хранения и их масштабирование, создание систем «памяти по запросу» (storage on demand). Технологии, предлагаемые провайдерами SSP, решают эти проблемы. Пользователи обращаются к дискам, расположенным в центрах хранения данных как к локальным, а провайдер осуществляет прозрачное для них управление ресурсами. Наращивание дискового пространства выполняется по мере необходимости, проявляемой приложениями, и тоже может быть вполне прозрачным для пользователя.
5. World Wide SAN. Как конечная цель развития сетей хранения может рассматриваться создание Всемирной сети хранения, некоторого аналога WWW, однако это вопрос еще неопределенного будущего.
IFCP
Спецификация [9] определяет iFCP как протокол межшлюзового соединения (gateway-to-gateway). Это соединение предназначено для замены матрицы Fibre Channel Fabric с ее маршрутизирующими и коммутирующими функциями своими собственными средствами на основе TCP/IP, которые способны выполнять по существу те же самые функции, но на другой технической основе. Важно, что, предоставляя аналогичные возможности, iFCP позволяет подключать к IP-сетям и существующие устройства, используемые в Fibre Channel, хотя при этом не используется технология обмена данными из Fibre Channel.
Для достижения совместимости iFCP поддерживает FCP, стандарт сериализации команд ANSI SCSI, необходимый для их передачи по последовательному интерфейсу, дисциплину обмена между инициатором и целевым устройством, принятую в SCSI при работе по последовательному соединению. По существу, iFCP замещает только транспортный уровень Fibre Channel (FC-2) сетью IP или Ethernet, но сохраняет верхний уровень (FC-4). Это достигается отображением существующей транспортной службы Fibre Channel на транспортную службу TCP/IP. В итоге известными средствами обеспечивается надежная передача данных по ненадежным сетям и безопасность информации, что составляет отдельную и одну из основных задач в iSCSI.
В этом заключается коренное различие между подходами iSCSI и iFCP. В первом случае для получения преимуществ, которые дает TCP/IP, нужно строить все сызнова, используя специализированные устройства, а во втором можно сохранить практически весь парк оборудования Fibre Channel. Заменяется собственно сеть на базе Fibre Channel на сеть TCP/IP. При этом одновременно решаются две задачи: организация обмена данными между устройствами и установление соединения типа SAN-to-SAN между существующими сетями хранения.
В качестве основного системообразующего элемента в iFCP выступает многопортовый шлюз с тремя типами портов:
со стороны Fibre Channel (F-port для подключения отдельных устройств, например, дисковых массивов; FL-Port для подключения группы устройств, входящих в кольцо с арбитражным доступом; E-port для подключения непосредственно к коммутаторам Fibre Channel; универсальный порт Auto Port); со стороны IP (порт для подключения к оборудованию IP и Gigabit Ethernet; порт для агрегированного подключения к оборудованию IP и Gigabit Ethernet); два сервисных порта (Management Port для управления Java-устройствами; RS232 Console Port для рутинных задач управления, таких как назначение адресов, диагностика и т.п.).
Этот шлюз помимо физического соединения выполняет преобразование адресов из портов Fibre Channel в IP и обратно. Система имен устройств в Fibre Channel построена на основе Fibre Channel Generic Services (FC-GS); в IP ее эквивалентом является Internet Storage Name Service. В данном случае в репозитории этого сервера хранятся имена всех объектов, входящих в хранилище, построенное на основе iFCP, т.е. доменные имена, имена устройств Fibre Channel, портов, шлюзов и т.д. Совместно шлюзы и система адресации позволяют собирать сеть произвольной конфигурации.
Рис. 5. Шлюз iFCP
Литература
[1] Л. Черняк, SCSI-3 и Ultra 3 SCSI — не одно и то же. PC Week/RE, 1999, № 11
[2] Л. Черняк, Стандарты Fibre Channel — основа SAN. PC Week/RE, 2000, № 9
[3] Tom Clark, IP SANs, A Guide to iSCSI, iFCP and FCIP Protocols for Storage Area Networks. Addison-Wesley, 2001
[4] iSCSI Technical White Paper, www.snia.org/English/Collaterals/Forum_Docs/IP-_Storage/iSCSI_Technical_whitepaper.PDF
[5] Internet Storage Name Service (iSNS), http://www.ietf.org/internet-drafts/draft-ietf-ips-isns-06.txt
[6] Data Storage Anywhere, Any Time Metro and Wide Area Storage Networking, Nishan Systems, 2001
[7] The Emerging FCIP Standard for Storage Area Network Connectivity Across TCP/IP Networks, Storage Networking Industry Association (SNIA), 2001
[8] Robert Preece, Extending Storage Networking Over Optical IP Networks, Lucent Technologies, 2001
[9] Internet Fibre Channel Protocol (iFCP) — A Technical Overview, SNIA, 2001
IP для сетей хранения
Леонид Черняк
22.01.2002
Открытые системы, #01/2002
Бизнес-факторы, определяющие актуальность и привлекательность сетей хранения, очевидны. Современные Internet-приложения отличаются не только большими объемами информации, которой они оперируют, но и тем, что существуют в ее среде и, по существу, информацией управляются. Вследствие этого изменилось и само отношение к хранимым данным — системы хранения стали центром, а серверы переходят в разряд периферии.
Постоянно возрастающий объем накопленных данных вызывает взрывной спрос на системы хранения, которые способны обеспечить динамическое масштабирование, высокую готовность и уменьшение затрат на управление, т.е. увеличение числа терабайт на одного администратора. Именно поэтому, как ответ на новые запросы, и появились сети хранения. Идея консолидации хранения оказалась настолько привлекательной, что немедленно вызвала многочисленные позитивные и многообещающие высказывания. Началось обычное для нашего времени явление, которое называют hype, buzz или шумихой — кому что милее.
Доверяя бумаге, про овраги, конечно же, забыли. Существующие в настоящее время сети хранения строились и пока по-прежнему строятся преимущественно по технологии Fibre Channel, используемой в качестве средства транспортировки данных между системами хранения и серверами. За несколько лет своего существования сети хранения практически однозначно ассоциировались с Fibre Channel. Между тем, при первых же практических попытках внедрения сетей хранения стало понятно, что идея развертывания выделенной высокоскоростной сети, специально предназначенной для блочного обмена данными, очень хорошо смотрится в теории, но, увы, на практике оказывается далеко не столь простой. К тому же в реальной жизни встают непростые практические вопросы наподобие несовместимости продуктов разных производителей, нехватки специалистов соответствующей квалификации и высокой стоимости проектов. Эксплуатация сетей хранения показала, что реальной экономической проблемой становится не только стоимость сетевого оборудования или устройств хранения, но и затраты на управление и администрирование.
Сложности, выявляющиеся при внедрении, усугубляются слабостью стандартизации, точнее, потенциальной возможностью для использования каждым из производителей той интерпретации стандартов, которая ему предпочтительнее. Для того чтобы справиться с проблемами несовместимости, ведущие крупные компании не только вынуждены создавать свои собственные средства управления — им еще приходится строить огромные тестовые центры, инвестируя в них миллионы долларов. Как бы не гордились своими инвестициями в тестовые лаборатории ведущие компании, в конечном итоге эти затраты ложатся на покупателя — и все это, по большей части, в основном ради преодоления сохраняющихся проблем несовместимости аппаратных и программных средств.
В итоге, спустя несколько лет после появления решений категории SAN (первые коммерческие предложения датируются 1997 годом), можно с уверенностью сказать, что сети хранения первого поколения, безусловно, изменили ландшафт корпоративных инфраструктур, но все же не полностью, они не оправдали возложенные на них ожидания. Поэтому в 2001 году в качестве альтернативы им, стали рассматривать несколько новых технологий, использующих протокол Internet Protocol. В основном они сохраняют идеологию SAN, но основываются на иных технических решениях.
Разумность обращения в эту сторону не вызывает сомнения, поскольку существующие инфраструктуры IP и Ethernet образуют прочный фундамент всех сетей передачи данных и, если бы удалось приспособить эти хорошо знакомые специалистам технологии для целей сетей хранения, то удалось бы сразу убить нескольких зайцев.
Прежде всего, существенно сокращаются затраты на исследования и разработки, поскольку можно использовать одни и те же технические средства для создания и управления и традиционной сетевой инфраструктуры, и сетей хранения; в итоге снижается общая стоимость проектов.
Во-вторых, практически полностью решается проблема подготовки обслуживающего персонала. Несомненно, в недалеком будущем производители систем хранения на базе IP сумеют адаптировать для своих нужд такие инструменты управления, как CA Unicenter, HP OpenView или Tivoli.
