Управляющая база данных MIB
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Вся управляющая информация для контроля ЭВМ и маршрутизаторами Интернет концентрируется в базе данных MIB (Management Information Base, RFC-1213 или STD0017). Именно эти данные используются протоколом SNMP. Система SNMP состоит из трех частей: менеджера SNMP, агента SNMP и базы данных MIB. Агент SNMP должен находиться резидентно в памяти объекта управления. SNMP-менеджер может быть частью системы управления сетью NMS (Network Management System), что реализуется, например, в маршрутизаторах компании CISCO (CiscoWorks).
MIB определяет, например, что IP программное обеспечение должно хранить число всех октетов, которые приняты любым из сетевых интерфейсов, управляющие программы могут только читать эту информацию.
Согласно нормативам MIB управляющая информация делится на восемь категорий (см. также рис. 4.4.13.1.1):
MIB-категория включает в себя информацию о
| MIB-категория | Описание | Код |
| system | Операционная система ЭВМ или маршрутизатора. | 1 |
| Interfaces | Сетевой интерфейс. | 2 |
| addr.trans | Преобразование адреса (напр., с помощью ARP). | 3 |
| IP | Программная поддержка протоколов Интернет. | 4 |
| ICMP | Программное обеспечение ICMP-протокола. | 5 |
| TCP | Программное обеспечение TCP-протокола. | 6 |
| UDP | Программное обеспечение UDP-протокола. | 7 |
| EGP | Программное обеспечение EGP-протокола. | 8 |
| SNMP | Программное обеспечение SNMP-протокола. | 11 |
Таблица 4.4.13.1.1. Системные переменные MIB
| Системная переменная | Описание | Код |
|
Sysdescr | Текстовое описание объекта; | 1 |
|
Sysobjectid | Идентификатор производителя в рамках дерева 1.3.6.1.4.1 | 2 |
|
Sysuptime | Время с момента последней загрузки системы (timeticks); | 3 |
|
Syscontact | Имя системного менеджера и способы связи с ним; | 4 |
|
Sysname | Полное имя домена; | 5 |
|
Syslocation | Физическое местоположение системы; | 6 |
|
Sysservice |
Величина, которая характеризует услуги, предоставляемые узлом (сумма номеров уровней модели OSI); | 7 |
Таблица 4.4.13.1.2. Переменные IFtable (интерфейсы)
| Переменная описания интерфейсов (iftable) | Тип данных | Описание | ifEntry |
| IFindex | integer | Список интерфейсов от 1 до ifnumber. | 1 |
| IfDescr | displaystring | Текстовое описание интерфейса. | 2 |
| IfType | integer | Тип интерфейса, например, 6 - ethernet; 9 - 802.5 маркерное кольцо; 23 - PPP; 28 - SLIP. | 3 |
| IfNumber | integer | Число сетевых интерфейсов. | |
| IfMTU | integer | mtu для конкретного интерфейса; | 4 |
| IfSpeed | gauge | Скорость в бит/с. | 5 |
| IfPhysaddress | physaddress | Физический адрес или строка нулевой длины для интерфейсов без физического адреса (напр. последовательный). | 6 |
| IfAdminStatus | [1...3] | Требуемое состояние интерфейса: 1 - включен; 2 - выключен; 3 - тестируется. | 7 |
| IfOperStatus | [1...3] | Текущее состояние интерфейса: 1 - включен; 2 - выключен; 3 - тестируется. | 8 |
| IfLastchange | timeticks | Sysuptime, когда интерфейс оказался в данном состоянии. | 9 |
| IfInOctets | counter | Полное число полученных байтов. | 10 |
| IfInUcastpkts | counter | Число пакетов, доставленных на верхний системный уровень (unicast). | 11 |
| IfInNUcastpkts | counter | Число пакетов, доставленных на верхний системный уровень (unicast). | 12 |
| IfInDiscads | counter | Число полученных но отвергнутых пакетов. | 13 |
| IfInErrors | counter | Число пакетов, полученных с ошибкой; | 14 |
| IfInUnknownProtos | counter | Число пакетов, полученных с ошибочным кодом протокола; | 15 |
| IfOutOctets | counter | Число отправленных байтов; | 16 |
| IfOutUcastPkts | counter | Число unicast- пакетов, полученных с верхнего системного уровня; | 17 |
| IfOutNucastPkts | counter | Число мультикастинг- и широковещательных пакетов, полученных с верхнего системного уровня; | 18 |
| IfOutDiscads | counter | Количество отвергнутых пакетов из числа отправленных; | 19 |
| IfOutErrors | counter | Число отправленных пакетов, содержащих ошибки; | 20 |
| IfOutQlen | gauge | Число пакетов в очереди на отправку; | 21 |
/p> Ниже представлена таблица цифро- точечного представления переменных, характеризующих состояние интерфейса. Эта таблица может быть полезной для программистов, занятых проблемами сетевой диагностики.
| Название объекта | Цифра-точечное представление |
| org | 1.3 |
| dod | 1.3.6 |
| internet | 1.3.6.1 |
| directory | 1.3.6.1.1 |
| mgmt | 1.3.6.1.2 |
| experimental | 1.3.6.1.3 |
| private | 1.3.6.1.4 |
| enterprises | 1.3.6.1.4.1 |
| security | 1.3.6.1.5 |
| snmpV2 | 1.3.6.1.6 |
| snmpDomains | 1.3.6.1.6.1 |
| snmpProxys | 1.3.6.1.6.2 |
| snmpModules | 1.3.6.1.6.3 |
| snmpMIB | 1.3.6.1.6.3.1 |
| snmpMIBObjects | 1.3.6.1.6.3.1.1 |
| snmpTraps | 1.3.6.1.6.3.1.1.5 |
| mib-2 | 1.3.6.1.2.1 |
| ifMIB | 1.3.6.1.2.1.31 |
| interfaces | 1.3.6.1.2.1.2 |
| ifMIBObjects | 1.3.6.1.2.1.31.1 |
| ifConformance | 1.3.6.1.2.1.31.2 |
| ifTableLastChange | 1.3.6.1.2.1.31.1.5 |
| ifXTable | 1.3.6.1.2.1.31.1.1 |
| ifStackTable | 1.3.6.1.2.1.31.1.2 |
| ifStackLastChange | 1.3.6.1.2.1.31.1.6 |
| ifRcvAddressTable | 1.3.6.1.2.1.31.1.4 |
| ifTestTable | 1.3.6.1.2.1.31.1.3 |
| ifXEntry | 1.3.6.1.2.1.31.1.1.1 |
| ifName | 1.3.6.1.2.1.31.1.1.1.1 |
| ifInMulticastPkts | 1.3.6.1.2.1.31.1.1.1.2 |
| ifInBroadcastPkts | 1.3.6.1.2.1.31.1.1.1.3 |
| ifOutMulticastPkts | 1.3.6.1.2.1.31.1.1.1.4 |
| ifOutBroadcastPkts | 1.3.6.1.2.1.31.1.1.1.5 |
| ifLinkUpDownTrapEnable | 1.3.6.1.2.1.31.1.1.1.14 |
| ifHighSpeed | 1.3.6.1.2.1.31.1.1.1.15 |
| ifPromiscuousMode | 1.3.6.1.2.1.31.1.1.1.16 |
| ifConnectorPresent | 1.3.6.1.2.1.31.1.1.1.17 |
| ifAlias | 1.3.6.1.2.1.31.1.1.1.18 |
| ifCounterDiscontinuityTime | 1.3.6.1.2.1.31.1.1.1.19 |
| ifStackEntry | 1.3.6.1.2.1.31.1.2.1 |
| ifStackHigherLayer | 1.3.6.1.2.1.31.1.2.1.1 |
| ifStackLowerLayer | 1.3.6.1.2.1.31.1.2.1.2 |
| ifStackStatus | 1.3.6.1.2.1.31.1.2.1.3 |
| ifRcvAddressEntry | 1.3.6.1.2.1.31.1.4.1 |
| ifRcvAddressAddress | 1.3.6.1.2.1.31.1.4.1.1 |
| ifRcvAddressStatus | 1.3.6.1.2.1.31.1.4.1.2 |
| ifRcvAddressType | 1.3.6.1.2.1.31.1.4.1.3 |
| ifTestEntry | 1.3.6.1.2.1.31.1.3.1 |
| ifTestId | 1.3.6.1.2.1.31.1.3.1.1 |
| ifTestStatus | 1.3.6.1.2.1.31.1.3.1.2 |
| ifTestType | 1.3.6.1.2.1.31.1.3.1.3 |
| ifTestResult | 1.3.6.1.2.1.31.1.3.1.4 |
| ifTestCode | 1.3.6.1.2.1.31.1.3.1.5 |
| ifTestOwner | 1.3.6.1.2.1.31.1.3.1.6 |
| ifGroups | 1.3.6.1.2.1.31.2.1 |
| ifCompliances | 1.3.6.1.2.1.31.2.2 |
| ifGeneralInformationGroup | 1.3.6.1.2.1.31.2.1.10 |
| ifFixedLengthGroup | 1.3.6.1.2.1.31.2.1.2 |
| ifHCFixedLengthGroup | 1.3.6.1.2.1.31.2.1.3 |
| ifPacketGroup | 1.3.6.1.2.1.31.2.1.4 |
| ifHCPacketGroup | 1.3.6.1.2.1.31.2.1.5 |
| ifVHCPacketGroup | 1.3.6.1.2.1.31.2.1.6 |
| ifRcvAddressGroup | 1.3.6.1.2.1.31.2.1.7 |
| ifStackGroup2 | 1.3.6.1.2.1.31.2.1.11 |
| ifCounterDiscontinuityGroup | 1.3.6.1.2.1.31.2.1.13 |
| ifGeneralGroup | 1.3.6.1.2.1.31.2.1.1 |
| ifTestGroup | 1.3.6.1.2.1.31.2.1.8 |
| ifStackGroup | 1.3.6.1.2.1.31.2.1.9 |
| ifOldObjectsGroup | 1.3.6.1.2.1.31.2.1.12 |
| ifCompliance2 | 1.3.6.1.2.1.31.2.2.2 |
| ifCompliance | 1.3.6.1.2.1.31.2.2.1 |
| ifNumber | 1.3.6.1.2.1.2.1 |
| ifTable | 1.3.6.1.2.1.2.2 |
| ifEntry | 1.3.6.1.2.1.2.2.1 |
| ifIndex | 1.3.6.1.2.1.2.2.1.1 |
| ifDescr | 1.3.6.1.2.1.2.2.1.2 |
| ifType | 1.3.6.1.2.1.2.2.1.3 |
| ifMtu | 1.3.6.1.2.1.2.2.1.4 |
| ifSpeed | 1.3.6.1.2.1.2.2.1.5 |
| ifPhysAddress | 1.3.6.1.2.1.2.2.1.6 |
| ifAdminStatus | 1.3.6.1.2.1.2.2.1.7 |
| ifOperStatus | 1.3.6.1.2.1.2.2.1.8 |
| ifLastChange | 1.3.6.1.2.1.2.2.1.9 |
| ifInOctets | 1.3.6.1.2.1.2.2.1.10 |
| ifInUcastPkts | 1.3.6.1.2.1.2.2.1.11 |
| ifInNUcastPkts | 1.3.6.1.2.1.2.2.1.12 |
| ifInDiscards | 1.3.6.1.2.1.2.2.1.13 |
| ifInErrors | 1.3.6.1.2.1.2.2.1.14 |
| ifInUnknownProtos | 1.3.6.1.2.1.2.2.1.15 |
| ifOutOctets | 1.3.6.1.2.1.2.2.1.16 |
| ifOutUcastPkts | 1.3.6.1.2.1.2.2.1.17 |
| ifOutNUcastPkts | 1.3.6.1.2.1.2.2.1.18 |
| ifOutDiscards | 1.3.6.1.2.1.2.2.1.19 |
| ifOutErrors | 1.3.6.1.2.1.2.2.1.20 |
| ifOutQLen | 1.3.6.1.2.1.2.2.1.21 |
| ifSpecific | 1.3.6.1.2.1.2.2.1.22 |
Таблица 4.4.13.1.3. Переменные IP-группы
| Переменная IP-группы | Тип данных | Описание | Код |
| ipForwarding | integer | Указание на то, что данный объект осуществляет переадресацию (работает как маршрутизатор). | 1 |
| IPdefaultTTL | integer | Значение, которое использует IP в поле TTL. | 2 |
| IPinreceives | counter | Число полученных дейтограмм. | 3 |
| ipInHdrErrors | counter | Число дейтограмм, отвергнутых из-за ошибок формата или неверных адресов или опций, из-за истекшего TTL. | 4 |
| ipInHdrErrors | counter | Число дейтограмм, отвергнутых из-за неверного IP-адреса, например, 0.0.0.0, или неподдерживаемого класса, например Е. | 5 |
| ipForwDatagrams | counter | Число дейтограмм, для которых данный объект не является местом назначения (маршрутизация отправителя). | 6 |
| ipInUnknownProtos | counter | Число дейтограмм с неподдерживаемым кодом протокола. | 7 |
| ipInDiscards | counter | Число дейтограмм, отвергнутых из-за переполнения буфера. | 8 |
| ipInDelivers | counter | Полное число входных дейтограмм, успешно обработанных на IP-уровне. | 9 |