Наконец, снимается с повестки дня проблема расстояния, следовательно, появляется возможность выработки более надежной стратегии при создании катастрофоустойчивых конфигураций, решаются проблемы дистанционного зеркалирования дисков, кластеризации серверов, создания резервных копий и т.д. Область действия SAN получает распространение на большие расстояния, на глобальные сети (WAN — wide area network) и на городскую инфраструктуру, теперь часто называемую сетями MAN (metro area network, от греческого metropolis, «большой город»).
ISCSI
Наиболее детальное описание iSCSI можно найти в [4] и [5]. Использование протокола TCP/IP напрямую для блочного обмена данными между устройствами усложняется тем, что при решении этой задачи нужно объединить вместе две противоположные по своим изначальным свойствам среды. Среда SCSI по определению обеспечивает надежный и безопасный обмен информацией между устройствами хранения. TCP/IP, напротив, задуман для работы в ненадежных по своей природе сетях. Преодоление этого противоречия и составляет основную инженерную задачу, решаемую при создании iSCSI. В привычном параллельном варианте SCSI шинное подключение снимает вопросы о целостности данных и информационной безопасности. К тому же шина исключает и проблемы, связанные с установлением взаимодействия между участвующими в обмене данными устройствами. Совсем иные условия предполагает переход к сетям TCP/IP. Чтобы контролировать передачу данных по потенциально ненадежной сети, в iSCSI необходима избыточность, необходимо вместе с командами SCSI дополнительно передавать служебную информацию. Используя ее, оборудование, работающее по протоколу iSCSI, осуществляет мониторинг блочной передачи, корректность завершения операций ввода/вывода и обработку ошибок. Кроме того, возникает потребность в некоторой системе взаимодействия между устройствами посредством назначения им имен, чтобы устройства могли находить друг друга. Наконец, возникает и еще одна неожиданная задача: обеспечение безопасности.

Таким образом, технологию iSCSI можно свести к четырем базисным составляющим.
Управление именами и адресами (iSCSI Address and Naming Conventions). В среде iSCSI, подчиняющейся стеку протоколов IP, действуют два типа устройств, которые называют инициаторами (iSCSI initiator) и целевыми устройствами (iSCSI target). В качестве первых чаще всего выступают компьютеры-серверы, а вторых — дисковые массивы или ленточные библиотеки. С точки зрения iSCSI инициатор — это клиент, а целевое устройство, обслуживающее его, — сервер. Собственно среду передачи образуют коммутаторы Gigabit Ethernet и/или маршрутизаторы IP.
Подобно обычной реализации IP, подключенное к сети устройство автономно находит партнера для обмена данными и осуществляет подключение к нему. До сих пор нечего иного, чем адресная система, для этой цели человечество еще не придумало, следовательно, нужна адресная книга, и инициатор должен иметь к ней доступ. Книга содержит список IP-адресов целей, по ней инициатор может просматривать таблицу устройств типа DNS в сети. Работа с именами определена службой имен устройств хранения iSNS (Internet Storage Name Service). По соглашению (iSCSI naming convention) допускаются имена устройств с потенциальной длиной до 255 байт, но не все это имя iSCSI полностью используется для маршрутизации. Для маршрутизации разработана схема комбинированного использования IP-адреса и номера портов. Любое устройство идентифицируется как узел (iSCSI Node) внутри сетевой единицы (Network Entity), которая доступна из сети. Несколько узлов могут быть собраны в портал (Network Portal), которому назначается IP-адрес, а внутри устройства дифференцируются по номерам портов TCP. Но при этом устройство имеет еще и свое уникальное имя. В итоге получается довольно гибкая схема, которая позволяет изменять «конфирмацию» (т.е. при перемещении меняются IP-адрес и порт TCP), но остается возможность установления связи с устройством и сохранение изменившихся адресов. Имена iSCSI сохраняют читаемую форму, но для удобства работы операторов к тому же можно присваивать «клички» (alias name option). Управление сеансом (iSCSI Session Management). Сеанс iSCSI состоит из трех фаз. Она начинается с фазы iSCSI Login Phase, на которой специальной программой, обеспечивающей безопасность, проверяются аутентификационные параметры двух сетевых единиц и, если фаза прошла успешно, целевое устройство сообщает инициатору о своей готовности, иначе сеанс прерывается. Эта процедура в реальности может быть намного сложнее. За ней следует фаза нормального обмена транзакциями, называемая Full Feature. Завершается работа командой iSCSI. Обработка ошибок (iSCSI Error Handling). Для того чтобы обеспечить безошибочную передачу данных в условиях ненадежной среды, оба типа устройств — и инициатор, и целевое — имеют буфер, содержимое которого сохраняется до тех пор, пока не будет получено сообщение, подтверждающее успешное завершение транзакции. Обеспечение безопасности (iSCSI Security). Спецификация iSCSI допускает различные методы обеспечения безопасности.Шифрование, расположенное уровнем ниже iSCSI (такое как IPSec), будет прозрачным для верхних уровней. Сервер iSNS может использоваться в качестве репозитория для открытых ключей.
SAN и SCSI
Сделаем попытку проследить взаимосвязь между протоколами для альтернативных реализаций сетей хранения и общим для них стандартом SCSI. При различии технических решений их объединяет спецификация архитектуры SCSI, разрабатываемая техническим комитетом T10. В FCIP, iFCP и iSCSI, как и в Fibre Channel, в конечном счете, на уровне устройства реализуется стандарт команд SCSI. Иногда по неведению SCSI противопоставляют сетевым технологиям хранения, при этом совершенно ошибочно путая параллельный вариант SCSI — с него все действительно начиналось — с дальнейшими версиями этого интерфейса.
В основном он поддерживается комитетом T10 (www.t10.org), который входит в состав Американского национального комитета по стандартизации ИТ (NCITS — National Committee on Information Technology Standards). T10 работает в тесном сотрудничестве с отраслевой ассоциацией SCSI Trade Association (www.scsita.org). За годы своего существования спецификация SCSI претерпела несколько редакций; на сегодняшний день актуальной является версия SCSI-3, построенная на принципах многоуровневой модели. Схема на рис. 1 представляет собой ее адаптацию к целям данного изложения, из нее исключены некоторые несущественные детали.
В своем нынешнем состоянии схема спецификации состоит из корня — архитектурной модели SCSI (SAM — SCSI Architecture Model) и четырех ветвей. Модель можно разделить на два уровня. За два года, прошедших с момента публикации [1], где архитектура SCSI описана более подробно, модель SAM претерпела некоторые небольшие изменения, но принципиальные положения сохранились.
Верхний уровень SAM, называемый CAM-3 (Common Access Method), в свою очередь делится на две части. Он состоит из общих для всех устройств наборов команд (SPC, SPC-2, SPC-3) и стоящих над ними наборов команд, специфичных для определенных типов устройств (например, с блочной записью, с потоковой записью, мультимедийных и т.д.). SAM не является чем-то жестко фиксированным, по мере появления новых типов устройств, она расширяется и пополняется.
Нижний уровень архитектурной модели SCSI состоит из спецификаций, соответствующих конкретной физической реализации интерфейса. Отметим следующие:
группа SPI 1, 2,... 5, распространяющаяся на параллельные реализации (среди них SPI-3 — спецификация на Ultra 3 SCSI); SPB-2 — на интерфейс FireWire (IEEE 1394); FCP, FCP-2 — на оптические интерфейсы Fibre Channel; SSA — на последовательный интерфейс IBM SSA.
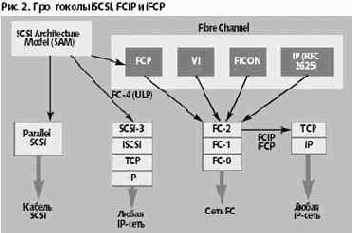
Из детализации, представленной на рис. 2, следует, что решения FCIP и iFCP уже по самому своему определению отличаются от iSCSI. Протокол iSCSI является вполне самостоятельной спецификацией, одной из семи существующих на сегодняшний день составляющих нижнего уровня архитектурной модели SCSI, в то время как FCIP и iFCP на самом деле суть альтернативные или дополняющие технологию Fibre Channel версии спецификации FCP, которая входит в число этих самых семи базисных спецификаций. Дело в том, что при выработке концепции SAN заранее изначально предполагалось, что сеть хранения не будет реализовываться исключительно средствами Fibre Channel; поэтому в ее основу была заложена многоуровневая модель, открывавшая возможность для альтернативных реализаций уровней, в частности, транспортного уровня. Появившиеся недавно протоколы FCIP и iFCP стали естественным развитием этой модели FCP. Вместе с ними на дереве появилась дополнительная ветвь. Они напрямую связаны с уровнем FC-4, т. е., если так можно сказать, «перехватывают» промежуточный уровень FC2 в модели FCP и «уводят» от Fibre Channel в IP. Этот механизм требует дополнительного пояснения.