| ipOutRequests | counter | Полное число IP и ICMP дейтограмм, переданных для отправки. | 10 |
| ipOutRequests | counter | Полное число IP и ICMP дейтограмм, переданных для отправки. | 11 |
| IPoutNoroutes | counter | Число неудач при маршрутизации. | 12 |
| ipReasmTimeout | counter | Максимальное число секунд ожидания сборки фрагментов. | 13 |
| ipReasmReqds | counter | Число полученных фрагментов | 14 |
| ipReasmOKs | counter | Число полученных и успешно собранных IP-дейтограмм | 15 |
| ipReasmFails | counter | Число полученных IP-дейтограмм, которые по тем или иным причинам не удалось собрать | 16 |
| IPFragOKs | counter | Число успешно фрагментированных IP- дейтограмм. | 17 |
| ipFragFails | counter | Число IP- дейтограмм, которые нужно фрагментировать, но сделать это нельзя (например, из-за флага). | 18 |
| ipFragCreates | counter | Число IP-дейтограмм фрагментов, сформированных данным объектом. | 19 |
| ipAddrTable | counter | Таблица адресной информации данного объекта. | 20 |
| ipRouteTable | Последовательность записей маршрутной таблицы | Запись в маршрутной таблице | 21 |
| ipAddrEntry | |||
| IPAdEntAddr | IPaddress | IP-адрес для данного ряда | 1 |
| IPadentifindex | integer | Число интерфейсов. | 2 |
| IPadentnetmask | IPaddress | Маска субсети для данного IP-адреса; | 3 |
| IPAdEntBcastAddr | [0...1] | Значение младшего бита широковещательного адреса (обычно 1); | 4 |
| IPAdEntReasmMaxsize | [0...65535] | Размер наибольшей IP-дейтограммы, полученной интерфейсом, которая может быть собрана. | 5 |
Помимо простых переменных объектами MIB могут быть таблицы. Для каждой таблицы имеется один или несколько индексов.
Таблица 4.4.13.1.4. Переменные TCP-группы
| Переменные TCP-группы | Тип данных | Описание | Код |
| tcpRtoAlgorithm | integer | Алгоритм выявления таймаута для повторной передачи TCP-пакетов: 1 - ни один из следующих; 2 - постоянное RTO; 3 - стандарт MIL-std-1778; 4 - алгоритм Ван Джакобсона | 1 |
| tcpRtoMin | integer | Минимальное допустимое время повторной передачи tcp- пакетов. | 2 |
| tcpRtoMax | integer | Максимальное значение тайм-аута в миллисек. | 3 |
| tcpMaxConn | integer | Максимальное допустимое число tcp-соединений. | 4 |
| tcpActiveOpens | integer | Число TCP-соединений Active-Open | 5 |
| tcpPassiveOpens | integer | Число TCP-соединений Passive-Open (из состояния LISTEN) | 6 |
| tcpAttemptFails | integer | Число неудачных TCP-соединений | 7 |
| tcpEstabResets | integer | Число разрывов TCP-соединений из состояний ESTABLISHED или CLOSE-WAIT | 8 |
| tcpCurrEstab | Gauge | Число TCP-соединений, для которых текущее состояние ESTABLISHED или CLOSE-WAIT | 9 |
| tcpInSegs | counter | Полное число полученных tcp-сегментов. | 10 |
| tcpOutSegs | counter | Полное число посланных сегментов, исключая повторно пересылаемые. | 11 |
| tcpRetransSegs | counter | Полное число повторно пересланных сегментов. | 12 |
| tcpConnTable | counter | Таблица данных специфичных для соединения | 13 |
| tcpInErrs | counter | Полное число сегментов, полученных с ошибкой. | 14 |
| tcpOutRsts | counter | Полное число посланных сегментов с флагом rst=1. | 15 |
| tcpconntable. tcp-таблица связей | |||
| tcpconnstate | [1...12] | Состояние соединения: 1 - closed; 2 - listen; 3 - syn_sent; 4 - syn_rcvd; 5 - established, 6 - fin_wait_1; 7 - fin_wait_2; 8 - close_wait; 9 - last_ack; 10 - closing; 11 - time_wait;, 12 - delete TCB. Только последняя переменная может устанавливаться менеджером, немедленно прерывая связь. | |
tcpconnlocal address | ipaddress | Местный IP-адрес. 0.0.0.0 означает, что приемник готов установить связь через любой из интерфейсов. | |
tcpconnlocal port | [0...65535] | Местный номер порта. | |
tcpconnlocal address | ipaddress | Удаленный ip-адрес. | |
tcpconnrem port | [0...65535] | Удаленный номер порта. | |
/p> Таблица 4.4.13.1.5. Переменные ICMP-группы (тип данных - counter)
Переменная icmp-группы | Описание | Код |
| icmpInMsgs | Полное число полученных ICMP-сообщений. | 1 |
| icmpInErrors | Число ICMP-сообщений, полученных с ошибками. | 2 |
| icmpInDestUnreach | Число ICMP-сообщений о недостижимости адресата. | 3 |
| icmpintimeexcds | Число ICMP-сообщений об истечении времени. | 4 |
| icmpInParmProbs | Число полученных ICMP-сообщений о проблемах с параметрами. | 5 |
| icmpInSrcQuench | Число ICMP-сообщений с требованием сократить или прервать посылку пакетов из-за перегрузки. | 6 |
| icmpInRedirects | Число ICMP-сообщений о переадресации. | 7 |
| icmpInEchos | Число полученных ICMP-запросов отклика. | 8 |
| icmpInEchoReps | Число полученных ICMP-эхо- откликов. | 9 |
| icmpInTimestamps | Число ICMP-запросов временных меток. | 10 |
| icmpInTimestampReps | Число ICMP-откликов временных меток. | 11 |
| icmpInAddrMasks | Число ICMP-запросов адресных масок. | 12 |
| icmpInAddrMaskReps | Число ICMP-откликов на запросы адресных масок. | 13 |
| icmpOutMsgs | Число отправленных ICMP- сообщений. | 14 |
| icmpOutErrors | Число не отправленных ICMP- сообщений из-за проблем в ICMP (напр. нехватка буферов). | 15 |
| icmpOutDestUnreachs | Число ICMP-сообщений о недоступности адресата. | 16 |
| icmpOutTimesExcds | Число посланных ICMP-сообщений об истечении времени. | 17 |
| icmpOutParmProbs | Число посланных ICMP-сообщений о проблемах с параметрами. | 18 |
| icmpOutSrcQuench | Число посланных ICMP-сообщений об уменьшении потока пакетов. | 19 |
| icmpOutRedirects | Число посланных ICMP-сообщений о переадресации. | 20 |
| icmpOutEchos | Число посланных ICMP-эхо-запросов. | 21 |
| icmpOutEchoReps | Число посланных ICMP-эхо-откликов. | 22 |
| icmpOutTimestamps | Число посланных ICMP-запросов временных меток. | 23 |
| icmpOutTimestampReps | Число посланных ICMP-откликов на запросы временных меток. | 24 |
| icmpOutAddrMasks | Число посланных ICMP-запросов адресных масок. | 25 |
Таблица 4.4.13.1.6. Переменные AT-группы (attable, преобразование адресов).
| Переменные at-группы | Тип данных | Описание | atEntry |
| atIfIndex | integer | Число интерфейсов. | 1 |
| atPhysAddress | physaddress | Физический адрес. Если эта переменная равна строке нулевой длины, физический адрес отсутствует. | 2 |
| atNetAddress | networkaddress | IP-адрес. | 3 |
Каждый протокол ( например IP) имеет свою таблицу преобразования адресов. Для IP это ipnettomediatable. Способ пропечатать эту таблицу с помощью программы SNMPI описан ниже.
MIB II содержит управляемые объекты, принадлежащие к группе snmp. SNMP-группа предоставляет информацию о SNMP-объектах, информационных потоках, о статистике ошибок:
| Название объекта | Описание | Код |
| snmpInPkts | Число пакетов, полученных от слоя, расположенного ниже SNMP. | 1 |
| snmpOutPkts | Число пакетов доставленных от SNMP к нижележащему слою. | 2 |
| snmpInBadVersions | Индицирует число PDU, полученных с ошибкой в поле версия. | 3 |
| snmpInBadCommunityNames | Индицирует число PDU, полученных с нечитаемым или нелегальным именем community. | 4 |
| snmpInBadCommunityUses | Полное число SNMP-пакетов, полученных с нечитаемым или нелегальным значение операции для данного имени community. | 5 |
| snmpInAsnParsErrs | Указывает полное число ошибок ASN.1 или BER, которые не могут быть обработаны во входных SNMP-сообщениях | 6 |
| snmpInTooBigs | Указывает число полученных PDU со слишком большим значением поля статус ошибки. | 8 |
| snmpInNoSuchNames | Указывает число PDU, полученных с индикацией ошибки в поле nosuchname. | 9 |
| snmpInBadValues | Указывает число PDU, полученных с индикацией ошибки в поле badvalue. | 10 |
| snmpInReadOnlys | Указывает число PDU, полученных с индикацией ошибки в поле readonly. | 11 |
| snmpNnGenErrs | Указывает число PDU, полученных с generr-полем. | 12 |
| snmpInTotalReqVar | Указывает число объектов MIB, которые были восстановлены. | 13 |
| snmpInTotalSetVars | Указывает число объектов MIB, которые были изменены. | 14 |
| snmpInGetRequests | Указывает число соответствующих pdu, которые были получены. | 15 |
| snmpInGetNexts | Указывает полное число pdu с запросами GetNext | 16 |
| snmpInSetRequests | Указывает полное число pdu, полученных с запросами SET | 17 |
| snmpInGetResponses | Указывает полное число pdu, полученных c откликами на запросы | 18 |
| snmpInTraps | Указывает полное число, полученных и успешно обработанныз TRAP | 19 |
| snmpOutTooBig | Указывает число посланных PDU с полем toobig. | 20 |
| snmpOutNoSuchNames | Указывает число посланных PDU с полем nosuchname. | 21 |
| snmpOutBadValues | Указывает число посланных PDU с полем badvalue. | 22 |
| snmpOutGenErrs | Указывает число посланных PDU с полем genErrs. | 24 |
| snmpOutGetRequests | Указывает число посланных PDU Get-Request | 25 |
| snmpOutGetNexts | Указывает число посланных PDU Get-NEXT | 26 |
| snmpOutSetRequests | Указывает число посланных PDU SET | 27 |
| snmpOutGetResponses | Указывает число посланных PDU откликов | 28 |
| snmpOutTraps | Указывает число посланных PDU TRAPs | 29 |
| snmpEnableAuthTraps | Говорит о том, разрешены или нет ловушки (TRAPS). | 30 |
Стандарт на структуру управляющей информации (SMI) требует, чтобы все MIB-переменные были описаны и имели имена в соответствии с ASN.1 (abstract syntax notation 1, формализованный синтаксис). ASN.1 является формальным языком, который обладает двумя основными чертами:
используемая в документах нотация легко читаема и понимаема, а в компактном кодовом представлении информация может использоваться коммуникационными протоколами. В SMI не используется полный набор типов объектов, предусмотренный в ASN.1, разрешены только следующие типы примитивов: integer, octet string, object identifier и null. Практически в протоколе SNMP фигурируют следующие виды данных:
integer. Некоторые переменные объявляются целыми (integer) с указанием начального значения или с заданным допустимым диапазоном значений (в качестве примера можно привести номера UDP- или TCP-портов).
octet string (последовательность байтов). В соответствии с требованиями BER (basic encoding rules, ASN.1) последовательность октетов должна начинаться с числа байт в этой последовательности (от 0 до n).
object identifier (идентификатор объекта). Имя объекта, представляющее собой последовательность целых чисел, разделенных точками. Например, 192.148.167.129 или 1.3.6.1.2.1.5.
null. Указывает, что соответствующая переменная не имеет значения.
displaystring. Строка из 0 или более байт (но не более 255), которые представляют собой ASCII-символы. Представляет собой частный случай octet string.
physaddress. Последовательность октетов, характеризующая физический адрес объекта (6 байт для Ethernet). Частный случай object identifier.
Сетевой адрес. Допускается выбор семейства сетевых протоколов. В рамках ASN.1 этот тип описан как choice, он позволяет выбрать протокол из семейства протоколов. В настоящее время идентифицировано только семейство протоколов Интернет.
IP-адрес. Этот адрес используется для определения 32-разрядного Интернет-адреса. В нотации ASN.1 - это octet string.
time ticks (такты часов). Положительное целое число, которое используется для записи, например, времени последнего изменения параметров управляемого объекта, или времени последней актуализации базы данных.
Время измеряется в сотых долях секунды.
gauge (масштаб). Положительное целое число в диапазоне 0 - (232-1), которое может увеличиваться или уменьшаться. Если эта переменная достигнет величины 232-1, она будет оставаться неизменной до тех пор пока не будет обнулена командой сброс. Примером такой переменной может служить tcpcurresta, которая характеризует число TCP соединений, находящихся в состоянии established или close_wait.
counter (счетчик). Положительное целое число в диапазоне 0 - (232-1), которое может только увеличиваться, допуская переполнение.
sequence. Этот объект аналогичен структуре в языке Си.
Например, MIB определяет sequence с именем udpentry, содержащую информацию об активных UDP-узлах. В этой структуре содержится две записи:
1. UDPlocaladdress типа ipaddress, содержит местные IP-адреса.
2. UDPlocalport типа integer, содержит номера местных портов.
SEQUENCE OF. Описание вектора, все элементы которого имеют один и тот же тип. Элементы могут представлять собой простые объекты, например, типа целое. В этом случае мы имеем одномерный список. Но элементами вектора могут быть объекты типа SEQUENCE, тогда этот вектор описывает двумерный массив.
В Интернет MIB каждый объект должен иметь имя (object identifier), синтаксис и метод кодировки.
Стандарт ASN.1 определяет форму представления информации и имен. Имена переменных MIB соответствуют в свою очередь стандартам ISO и CCITT. Структура имен носит иерархический характер, отображенный на рис. 4.4.13.1.1.

Рис. 4.4.13.1.1 Структура идентификаторов переменных в MIB
В приведенной ниже таблице охарактеризованы четыре простые переменные, идентификаторы которых помещены в нижней части рис. 4.4.13.1.1. Все эти переменные допускают только чтение.
Имя переменной | Тип данных | Описание | Код |
| udpInDatagrams | counter | Число UDP-дейтограмм, присланных процессам пользователя. | 1 |
| udpNoPorts | counter | Число полученных UDP-дейтограмм, для которых отсутствует прикладной процесс в порте назначения. | 2 |
| udpInErrors | counter | Число не доставленных UDP-дейтограмм по причинам, отличающимся от отсутствия процесса со стороны порта назначения (напр., ошибка контрольной суммы). | 3 |
| udpOutDatagrams | counter | Число посланных UDP-дейтограмм. | 4 |
| udpTable | counter | Таблица, содержащая данные о принимающей стороне | 5 |
Ниже приведено описание таблицы (udptable; index = ,), состоящей из двух простых переменных (read-only).
| Имя переменной | Тип данных | Описание |
| udplocaladdress | ipaddress | Местный IP-адрес для данного приемника; |
| udplocalport | (0 - 65535) | Местный номер порта приемника. |
Согласно этой иерархии переменные, соответствующие ICMP, должны иметь префикс (идентификатор) 1.3.6.1.2.1.5 или в символьном выражении iso.org.dod.internet.mgmt.mib.icmp. Если вы хотите узнать значение какой-то переменной, следует послать запрос, содержащий соответствующий префикс и суффикс, последний определяет имя конкретной переменной. Для простой переменной суффикс имеет вид .0. Ветвь структуры на рис. 4.4.13.1.1, завершающейся узлом Interfaces (2) имеет продолжение в виде ifTable(2) и ifEntry(1). Таким образом переменная ifInUcastPkts будет иметь представление 1.3.6.1.2.1.2.2.1.11.