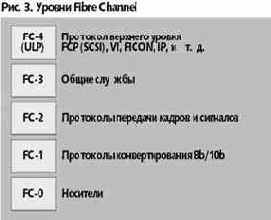
Напомним, что Fibre Channel — просто полнодуплексный последовательный коммуникационный интерфейс. В названии использовано французское слово для обозначения оптоволокна. Тем самым подчеркивается, что собственно присутствие оптики вовсе и не обязательно, возможна и классическая медная реализация, а возможны и те варианты, о которых в данном случае идет речь. Модель FC можно разделить на пять уровней, начиная с самого нижнего FC-0 и до верхнего FC-4.
Три первых уровня (0, 1 и 2) иногда объединяют общим названием Fibre Channel Physical (PC-PH). Прокомментируем распределение основных характеристик Fibre Channel по уровням.
FC-0. Физические характеристики: используемые сигналы и носители, скорости передачи данных, конструкция разъемов, спецификация передатчиков и приемников. Выше этого уровня оптика не поднимается. FC-1. Управление связью и синхронизация передачи данных. На этом уровне решается одна из важнейших задач — преобразование параллельного байтового представления данных в последовательный поток бит — так называемое преобразование 8B/10. FC-2. Формат кадров, управление потоком данных, классы служб. На этом же уровне определены три основных типа топологий: «точка - точка», «петля с арбитражным доступом» и «коммутируемая структура». FC-3. Уровень общих служб, определяющий свойства портов, по которым узлы подключаются к сети. Этот уровень в настоящее время в наименьшей степени стандартизован, можно даже сказать — пока неизвестно, существует ли он. FC-4. Верхний уровень, определяющий отображение протоколов TCP/IP, ESCON, HPPI, SCSI и ATM на транспортную систему FCN.
Более подробно модель Fibre Channel описана в [2]. В 2001 году вышла, посвященная новым протоколам монография [3].
Создание IP-сетей хранения данных
Александр Горловой, «Экспресс-Электроника», #12/2004
Традиционно система хранения подключается непосредственно к серверу, но с появлением сетей хранения данных (SAN) идея сетевого хранения стала привлекать внимание. Сетевое хранение – это глобальный термин, который относится не только сетям хранения на базе Fibre Channel, но и к любому устройству, к которому организован совместный доступ.
Появление SAN ( Storage Area Network ) было серьезным прорывом в области хранения данных, однако широкого, как ожидалось, распространения такие сети не получили. Их внедрили только те пользователи, которые имели насущную потребность в данной технологии.
Первоначально сети Fibre Channel ( FC ) имели некоторые недостатки: нехватка ПО и драйверов для работы с SAN, отсутствие управляющего ПО, а также потребности в новой, отличной от существующей, сетевой инфраструктуре. За последние два года были решены многие проблемы, связанные с ПО и с несовместимостью оборудования, однако практически без изменений остался один важный аспект: организация дополнительной сетевой инфраструктуры. Первоначальная стоимость развертывания новой инфраструктуры может составить до 40% стоимости оборудования SAN. Общие затраты на создание небольшой 8-узловой SAN могут превысить $40 тыс. (коммутаторы, кабели, контроллеры для серверов), что делает сеть недоступной для мелких и средних компаний.
Почти одновременно с появлением сетей хранения данных на базе FC началось обсуждение концепции создания сетей хранения данных на основе IP. Их преимущество в том, что можно использовать и развивать существующую инфраструктуру сетей IP. Конечно, сначала те же недостатки, что и у сетей на основе FC, (нехватка ПО и совместимость), были присущи и IP -сетям хранения данных, но сейчас большинство из них устранено.
Первым этапом создания IP -сети хранения стало предоставление пользователям IP -сети файловых услуг. Их дальнейшее развитие привело к появлению NAS -систем, которые производили компании Network Appliance, Auspex, Quantum.
Затем изготовители NAS - устройств начали расширять область применения новой технологии, допустив, что приложения (например, базы данных) тоже можно обслуживать при помощи NAS. Однако большинство пользователей не восприняли эту идею, в то же время со стороны сообщества SAN последовали доводы о неэффективности обслуживания баз данных при помощи NAS по сравнению с традиционными FC -сетями. Также были некоторые сложности в совместимости между кластерными технологиями и определенными базами данных. NAS -устройства должны были представлять некоторые свои тома в виде «блочных» данных, как это происходит в SAN. Это позволило операционным системам «видеть» такие тома как подключенные по SCSI локальные ресурсы, хотя организованы они блоками в IP -сети.
IP -сеть хранения не следует путать с широко распространенными традиционными сетевыми устройствами хранения NAS. Последние работают как файловые серверы и предоставляют другим серверам и пользователям тома данных в виде размещенных в сети некоторых точек доступа. Обычно эти функции реализуются при помощи протоколов NFS и CIFS. В дополнение к аналогичным файловым службам устройства IP -сети хранения предоставляют блоковые возможности, а подключенные серверы «видят» такие устройства как собственные локальные SCSI -приводы. Разница между ними в том, что в случае присвоения серверу блока данных последний может быть переформатирован в соответствии с загруженной ОС. Файловую службу или сетевую точку входа подключенный сервер (или пользователь) не могут отформатировать или изменить другим способом. Протоколы SIFS и NFS позволяют существенно увеличить производительность при передаче блоковых пакетов, особенно для приложений с большим количеством операций чтения/записи (базы данных и серверы приложений).
Есть несколько аспектов создания IP -сетей хранения, на которые следует обратить особое внимание: проектирование инфраструктуры, сами устройства хранения и стратегии резервного копирования/восстановления.
Технологии в сравнении
Сравнение IP SAN - и NAS -устройств — наиболее часто совершаемая ошибка.
Хоть и некоторые IP SAN имеют дополнительные функции, реализующие файловые службы, правильнее было бы их сравнивать с FC SAN.
Взаимодействие с NAS -устройствами происходит при помощи уже упомянутых сетевых протоколов CIFS или NFS. Достоинство такого подхода в том, что нет необходимости устанавливать на серверы или пользовательские рабочие места специальные драйверы. Недостаток — большое количество избыточных коммуникаций. Сеть хранения на базе IP ( IP SAN ) распределяет блочные ресурсы хранения между серверами. Хотя и требуется установка драйверов, пропускная способность сети в этом случае используется более эффективно.
В результате мапированные устройства для операционной системы выступают в качестве локальных дисков. Это позволяет устранить большинство затруднений, связанных с совместимостью некоторых приложений, например SQL и Exchange Server при работе с сетевыми устройствами хранения.
Еще одно ограничение на применение NAS -устройств накладывает масштабирование. Большинство серверов NAS имеют ограниченные возможности в области кластеризации и виртуализации. По мере расширения среды хранения добавляют новые независимые NAS -устройства, что приводит к увеличению расходов на управление столь сложной системой. Сети IP SAN позволяют построить виртуальный кластер из SAN -устройств.
Так как сети IP SAN значительно дешевле традиционных FC SAN, их вполне можно сравнивать с непосредственно подключаемыми устройствами ( DAS ). В разных областях применения используют разные подходы к организации систем хранения данных. (Некоторые из них рассмотрим позднее.) В любом случае, стоимость развертывания будет намного ниже, чем для традиционных сетей FC SAN.
Серьезным ограничением несамостоятельных систем хранения является как раз их несамостоятельность. Также указанные системы имеют и другие недостатки: собственно использование емкости и ограниченные возможности восстановления.
Одним из основных достоинств централизованного сетевого хранения можно назвать развитые возможности восстановления данных.
Так как серверы и системы хранения подключаются друг к другу через коммутатор, всегда есть возможность перемонтировать набор данных от одного сервера к другому. Для этого требуется предварительное планирование, зато можно сэкономить на покупке кластеризуемых версий ОС и приложений. Напомним, что в этом случае неизбежны (пусть иногда минутные) простои системы, поэтому если требуется 100% готовность системы и простои даже в течении минуты недопустимы, лучше использовать кластер.
С точки зрения планирования нужно, чтобы приложение было загружено на два сервера (рабочих места). Приведем пример. Для этого один сервер назовем первичным. Второй — запасным, приложение на нем будет неактивным. Затем в консолидированной сетевой системе хранения выделяется область хранения данных приложения, которая затем присваивается первичному серверу. Как только первичный сервер завладеет этой областью и начнет передавать данные, нужно вернуться к управляющему графическому интерфейсу и назначить выделенную область запасному серверу. Последний, естественно, не сможет активировать и смонтировать эту область, так как она занята другим сервером, но в случае сбоя основного сервера передача операций запасному будет несложной. Для этого нужно деактивировать с помощью графического интерфейса управления первичный сервер и отсоединить его от области данных. После активизации запасного сервера на нем запускается приложение – и можно продолжать работу. После восстановления работоспособности первичного сервера область данных переназначается – работа снова продолжается.
Добиться того же самого можно при помощи репликации или кластеризации. В первом случае необходима дополнительная система хранения. Кроме того, при репликации будут использоваться ресурсы процессора на обоих серверах и пропускная способность сети. Если первичный сервер доступен, может возникнуть проблема при передаче управления в результате сбоя одного из серверов. При кластеризации процесс происходит автоматически, функция failover работает в реальном времени.
Однако стоимость кластеризации (аппаратные и программные средства) может быть довольно высока. Основной недостаток централизованного сетевого хранения – бездействующий сервер, который находится в ожидании сбоя одного из приложений. В случае сбоя этот сервер сможет перехватить функции любого из работающих серверов.
Проектирование инфраструктуры
Главным компонентом IP -сети хранения является ее инфраструктура. Напомню, IP -системы хранения работают с существующей IP -сетью, в то время как традиционные сети FC SAN требуют новой дорогостоящей инфраструктуры.
Проектирование IP -сети для нужд хранения – процесс несложный. Для большинства сред первоначальные фазы установки оборудования не требуют перекомпоновки сети, к ней подключается устройство и выделяются ресурсы хранения данных. Это особенно актуально для тех сред, где уже, допустим, есть Gigabit Ethernet. Большинство сегментов гигабитной сети в компаниях недозагружены, уровень загрузки обычно ниже 30%. Поэтому добавление устройств хранения поднимет уровень загрузки сети примерно до 50% ее пропускной способности.
По мере развития сети, добавления новых устройств хранения и увеличения интенсивности использования систем хранения данных будет увеличиваться нагрузка на сеть. В этом случае разумно выделить трафик хранения данных в обособленную сеть ( V - LAN или частная сеть), но для этого нужна система резервного копирования на базе IP. Затем следует установить в сервер (серверы) вторую сетевую карту. Обычно для основного сетевого доступа используют сеть Ethernet 100 BaseT, а для доступа к сети хранения пользуются картой Gigabit Ethernet. В отличие от сетей хранения на основе FC стоимость этого процесса значительно ниже: обычно карта Gigabit Ethernet стоит не дороже $350, в то время как средняя цена контроллера Fibre Channel составляет около $1,3 тыс.
Заключительный шаг, помогающий увеличить производительность системы хранения — расширение возможностей сетевой карты. Существуют сетевые карты ( TCP Offload Engine – TOE ), которые снимают с центрального процессора функцию обработки стека IP и выполняют ее аппаратно.
В случае выполнения задач только хранения данных наблюдается небольшой прирост производительности. Однако если предполагаются и другие функции (резервное копирование, файловые службы), применение карт TOE будет более чем оправдано (стоимость карты TOE составляет примерно $700).
Выбор сервера
Реализация IP SAN не должна повлечь дополнительных затрат на серверы. Дело в том, что нередко проекты по консолидации систем хранения выполняются параллельно с проектами по консолидации серверов, поэтому требуется, прежде всего, изменение физических размеров закупаемых серверов. Допустимо применение серверов форм-фактора 1 U или 2 U, так как необходимости в большой собственной дисковой памяти нет. При увеличении количества задач или необходимости обслуживания большего числа пользователей можно расширить возможности серверов (например, использовать больше почтовых ящиков на каждом сервере электронной почты). Тем самым часть операций чтения/записи диска перекладывается на IP -систему хранения. Кроме того, сегодня пользователи стали чаще приобретать так называемые «лезвия», которые позволяют в небольшом объеме разместить достаточно много серверов.
Одна из слабых сторон сетей IP SAN в сравнении с FC SAN – невозможность прямой загрузки из пула хранения. Эта особенность FC SAN предоставляет большую гибкость и доступность серверов. Правда, сегодня это не очень критично, так как серверы большинства пользователей (даже в FC SAN ) загружают ОС с собственных локальных дисков.
Встречаются также случаи, когда очень сложно организовать и управлять процессом загрузки операционной системы из SAN.
Защита данных
Способы и приемы защиты информации в сетях IP SAN аналогичны используемым в традиционных сетях FC SAN. Для того, чтобы воспользоваться всей пропускной способностью среды, сети FC SAN требуют наличия в ПО резервного копирования дорогостоящего программного модуля (обычно называемого сервером устройства). Эти серверы устройств служат «поднаборами» кодов, которыми пользуется сервер резервного копирования, и увеличивают стоимость клиента на 50-75%.
Сюда же следует прибавить стоимость подключения сервера к сети FC SAN (стоимость контроллера и порта в коммутаторе FC ). Для корректной реализации резервного копирования в среде FC SAN требуется серьезная переработка архитектуры.
Сети IP SAN обычно не нуждаются в серверах устройств, хотя и могут их использовать. Стандартный клиент резервного копирования будет функционировать с хорошей производительностью, так как используется существующая инфраструктура IP. Кроме того, не требуется изменение процессов резервного копирования, выполняемых пользователем (в худшем случае — изменения минимальны).
Подключение к сети FC SAN библиотеки магнитных лент также весьма дорогостоящее мероприятие. Обычно для этого используют FC -маршрутизаторы (ценой от $10 тыс.), которые порой работают весьма непредсказуемо. Для сетей IP SAN, как уже было сказано, текущие процессы резервного копирования менять практически не нужно.
Если нужно установить ленточное устройство совместного доступа, то имеет смысл обратить внимание на библиотеки, оборудованные IP, которые уже зарекомендовали себя как наиболее надежные решения. Основное преимущество такого подхода – распределение нагрузки резервного копирования между несколькими серверами. Отдельный сервер резервного копирования с подключенной непосредственно к нему библиотекой может не справиться с потоком данных, приходящим одновременно от нескольких серверов.
Защиту удаленных систем хранения организовать не сложно: нужно поставить IP -систему хранения в удаленное место и организовать репликацию данных обратно в центр данных. Дополнительное управление хранением и защитой данных при таком подходе не потребуется.
Сравнение стоимости
Повторим, что сети на базе IP обладают меньшей стоимостью развертывания по сравнению с FC SAN. Основная часть средств экономится на самой сетевой инфраструктуре. Так, стоимость коммутаторов FC сейчас составляет примерно $1,2 тыс. за порт. Для гигабитной IP -сети стоимость одного порта коммутатора равна $300. Стоимость устанавливаемых в серверы контроллеров для FC SAN лежит в пределах $1500 – $2000, а средняя стоимость контроллера для IP SAN — всего $350.
Обычно в критически важных случаях с целью дублирования в сервер ставят два контроллера. Таким образом стоимость подключения одного сервера к сети FC SAN составит около $5,4 тыс., а для подключения к IP SAN потребуется $1,3 тыс. Если посчитать разницу в стоимости подключения для нескольких серверов, то получится внушительная сумма.
Типы реализации
Сети IP SAN применяются в трех сегментах рынка: начальный, или рабочие группы (объемы данных до 1 T байт), средний (обычно до 10 T байт данных) и корпоративный (объемы более 10 T байт).
В сегменте начального уровня представлены базовые системы, которые предоставляют возможность преобразования SCSI или FC в IP SAN. Одно из достоинств таких решений в том, что в сети IP SAN можно использовать практически любой SCSI - или FC -массив. Но набор «сетевых» возможностей таких систем ограничен: например, функции динамического увеличения объема, снэпшотов, репликации данных для сетей IP SAN начального уровня недоступны. Еще один недостаток этого типа решений – неприятие его рынком. На первый взгляд, казалось бы, пользователям должна понравиться свобода выбора, свойственная таким решениям. И действительно, за последние несколько лет продукты типа головных NAS -устройств, виртуализаторов SAN периодически появлялись на рынке, теперь представлены и виртуализаторы IP, но, в основном, они не приняты.
Наиболее привлекательны сети IP SAN для небольших и средних корпоративных систем. Это обширный сегмент, где есть место для всех поставщиков систем хранения. Чаще пользователи ищут решение для создания своей первой SAN, пока никаких затрат на сеть еще не сделано, но требуются довольно серьезные возможности, типа снэпшотов. Реализации IP SAN с таким фунционалом в принципе доступны. Обычно это комплект устройств от одного поставщика.