Помимо стандартного набора переменных и таблиц MIB возможно использование индивидуальных расширений этой базы данных. Это можно продемонстрировать на примере MIB маршрутизаторов Cisco (рис. 4.4.13.1.2).

Рис. 4.4.13.1.2. Расширение базы данных mib маршрутизаторов Cisco
Префикс 1.3.6.1.4.1. является стандартным, далее следует расширение, индивидуальное для маршрутизаторов компании Cisco. Например, группа IPcheckpoint accounting позволяет контролировать поток байтов с определенных адресов локальной сети, что бывает важно при работе с коммерческими провайдерами услуг.
Коды-префиксы для различных производителей телекоммуникационного оборудования приведены в таблице 4.4.13.1.7.
Таблица 4.4.13.1.7 Коды-префиксы производителей
| Код префикса | Название фирмы |
| 0 | Зарезервировано |
| 1 | Proteon |
| 2 | IBM |
| 3 | CMU |
| 4 | UNIX |
| 5 | ACC |
| 6 | TWG |
| 7 | Cayman |
| 8 | PSI |
| 9 | Cisco |
| 10 | NSC |
| 11 | HP |
| 12 | Epilogue |
| 13 | U of Tennessee |
| 14 | BBN |
| 15 | Xylogics, inc. |
| 16 | Unisys |
| 17 | Canstar |
| 18 | Wellfleet |
| 19 | TRW |
| 20 | MIT |
Группа локальных переменных IP checkpoint accounting (1.3.6.1.4.1.9.2.4.7.1) представляет собой таблицу, содержащую в каждом рекорде по четыре переменных (в скобках указан суффикс адреса MIBдля переменной):
ckactbyts [4] - число переданных байт,
ckactdst [2] - адрес места назначения,
ckactpkts [3] - число переданных пакетов
ckactsrc [1] - адрес отправителя
Маршрутизаторы Cisco поддерживают две базы данных: active accounting и checkpoint accounting. В первую заносятся текущие результаты измерения входящего и исходящего трафика. Эти результаты копируются в базу данных checkpoint accounting и, если там уже имеются предыдущие данные, они объединяются. Для очистки базы данных checkpointed database выдается команда clear IP accounting, а для базы checkpoint - clear IP accounting checkpoint (для использования этих команд необходимы системные привилегии). Объем памяти, выделяемой для этих баз данных задается командой IP accounting-threshold <значение>, по умолчанию максимальное число записей в базе данных равно 512.
Лучшим способом закрепить в памяти все вышесказанное является использование программы SNMPI (SNMP initiator) или ее аналога. Если в вашем распоряжении имеется ЭВМ, работающая под unix, например SUN, вы можете попутно узнать много полезного о вашей локальной сети. Ниже описан синтаксис обращения к SNMPI.
snmpi [-a agent] [-c community] [-f file] [-p portno] [-d] [-v] [-w]
SNMPI - крайне простая программа, используемая для тестирования SNMPD. Для того чтобы проверить, работает ли она, выдайте команду:
% SNMPI dump
Следует отметить, что в ответ на эту операцию будет произведена весьма объемная выдача.
Опция -a предлагает возможность ввести адрес SNMP-объекта - имя ЭВМ, IP-адрес или транспортный адрес. По умолчанию это местная ЭВМ. Аналогично опция -p позволяет задать номер UDP-порта. По умолчанию это порт 161.
Опция -c позволяет задать групповой пароль (community) для snmp-запроса. По умолчанию - это public, т.е. свободный доступ.
Опция -f позволяет выбрать файл, содержащий откомпилированные описания mib-модулей. По умолчанию - это objects.defs.
Опция -w включает режим наблюдения, осуществляя выдачу на терминал всех служебных сообщений. Уход из программы по команде quit (q).
Если вы работаете на IBM/PC, и ваша машина подключена к локальной сети, получите допуск к одной из UNIX-машин в сети (если вы его не имели) и приступайте. Можно начать с обращения типа:
SNMPI -a 193.124.224.33 (адрес или символьное имя надо взять из вашей локальной сети)
Машина откликнется, отобразив на экране SNMPI>, это означает, что программа имеется и вы можете вводить любые команды.
Начать можно со знакомства с системными переменными системы (в дальнейшем курсивом выделены команды, введенные с клавиатуры):
SNMPI> get sysdescr.0
snmpi> sysdescr.0="GS software (gs3-k), version 9.1(4) [fc1], software copyright (c) 1986-1993 by cisco systems, inc. compiled thu 25-mar-93 09:49 by daveu"
snmpi> get sysobjectid.0
snmpi> sysobjectid.0=1.3.6.1.4.1.9.1.1
snmpi> get sysuptime.0
snmpi> sysuptime.0=14 days, 7 hours, 0 minutes, 15.27 seconds (123481527 timeticks)
snmpi> get sysservices.0
snmpi> sysservices.0=0x6
Код 0x06 (sysservices.0) представляет собой сумму кодов уровней модели iso, поддерживаемых системой. Для справок: 0x01 - физический уровень; 0x02 - связной уровень; 0x04 - Интернет; 0x08 - связь точка-точка; 0x40 - прикладной уровень.