В сегменте больших корпоративных систем многие пользователи уже имеют сеть SAN (иногда даже несколько). Ожидается, что сети IP SAN (ввиду меньшей стоимости подключения) позволят ускорить процесс развития и распространения сетей хранения данных.В этом случае потребуются маршрутизирующие устройства для мапирования FC в IP. Такая смешанная модель позволит повысить эффективность уже сделанных вложений в инфраструктуру сети хранения.
С точки зрения развития и применения IP в качестве транспортной среды для хранения данных можно сказать, что это будет основа стратегий консолидации хранения информации. Хоть и на многих предприятиях сети IP SAN будут лишь дополнением инфраструктуры Fibre Channel, но и SAN, построенные только на IP, будут отнюдь не редкостью. Очевидно, что IP имеет все возможности для того, чтобы действительно стать транспортной средой для хранения данных.
Computer Associates
Свою стратегию в области управления хранением компания Computer Associates назвала Enterprise Storage Automation. Сверхзадачи те же: дать администратору возможность управлять разнородной инфраструктурой как единым ресурсом, автоматизировать выполнение операций по контролю систем хранения на основе корпоративных политик, обеспечить инструменты, позволяющие предоставлять ресурсы хранения как услуги для бизнес-пользователей. Подход СА, пожалуй, отличает стремление создать управляющую платформу с максимальной поддержкой решений от разных поставщиков. Для этого предоставляются интерфейсы, инструментарий SDK и другие механизмы, открывающие доступ к общим службам, которые лежат в основе всех семейств продуктов управления от СА. Кроме того, компания проводит активную политику партнерства с ведущими игроками рынка систем хранения: ЕМС, Brocade, Emulex и Network Appliance.
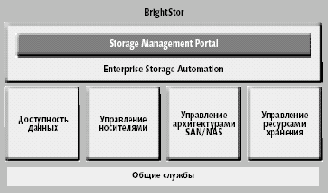
В прошлом году СА объединила свои продукты по управлению хранением под маркой BrightStor (рис. 2), а в апреле этого представила новую классификацию решений, входящих в семейство BrightStor: обеспечение доступности данных, управление съемными носителями, управление SAN и NAS, управление ресурсами хранения.
 | |
|
Рис. 2. Архитектура СА BrightStor |
Средоточием централизованного управления хранением призван стать портал BrightStor Portal, позволяющий интегрировать на базе единого интерфейса всю информацию, приложения и другие элементы управления разнородными системами. BrightStor Portal на базе Windows 2000 обеспечивает доступ ко всем инструментам и информации, необходимой администратору инфраструктуры хранения для того, чтобы устанавливать и реализовывать согласованную политику доступа, планировать емкость хранения, задавать пороговые значения, контролировать производительность, получать отчеты, осуществлять централизованное управление резервированием на разных платформах и т.д.
К категории систем для поддержки доступности данных СА отнесла продукты по резервированию/восстановлению данных, среди которых система ArcServe [5] для рабочих групп и департаментов и анонсированное прошлым летом решение BrightStor Entreprise Backup, ориентированное на резервное копирование в крупномасштабных центрах данных.
Эта система формирует домены, каждый из которых контролируется своим сервером резервирования, но все они объединяются под управлением с общей консоли. Интересно, что в домен могут входить системы с разными операционными системами, которые будут резервироваться по единым для данного домена правилам с едиными параметрами защиты. В BrightStor Entreprise Backup реализован ряд механизмов, нацеленных на максимальное сокращение «окна резервирования», в том числе многопотоковое резервирование, резервирование на диск для быстрого восстановления, копирование «мгновенных снимков» на дисковых массивах.
BrightStor Entreprise Backup поддерживает специальный «календарь» планирования операций резервирования, позволяет определять политики ротации магнитных лент и предоставляет различные средства генерации отчетов по процессам резервирования, состоянию устройств и носителей. BrightStor Entreprise Backup использует возможности сети хранения по разделению устройств хранения, динамическому назначению ленточных библиотек разнородным серверам и резервированию в обход серверов и локальной сети. Система также реализует несколько механизмов резервирования для NAS-конфигураций: с файлового сервера NAS непосредственно на ленту, через сервер резервирования и посредством другого файлового сервера. Как и другие, BrightStor Entreprise Backup обеспечивает разнообразные возможности для сохранения данных из основных почтовых систем, баз данных и приложений корпоративного управления. В эту же систему входят возможности по управлению носителями, включая управление хранилищами на лентах, создание пулов носителей и экспорт архивов на лентах за пределы рабочих помещений. Семейство BrightStor включает также программные средства виртуализации хранения на лентах Vtape для оптимизации использования ленточных библиотек.
BrightStor SAN Manager базируется на возможностях флагманского продукта СА — Unicenter. Интеграция со средствами Unicenter по управлению производительностью, уровнем обслуживания, событиями, гарантирует качество работы соответствующих функций BrightStor SAN Manager.
Так, например, BrightStor SAN Manager Event Console автоматизирует обработку событий без написания сложных скриптов, опираясь на соответствующие инструменты Unicenter. Используется технология Unicenter по представлению ИТ-ресурсов через призму бизнес-процессов — Business Process View (BPV). Благодаря этому элементы сети хранения могут группироваться по их отношению к определенным бизнес-подразделениям компании, по отношению к ERP-приложениям или областям физического размещения устройств, так что администратор сразу увидит, какое влияние те или иные проблемы в SAN окажут на решение деловых задач. BrightStor SAN Manager интегрируется с программами управления отдельными элементами сети хранения от разных поставщиков и одновременно использует открытые стандарты для SAN, благодаря чему поддерживаются разнообразные средства обнаружения и мониторинга компонентов сети хранения: вне- и внутриполосные методы, SNMP, запросы по SCSI, Host Base Adapter API и частные интерфейсы для коммуникационных элементов и устройств хранения. Помимо автоматического обнаружения устройств в сети хранения, BrightStor SAN Manager решает задачи зонирования, присвоения логических устройств хост-серверам, визуализации представления SAN, мониторинга производительности передачи данных по различным маршрутам в сети хранения и выбора оптимальных маршрутов и др.
BrightStor Storage Resource Manager (SRM) поддерживает централизованное управление ресурсами хранения, как в сетевой конфигурации, так и для мэйнфреймов. В его функции входят анализ событий, планирование и автоматизация процессов управления, планирование емкости хранения, управление размещением ресурсов и контроль использования дискового пространства. Технология серверов BrightStor SRM Application Servers, отвечающих за выполнение операций по управлению ресурсами в своем домене, позволяет распространить управление ресурсами хранения на географически разнесенные подразделения. Контроль доменов в глобальном масштабе консолидируется с помощью BrightStor Portal, с которым интегрируется BrightStor SRM.
ЕМС
Комплексные решения по управлению хранением от ведущих поставщиков в той или иной степени удовлетворяют требованиям SNIA: архитектура «менеджер-агенты»; единый интерфейс; общая модель обнаружения и регистрации разнородных ресурсов; возможность формирования доменов управления, отражающих оргструктуру компании и ее географическую распределенность; поддержка различных методов обнаружения ресурсов; обмен сообщениями о событиях по стандартным протоколам; общий репозитарий данных об управляемых объектах. Однако остается одна большая проблема — реальная поддержка гетерогенных сред. Аналитики уверены, что предлагаемые решения, несмотря на декларированные возможности работы с устройствами и системами хранения от разных поставщиков, на деле не всегда такую поддержку обеспечивают в силу отсутствия единых стандартов работы с очень разным оборудованием. В самом деле, из OpenView не удастся следить за дисковыми массивами IBM, а Тivoli не поддерживает систем хранения от НР. Хотя может предоставляться инструментарий разработчика, чтобы такую поддержку реализовать, но это потребует дополнительных усилий. SNIA предлагает стандартную модель управления CIM (common information model), которая определяет общие правила описания объектной модели ресурса хранения на базе языка UML и позволяет унифицировать механизм доступа управляющих приложений к оборудованию хранения. Но далеко не все производители эту модель используют.
Решение проблемы предложила ЕМС, лидер рынка систем хранения, которая, впрочем, до последнего времени не озадачивалась разработкой универсальных механизмов управления. Компания анонсировала новую программную архитектуру управления AutoIS, ключевым элементом которой стала система WideSky — первая в отрасли технология промежуточного слоя для управления системами хранения. WideSky располагается между управляющими приложениями и устройствами хранения и выступает в роли транслятора, который позволяет программным модулям управления взаимодействовать с дисковыми массивами, коммутаторами и другими элементами инфраструктуры хранения разных поставщиков без специального кодирования для каждого типа оборудования.
Для этого WideSky преобразует частные интерфейсы доступа к системам хранения и коммуникационным компонентам в набор общих интерфейсов, которые подразделяются на три основные группы (Рис. 3).
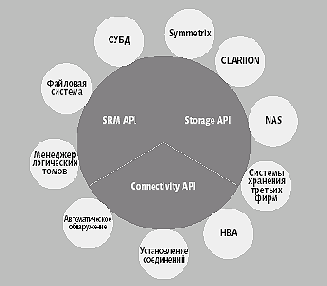 |
Рис. 3. Интерфейсы WideSky |
Вместе с WideSky ЕМС представила систему Control Center/Open Edition (ECC/OE), которая выполняет функции консоли централизованного управления ресурсами хранения и одновременно — платформы для интеграции разных управляющих приложений. ЕСС/ОЕ собирает информацию с разных устройств и хранит их в реляционной базе данных Oracle, доступной другим модулям управления. В рамках AutoIS ЕМС анонсировала и два собственных продукта управления, интегрируемых в ЕСС/ОЕ: StorageScope и Replication Manager. Первый реализует ряд функций SRM, а второй предоставляет единую методологию и графический интерфейс для управления процессами репликации данных на разных платформах.
WideSky и AutoIS — не только технологии, но и стратегические инициативы ЕМС. Компания предлагает производителям оборудования и разработчикам управляющих систем открыть свои интерфейсы для WideSky, в обмен получив возможность использовать интерфейсы этого промежуточного слоя, и интегрировать свои управляющие модули в ЕСС/ОЕ. ЕМС стремится выпустить на рынок механизм, который раз и навсегда решит проблему интероперабельности. Вопрос в том, как партнеры и конкуренты отреагируют на предложения ЕМС. На сегодняшний день среди производителей оборудования только Compaq, McData и Brocade подписали лицензионные соглашения с ЕМС в отношении WideSky, а на платформе ЕСС/ОЕ работают пока только модули StorageScope и Replication Manager и приложения по управлению дисковыми подсистемами от ЕМС.
IBM, НР и СА не хотят отдавать ЕМС лавры объединителя рынка, Veritas выступает с собственными предложениями по созданию промежуточного программного обеспечения для управления хранением. Но этот факт лишь подтверждает востребованность таких решений. Пользователь, конечно, только выиграет, если производители все же найдут путь к согласию. Завтрашний день программного обеспечения управления хранением — это многофункциональные платформы управления гетерогенными ресурсами.
Литература
[1] Наталья Дубова, SAN и NAS на пути к сближению. «Открытые системы», 2002, № 4
[2] Jon Toigo, Can EMC solve the storage management dilemma? http://searchstorage.techtarget.com/originalContent/0,289142,sid5_gci788669,00.html
[3] John Tyrrell, IBM, Mike Dutch, Hitachi Data Systems, Steve Terwilliger, Amdahl. Storage Resource Management Requirements for Disk Storage. SNIA White Paper V3.2. http://www.snia.org
[4] Storage Resource Management: key to managing storage in the 21st century. Aberdeen Group. An executive white paper. 2000, May
[5] Наталья Дубова, Система резервирования ArcServe 2000. «Открытые системы», 2001, № 1
IBM
В семействе программных продуктов по ИТ-управлению Tivoli от IBM большинство функций по управлению хранением сосредоточены в модуле Tivoli Storage Manager и нескольких дополнительных приложениях. Tivoli Storage Manager решает, прежде всего, задачи резервного копирования и восстановления данных, но в комплексе с модулями Disaster Recovery Manager, Space Manager и Data Protection поддерживает восстановление информационной системы в случае глобальных катастроф, управление иерархическим хранением и оперативное сохранение баз данных без прерывания их работы.
Tivoli Storage Manager обеспечивает централизованное управление процедурами сохранения/восстановления данных в гетерогенных средах — локальных и глобальных, а также непосредственно в SAN. В Storage Manager реализована технология резервного копирования, которая выполняет эту процедуру только для новых и модифицированных файлов, благодаря чему достигается экономия времени и дискового пространства. Использование собственной реляционной базы данных для отслеживания данных позволяет достичь прямого восстановления файла за один шаг. Высокая производительность резервирования/восстановления достигается за счет совместного использования одной и той же ленточной библиотеки несколькими серверами Storage Manager, что влияет и на эффективность использования библиотек.
Tivoli Storage Manager поддерживает высокоскоростное восстановление данных непосредственно с ленты или CD-ROM, минимизируя время восстановления, поскольку ресурсы сети и центрального сервера резервирования не задействованы. Кроме того, предусмотрена возможность перемещения данных (для резервирования, архивирования и восстановления) непосредственно в сети хранения, минуя локальную сеть, что позволяет повысить пропускную способность IP-соединений. Еще одна интересная особенность Storage Manager — адаптивная дифференциальная технология резервного копирования данных, позволяющая включить в процесс резервирования мобильных и других пользователей, которым необходим минимальный объем передачи данных и максимально короткий промежуток времени на резервирование.
После первоначального копирования целого файла адаптивная технология создает резервную копию только той части файла, которая подверглась изменению.
Tivoli Disaster Recovery Manager — инструмент защиты данных в случае катастроф, когда в обстановке нервозности и паники необходима поддержка системы, автоматизирующей реализацию четкого и заранее определенного плана действий. Сервер Disaster Recovery Manager интегрирован с сервером Storage Manager и работает под его управлением. Этот компонент отслеживает и контролирует все перемещения носителей с резервными копиями, что позволяет в случае возникновения критической ситуации быстро определить их местоположение. Кроме того, функции отслеживания клиентов позволяют выявлять уничтоженные системы и определять аппаратное и программное обеспечение, необходимое для восстановления поврежденного оборудования. Disaster Recovery Manager автоматизирует основные действия по восстановлению нормальной работы в порядке заданных приоритетов.
Tivoli Space Manager — пример средства управления дисковым пространством, позволяющего создать иерархию внешней памяти, в которой редко используемые файлы автоматически перемещаются в альтернативное хранилище с более низкой стоимостью хранения. Такая автоматизация миграции файлов освобождает администраторов и пользователей от необходимости вручную «чистить» файловые системы и обеспечивает достаточный объем свободного рабочего дискового пространства без приобретения дополнительных дисков. Для того чтобы реализовать автоматическое перемещение, пользователь системы задает определенные критерии для файлов, которые не должны занимать место в файловой системе. Такие файлы перемещаются на сервер Tivoli Storage Manager, который сохранит их в соответствии с действующей стратегией резервирования/архивирования. Вместо перемещенного файла на клиенте Tivoli Space Manager создается фиктивный файл с теми же самыми атрибутами, который имитирует наличие исходного файла в системе и позволяет быстро восстановить этот файл в случае, если какое-то приложение к нему обратится.
В семейство Tivoli Data Protection входят модули для оперативного резервирования/восстановления часто используемых приложений и серверов баз данных. Дополнительные возможности для генерации отчетов и анализа событий, производительности и использования емкости хранения данных предоставляет модуль Tivoli Decision Support for Storage Management Analysis.
В семейство интегрированных приложений Tivoli входит также специальное решение для развертывания и эксплуатации SAN и связанных с ними ресурсов хранения Tivoli Storage Network Manager, в котором реализованы многие принципы полномасштабного управления ресурсами. Storage Network Manager обеспечивает распознавание топологии SAN и отображение на экране управляющей консоли компонентов и ресурсов хранения по всей сети SAN. Для такого распознавания используются различные механизмы обнаружения: «внутриполосной» (in-band) по самой сети SAN и «внеполосной» (out-of-band) по протоколу SNMP, различные технологии, позволяющие охватить стандартные компоненты различных производителей. Топология представляется как на физическом, так и на логическом уровне.
Следующий после распознавания топологии шаг в управлении SAN — выделение обнаруженных дисковых ресурсов приложениям. Tivoli Storage Network Manager позволяет присваивать серверам ресурсы с разнородных подсистем хранения на уровне логических устройств хранения. Назначенные логические устройства форматируются файловой системой соответствующего хоста и предоставляются в его монопольное распоряжение. Выделенные ресурсы непрерывно отслеживаются и их объемы будут автоматически увеличены при достижении заданного порога. Для этого идентифицируются и форматируются свободные логические устройства, неиспользуемые никакой файловой системой. Storage Network Manager позволяет устанавливать правила расходования емкости хранения для всей сети хранения, групп компьютеров, отдельных хостов и файловых систем.