Если вы хотите получить информацию о состоянии интерфейсов на одной из ЭВМ, подключенных к вашей локальной сети (команды вызова snmpi далее не повторяются; в ниже приведенных примерах в круглых скобках помещены комментарии автора), выдайте команды:
SNMPI> next iftabl (команда next в данном случае соответствует запросу get-next, здесь понятие "следующий" подразумевает порядок переменных в MIB)
snmpi> ifindex.1=1
snmpi> get ifdescr.1
snmpi> ifdescr.1="ethernet0"
snmpi> get iftype.1
snmpi> iftype.1=ethernet-csmacd(6)
snmpi> get ifmtu.1
snmpi> ifmtu.1=1500
snmpi> get ifspeed.1
snmpi> ifspeed.1=10000000 (10Мб/с ethernet)
snmpi> get ifphysaddress.1
snmpi> ifphysaddress.1=0x00:00:0c:02:3a:49 (физический адрес интерфейса)
snmpi> next ifdescr.1 iftype.1 ifmtu.1 ifspeed.1 ifphysaddress.1
snmpi> ifdescr.2="serial0"
iftype.2=proppointtopointserial(22)
ifmtu.2=1500
ifspeed.2=2048000 (2 Мбит/ c радиорелейный последовательный канал, спутниковый канал был бы охарактеризован точно также).
ifphysaddress.2=
В приведенном примере размеры пересылаемых блоков для Ethernet и радиорелейного последовательного канала идентичны и равны 1500. Помните, что SLIP-канал характеризуется как pointtopointserial, а не slip. Скорость обмена по SLIP-каналу не сообщается.
Теперь просмотрим некоторые UDP-переменные. Например:
SNMPI> next UDP
SNMPI> udpindatagrams.0=98931
SNMPI> next udpindatagrams.0 (обратите внимание на суффикс простой переменной)
SNMPI> udpnoports.0=60009
SNMPI> next udplocaladdress.0
SNMPI>udplocaladdress.193.124.137.14.7=193.124.137.14
(Идентификатор этого объекта - 1.3.6.1.2.1.7.5.1.1.193.124.137.14.7.)
SNMPI> next udplocalport
SNMPI> udplocalport.193.124.137.14.7=7
Если у вас возникла необходимость просмотреть таблицу, например, udptable, это
также можно сделать, используя snmpi:
SNMPI> next udptable
SNMPI> udplocaladdress.193.124.137.14.7=193.124.137.14
SNMPI> next udplocaladdress.193.124.137.14.7
SNMPI> udplocaladdress.193.124.224.33.67=193.124.224.33
SNMPI> next udplocaladdress.193.124.224.33.67
SNMPI> udplocaladdress.193.124.224.33.161=193.124.224.33
SNMPI> next udplocalport.193.124.224.33.67
SNMPI> udplocalport.193.124.224.33.161=161
Ниже показана методика выяснения алгоритма и параметров задания величины тайм-аута:
SNMPI> get tcprtoalgorithm.0 tcprtomin.0 tcprtomax.0 tcpmaxconn.0
SNMPI> tcprtoalgorithm.0=vanj(4) (vanj - алгоритм Ван Джакобсона для расчета времени тайм-аута)
tcprtomin.0=300 | (минимальное значение тайм-аута = 300 мс) |
tcprtomax.0=60000 | (максимальное - 60 сек) |
tcpmaxconn.0=-1 | (никаких ограничений на число соединений) |
Чтобы получить информацию о состоянии таблицы адресных преобразований, выдайте команду: SNMPI -a 193.124.224.33 dump at (процедуры с использование субкоманды dump требуют определенного времени для своего исполнения)
| atifindex.1.1.193.124.224.33= | 1 |
| atifindex.1.1.193.124.224.35= | 1 |
| atifindex.3.1.192.148.166.203= | 3 |
| atifindex.3.1.192.148.166.205= | 3 |
| atifindex.5.1.145.249.30.33= | 5 |
| atifindex.5.1.192.148.166.98= | 5 |
| atphysaddress.1.1.193.124.224.33= | 0x00:00:0c:02:3a:49 |
| atphysaddress.1.1.193.124.224.35= | 0x08:00:20:12:1b:b1 |
| atphysaddress.1.1.193.124.224.40= | 0x00:00:cd:f9:0d:e7 |
| atphysaddress.1.1.193.124.224.50= | 0x00:00:0c:02:fb:c5 |
| atnetaddress.1.1.193.124.224.33= | 193.124.224.33 |
| atnetaddress.1.1.193.124.224.35= | 193.124.224.35 |
| atnetaddress.1.1.193.124.224.40= | 193.124.224.40 |
| atnetaddress.1.1.193.124.224.50= | 193.124.224.50 |
| atnetaddress.1.1.193.124.224.60= | 193.124.224.60 |
Текст выдачи с целью экономии места сокращен.
Обычно элементы таблицы расположены в порядке колонка-ряд. Если вы дошли до края колонки или всей таблицы ЭВМ выдаст вам, в зависимости от реализации программы, имя и значение следующего элемента или сообщение об ошибке.
Чтобы получить полный текст адресной таблицы в рамках SNMPI достаточно выдать команду:
SNMPI> dump ipaddrtable
| snmpi> ipadentaddr.192.148.166.222= | 192.148.166.222 |
| ipadentaddr.192.168.1.1= | 192.168.1.1 |
| ipadentaddr.192.168.1.2= | 192.168.1.2 |
| ipadentaddr.193.124.224.33= | 193.124.224.33 |
| ipadentaddr.193.124.224.190= | 193.124.224.190 |
| ipadentifindex.192.148.166.222= | 3 |
| ipadentifindex.192.168.1.1= | 4 |
| ipadentifindex.192.168.1.2= | 6 |
| ipadentifindex.193.124.224.33= | 1 |
| ipadentifindex.193.124.224.190= | 5 |
(Маски субсетей)
| ipadentnetmask.192.148.166.222= | 255.255.255.224 |
| ipadentnetmask.192.168.1.1= | 255.255.255.0 |
| ipadentnetmask.192.168.1.2= | 255.255.255.0 |
| ipadentnetmask.193.124.224.33= | 255.255.255.224 |
| ipadentnetmask.193.124.224.190= | 255.255.255.224 |
ipadentbcastaddr.192.148.166.222= 1 (Все эти субсети используют для широковещательной адресации одни и те же биты).