Модуль управления SAN обеспечивает постоянный мониторинг всех компонентов в рамках распознанной топологии, получение необходимых для отчетов данных и добавление новых элементов.По результатам обработки информации о возникших проблемах Storage Network Manager имеет возможность запустить специфическое ПО управления данным элементом сети хранения для устранения сбоев. Также этот модуль может инициировать приложения для настройки производительности компонентов сети хранения в ходе ее начальной установки. Storage Network Manager интегрируется с модулем общего сетевого управления Tivoli NetView.
Недавно IBM анонсировала планы по созданию уникальной файловой системы Storage Tank, оптимизированной для доступа, сохранения, разделения и управления файлами в сетях хранения.
Классификация
Выделить основные категории программных систем управления хранением непросто, поскольку в разных источниках они классифицируются по-разному, а производители склонны по-своему группировать собственные разработки. Ведущая организация по стандартизации в области сетевого хранения Storage Networking Industry Association определяет три основные группы дисциплин управления ресурсами хранения [3]:
проактивное планирование; реактивный мониторинг; оперативное обслуживание.
Под ресурсами хранения здесь подразумеваются все возможные компоненты корпоративных систем хранения: различные типы дисковой памяти, включая высокоуровневые интеллектуальные устройства, массивы RAID, JBOD, носители на магнитных лентах, в том числе ленточные библиотеки, носители на оптических дисках, конфигурации SAN и NAS, сетевые компоненты и интерфейсы для подсоединения устройств внешней памяти и организации сетей хранения (Fibre Channel, SCSI, ESCON и др.).
Первая категория дисциплин управления включает в себя: управление активами хранения, управление конфигурацией и планирование емкости. Задачи текущего мониторинга систем хранения решают следующие дисциплины управления: управление событиями, управление производительностью, управление квотами памяти, управление проблемами. Обеспечить надлежащий уровень информационных служб со стороны корпоративной инфраструктуры хранения позволяют такие дисциплины, как:
управление политиками; автоматизация процессов управления на основе политик; управление хранением (резервирование/архивирование, управление иерархическим хранением, восстановление данных после катастроф, управление системами хранения со встроенными средствами перемещения данных).
В Aberdeen Group перегруппировывают большинство из перечисленных дисциплин в четыре базовые категории.
Размещение данных - программные средства для физического, логического и виртуального перемещения и размещения данных на различных носителях и их выборки, например, создания пулов внешней памяти для более эффективного использования ресурсов хранения. Защита данных - системы резервирования/восстановления и синхронного удаленного зеркалирования, обеспечивающие надежность и постоянную доступность ресурсов. Администрирование систем хранения - управляющие модули, которые отвечают за базовую аппаратную конфигурацию систем хранения и задачи по обеспечению их безопасности. Управление ресурсами хранения (storage resource management, SRM) - средства централизованного мониторинга активов инфраструктуры хранения, анализа их используемости и измерения производительности, а также выполнения ряда других функций, которые обеспечивают предоставление необходимых ресурсов хранения приложениям и позволяют превратить корпоративные системы хранения в услугу для бизнес-подразделений.
Последней категории уделяется особое внимание, поскольку именно средства SRM обеспечивают фактическое управление инфраструктурой хранения на оперативном, тактическом и стратегическом уровнях. Реализация функций SRM позволяет отслеживать и оперативно реагировать на сбои в системах хранения, планировать приобретение и развертывание ресурсов хранения и принимать стратегические решения по конфигурации глобальной корпоративной инфраструктуры хранения. По существу, именно на уровне SRM реализуются основные дисциплины ИТ-управления для систем хранения: управление развертыванием и конфигурированием, обеспечение доступности инфраструктуры хранения, оперативная поддержка ресурсов хранения. Дисциплины SRM осуществляют корреляцию логического представления ресурсов данных в приложениях с физическими «конструкциями» систем хранения, обеспечивая централизованное управление системами хранения как на уровне битов данных на физических носителях, так и на уровне логических структур, с которыми работают приложения. Основой для такого управления являются метаданные, собираемые с помощью программных агентов на каждом управляемом объекте хранения, включая файлы (размер, дата создания и владелец) и аппаратные компоненты инфраструктуры (например, емкость и производительность).
По определению Aberdeen [4] к категории SRM относятся такие дисциплины управления хранением, как управление активами хранения (asset management), планирование емкости хранения, управление конфигурацией, управление событиями, управление производительностью, предоставление информации об обеспечении непрерывности бизнеса (business continuity reporting) и управление использованием дискового пространства (space usage management).
В функции управления активами хранения входят обнаружение и регистрация ресурсов внешней памяти, определение типа ресурса (интеллектуальный дисковый массив с многоплатформной поддержкой, FC-коммутатор, виртуальный сервер хранения на магнитных лентах и т.д.) и определение места ресурса в общей топологии инфраструктуры хранения.
Наличие топологической карты инфраструктуры хранения позволяет анализировать, как изменения в топологии повлияют на другие характеристики, например, производительность и емкость.
Средства планирования емкости хранения должны уметь анализировать тенденции и прогнозировать потребности корпоративных приложений в ресурсах хранения, гарантируя тем самым, что нужные объемы памяти и производительность сети хранения будут всегда в наличии. Они предоставляют информацию о свободном пространстве на дисках, незадействованных томах, свободном и занятом пространстве, мощностях коммутаторов, числе адаптеров и портов и другие сведения, позволяющие оценить пропускную способность сети хранения.
Средства управления конфигурациями, событиями и производительностью решают задачи повседневного, оперативного управления. Модуль управления конфигурацией в идеале должен поддерживать общий интерфейс для конфигурирования ресурсов хранения различных типов. Эта задача является одной из наиболее сложных в силу большого количества разновидностей таких ресурсов. В функции модулей управления конфигурацией входит обеспечение оптимальной для данной среды конфигурации дисковых систем, например, задание числа активных подключений к хостам или уровня RAID, определение топологических характеристик сетей хранения и т.д.
Управление событиями обеспечивает диагностику и корректировку сбоев в системах хранения: сбои на дисках или угроза превышения доступной свободной емкости, и закладывает базу для проактивного управления доступностью ресурсов памяти. Анализ данных о сбоях позволяет выявлять систематически повторяющиеся проблемные ситуации и предотвращать их. Например, определенное количество ошибок ввода/вывода на данную ленту может инициировать автоматическое монтирование чистого картриджа.
Управление производительностью помогает с максимальной полнотой реализовать потенциал среды хранения, обеспечивая оптимальную производительность ресурсов хранения в рамках физических пределов. К этой дисциплине относится анализ производительности интерфейсов ввода/вывода и перегрузки кэша, управление зонированием в сетях хранения и другие аналитические возможности.
Правда, отсутствие общих интероперабельных интерфейсов для доступа к информации о производительности компонентов среды хранения от разных поставщиков не позволяет сделать анализ производительности более детальным, способным выявлять платформы, приложения и файлы, породившие проблемы с производительностью.
Инструментарий по сбору информации об обеспечении непрерывной поддержки бизнес-приложений предоставляет возможность централизованного контроля за операциями резервирования, которых может быть несколько — для разных операционных платформ. Программные средства этого типа следят за тем, какие критичные данные не резервируются, насколько быстро те или иные данные должны быть восстановлены, какие серверы резервирования превысили выделенные им лимиты времени на резервирование, где процессы резервирования/восстановления порождают узкие места производительности и т.д. Они помогают также в планировании операций резервирования, зеркалирования и создания удаленных копий данных — тех процессов, которые играют ключевую роль в поддержке постоянной доступности информационных хранилищ.
Управление использованием дискового пространства — новое качество систем управления иерархическим хранением, предусматривающее анализ с целью выявления неиспользуемой памяти на дисках. По результатам такого анализа появляется возможность оптимизировать размещение данных в дисковых подсистемах. Кроме того, эти программные средства позволяют выстроить политику миграции файлов, ранжируя данные по степени их использования. Часть данных, возможно, придется вообще удалить, часть будет перемещена на более медленные носители, какая-то информация разместится в библиотеке магнитных лент с высокой частотой восстановления, а какая-то уйдет в долговременный архив.
Системы хранения находятся в тесной взаимосвязи с остальными компонентами ИТ-инфраструктуры — серверами, сетями, приложениями, базами данных и операционными системами. Комплексные решения по управлению хранением — неотъемлемая часть интегрированных систем общего ИТ-управления.Мы не говорим здесь о специализированном ПО конфигурации и управления отдельными системами хранения или сетями хранения, которые предоставляют производители аппаратных компонентов. Эти программные модули часто являются поставщиками информации для систем управления более высокого уровня.
SNIA и Aberdeen Group предлагают эталонные модели комплексных систем по управлению корпоративными системами хранения. Их основные характеристики: наличие централизованной консоли для контроля за всеми процессами управления хранением, единое хранилище метаданных об управляемых объектах, архитектура «менеджер-агенты», наличие эффективных аналитических средств для обработки собранных данных, кросс-платформное управление.
Теперь обратимся к конкретным реализациям функций по управлению хранением разных поставщиков.
Нewlett-Packard
В области хранения данных компания Hewlett-Pаckard придерживается стратегии Federated Storage Area Management (FSAM), основополагающая идея которой —реализация управления всем многообразием распределенных корпоративных ресурсов хранения на основе представления этих ресурсов как единого пула, управляемого из одного центра с помощью общих правил, независимо от типов и производителей устройств и используемых архитектур. FSAM включает весь спектр аппаратного оборудования для хранения данных, управляющее ПО и сервис от НР. Но поскольку ключевой идеей FSAM является повышение эффективности управления, важнейшими компонентами стратегии становятся программные продукты для управления системами хранения, входящие в семейство OpenView (Рис. 1), которое можно назвать первопроходцем в вопросах реализации сервисного подхода к ИТ-управлению. В FSAM одной из базовых идей является возможность предоставления объединенных ресурсов хранения как услуги для бизнес-пользователей. Поддерживающий многие из функций SRM пакет приложений OpenView Storage Area Manager закладывает основу для реализации этой идеи.
 | |
|
Рис. 1. OpenView Storage Node Manager |
OpenView Storage Area Manager состоит из пяти взаимодополняющих приложений по управлению сетями хранения, которые реализуют построение топологической карты SAN, мониторинг компонентов сети, управление на основе событий и ряд других функций. Основным в этой пятерке является модуль Storage Node Manager, выполняющий базовые операции по централизованному обслуживанию корпоративных сетей хранения и реализующий функции управления активами хранения (в терминологии SRM). Storage Node Manager автоматизирует поиск компонентов сети хранения, используя внутри- и внеполосные методы обнаружения устройств, и строит топологическую карту сети, добавляя в нее новые элементы по мере их появления. Топологическую карту можно настроить таким образом, чтобы на ней отображалась организационная структура компании, например, взаимосвязи между отделами. Сразу после обнаружения модуль переходит к непрерывному мониторингу компонентов и генерирует оповещения обо всех случаях угрозы их работоспособности, позволяя построить управление ресурсами на принципах предупреждения, а не устранения последствий проблем.
OpenView Storage Allocator позволяет управлять совокупной емкостью хранения, распределяя ресурсы на уровне логических устройств хранения различным хост-серверам. Этот модуль оптимизирует распределение ресурсов, позволяя присваивать незадействованную часть дискового массива другим серверам и создавая пул разнородных ресурсов. Все процессы, связанные с назначением логических устройств серверам, занимают минимальное время, поскольку проходят без перезагрузки хоста и с помощью удобного графического интерфейса.
OpenView Storage Optimizer отвечает за контроль производительности компонентов инфраструктуры хранения. Модуль накапливает данные о работе устройств в виде отчетов, на основе которых реализуется прогнозирование показателей производительности системы. Для каждого контролируемого параметра можно задавать пороговое значение и выдавать соответствующее оповещение администратору при достижении этого значения. Такими критическими значениями могут быть характеристики качества обслуживания, указанные в договорах о предоставлении услуг по хранению данных. Большие объемы собираемых данных позволяют строить более точные прогнозы развития ситуации и давать рекомендации, например, о расширении сети в связи с растущими потребностями компании.
Функции OpenView Storage Builder охватывают локальные ресурсы, в общей сети и в сети хранения и предназначены для анализа степени использования и планирования дискового пространства в масштабе всей распределенной инфраструктуры хранения. Модуль занимается обнаружением временных и редко используемых файлов, которые захватывают дефицитное место на дисках, поддерживает систему раннего оповещения о критическом сокращении свободного дискового пространства, позволяет устанавливать и контролировать индивидуальные квоты хранения для каждого пользователя, выполняет балансировку нагрузки между устройствами хранения в случае добавления к системе новых пользователей, приложений или данных.
OpenView Storage Accountant — средство, которое обеспечивает возможность выставления внутренних счетов за использование систем хранения.
С его помощью можно группировать предоставляемые услуги хранения по уровням обслуживания в зависимости от категории аппаратных устройств и связанных с ними затрат. Так, к разным уровням логично отнести хранилище с высоким уровнем готовности с развитыми возможностями зеркалирования и простое устройство с несколькими независимыми дисками (JBOD). После анализа суммарных затрат стоимость услуг может начисляться пропорционально гигабайто-часам использования дискового пространства.
В семейство HP OpenView входит также решение по управлению резервным копированием Omniback, акцент в котором делается на реализации механизмов сохранности данных таким образом, чтобы не терялась возможность доступа к ним даже в момент резервирования. Время простоев при копировании минимизируется благодаря использованию таких технологий, как резервирование баз данных и приложений в оперативном режиме, копирование открытых файлов, инкрементное копирование баз данных на уровне блоков, работа в кластерных конфигурациях и резервное копирование без участия сервера. Omniback предоставляет общий интерфейс для управления резервным копированием в средах разного масштаба — от одиночного сервера с присоединенным накопителем на магнитной ленте до центров данных с поддержкой разных сетевых архитектур хранения. Для сетей хранения Omniback поддерживает высокопроизводительное резервирование в обход локальной сети.
Управление надежным хранением
Наталья Дубова
20.06.2002
Открытые системы, #06/2002
От сетевой организации внешней памяти сегодня ждут больших преимуществ в производительности, доступности данных, увеличения объемов хранения и масштабируемости, снижения затрат на хранение. Однако все эти ожидания останутся лишь ожиданиями без эффективного инструмента централизованного управления.

Veritas
Продукты Veritas Software решают задачи защиты данных, восстановления в случае катастроф, обеспечения высокого уровня доступности хранилищ данных, а также управления сетями хранения. К системам защиты данных компания Veritas относит наиболее известные серии своих решений для резервирования/восстановления на разных платформах. Семейство NetBackup обеспечивает высокопроизводительное резервирование для разных диалектов Unix, Windows, Novell и Macintosh и включает специальных агентов для резервирования наиболее популярных баз данных. В семейство NetBackup входит решение NetBackup Vault, которое автоматизирует ротацию лент с архивами в удаленные точки для восстановления данных в случае катастроф. NetBackup Storage Migrator решает задачу управления иерархическим хранением. Опция NetBackup Bare Metal Restore минимизирует простои в случае катастрофических повреждений оборудования, поддерживая автоматическую реинсталляцию операционной системы, реконфигурацию системы и восстановление пользовательских данных в сети. Veritas Backup Exec — семейство решений для резервирования на платформе Windows. Veritas Global Data Manager — специальный модуль для централизованного управления множеством удаленных серверов резервирования NetBackup и Backup Ехес.
Группа систем по управлению файлами и томами относится к категории средств обеспечения постоянной доступности дискового хранения. Высокая доступность и восстановление в случае катастроф — задачи, которые призваны решать продукты по управлению данными в кластерах и системы репликации на удаленные узлы по сетям. Среди решений Veritas по управлению сетями хранения центральным можно считать SANPoint Control — средство централизованного контроля операций автоматического обнаружения компонентов SAN, визуализации и администрирования разделения сети хранения на зоны. Новое семейство программных систем ServPoint позволяет преобразовать стандартные серверы общего назначения SPARC/Solaris в совокупности с дисковыми подсистемами в специализированные устройства сетевого хранения NAS или SAN.
Однако сегодня шанс на успех имеет тот, кто в состоянии предложить интегрирующую платформу, а не просто набор решений по управлению хранением. В апреле Veritas анонсировала свою новую стратегию Adaptive Software Architecture. Цели декларируются уже знакомые — перевести управление хранением на уровень предоставления ИТ-услуг, обеспечить централизованное управление единым корпоративным ресурсом хранения, включающим гетерогенные системы. Для создания такой архитектуры Veritas намерена двигаться в трех направлениях. Первое — предоставление средств для поддержки интероперабельности систем от разных поставщиков.
Еще одна составляющая новой архитектуры хранения от Veritas — создание условий для максимально быстрого восстановления. Здесь компания будет развивать свои продукты по защите данных и обеспечению высокой доступности. Предполагается создать новую модель Virtual Backup, которая объединит автономные и оперативные процессы защиты данных, и реализовать принципы адаптивного управления рабочей нагрузкой, благодаря которым удастся перейти от восстановления работоспособности приложений к предотвращению простоев в центрах данных.
Наконец, последний элемент новой стратегии — создание инструментов для реализации сервисного подхода к предоставлению ресурсов хранения. В арсенале Veritas появятся средства SRM.