| ipadentbcastaddr.192.168.1.1= | 1 |
| ipadentbcastaddr.192.168.1.2= | 1 |
| ipadentbcastaddr.193.124.224.33= | 1 |
| ipadentbcastaddr.193.124.224.190= | 1 |
ipadentreasmmaxsize.192.148.166.222= 18024 (С точки зрения фрагментации и последующей сборки дейтограмм данные субсети эквивалентны).
| ipadentreasmmaxsize.192.168.1.1= | 18024 |
| ipadentreasmmaxsize.192.168.1.2= | 18024 |
| ipadentreasmmaxsize.193.124.224.33= | 18024 |
| ipadentreasmmaxsize.193.124.224.190= | 18024 |
Данная пропечатка совместно с приведенной для IFtable позволяет получить достаточно полную картину о данной конкретной локальной сети. Чтобы познакомиться с ARP таблицей, можно воспользоваться командой:
sun> arp -a
itepgw.itep.ru (193.124.224.33) at 0:0:c:2:3a:49
nb.itep.ru (193.124.224.60) at 0:80:ad:2:24:b7
и дополнить полученные данные с помощью SNMPI:
SNMPI> dump ipnettomediatable
SNMPI> ipnettomediaifindex.1.193.124.224.33= 1
ipnettomediaifindex.1.193.124.224.35= 1
ipnettomediaifindex.3.192.148.166.193= 3
ipnettomediaifindex.3.192.148.166.196= 3
ipnettomediaifindex.3.193.124.226.110= 3
ipnettomediaifindex.5.145.249.30.33= 5
ipnettomediaifindex.5.192.148.166.100= 5
ipnettomediaphysaddress.1.193.124.224.33= 0x00:00:0c:02:3a:49
ipnettomediaphysaddress.3.192.148.166.196= 0xaa:00:04:00:0c:04
ipnettomediaphysaddress.3.192.148.166.198= 0xaa:00:04:00:0e:04
ipnettomediaphysaddress.3.192.148.166.203= 0x00:00:01:00:54:62
.........................................
ipnettomediaphysaddress.5.145.249.30.33= 0x00:00:0c:02:69:7d
ipnettomediaphysaddress.5.192.148.166.100= 0x00:20:af:15:c1:61
ipnettomediaphysaddress.5.192.148.166.101= 0x08:00:09:42:0d:e8
ipnettomedianetaddress.1.193.124.224.33= 193.124.224.33
ipnettomedianetaddress.1.193.124.224.35= 193.124.224.35
ipnettomedianetaddress.3.192.148.166.193= 192.148.166.193
ipnettomedianetaddress.3.193.124.226.110= 193.124.226.110
ipnettomedianetaddress.5.145.249.30.33= 145.249.30.33
ipnettomediatype.1.193.124.224.33= other(1)
ipnettomediatype.1.193.124.224.35= dynamic(3)
ipnettomediatype.1.193.124.224.37= dynamic(3)
ipnettomediatype.3.192.148.166.195= dynamic(3)
ipnettomediatype.3.192.148.166.222= other(1)
ipnettomediatype.5.193.124.224.190= other(1)
ipnettomediatype.5.193.124.225.33= other(1)
ipnettomediatype.5.193.124.225.35= dynamic(3)
Синтаксис каждого объекта описывается в рамках ASN.1 и показывает побитовое представление объекта. Кодирование объекта характеризует то, как тип объекта отображается через его синтаксис и передается по телекоммуникационным каналам. Кодирование производится в соответствии с базовыми правилами кодирования asn.1. Все описания объектов базируются на типовых шаблонах и кодах asn.1 (см. RFC-1213). Формат шаблона показан ниже:
object (Объект):
Имя типа объекта с соответствующим ему идентификатором объекта (object identifier)
syntax (Синтаксис):
asn.1 описание синтаксиса типа объекта.
definition (Определение):
Текстовое описание типа объекта.
access (доступ):
Опции доступа.
status (состояние):
Статус типа объекта.
Маршруты также являются объектами mib. Согласно требованиям к mib, каждому маршруту в этой базе соответствует запись, схема которой приведена ниже на рис. 4.4.13.1.3:

Рис. 4.4.13.1.3 Формат записи маршрутной таблицы в MIB
Поле место назначения представляет собой IP-адрес конечной точки маршрута. Поле индекс интерфейса определяет локальный интерфейс (физический порт), через который можно осуществить следующий шаг по маршруту. Следующие пять полей (метрика 1-5) характеризуют оценку маршрута. В простейшем случае, например для протокола RIP, достаточно было бы одного поля. Но для протокола OSPF необходимо 5 полей (разные TOS). Поле следующий шаг представляет собой IP-адрес следующего маршрутизатора. Поле тип маршрута имеет значение 4 для опосредованного достижения места назначения; 3 - для прямого достижения цели маршрута; 2 - для нереализуемого маршрута и 1 - для случаев отличных от вышеперечисленных.
Поле протокол маршрутизации содержит код протокола. Для RIP этот код равен 8, для OSPF - 13, для BGP - 14, для IGMP - 4, для прочих протоколов - 1. Поле возраст маршрута описывает время в секундах, прошедшее с момента последней коррекции маршрута. Следующее поле - маска маршрута используется для выполнения логической побитовой операции И над адресом в IP-дейтограммы перед сравнением результата с кодом, хранящимся в первом поле записи (место назначения). Последнее поле маршрутная информация содержит код, зависящий от протокола маршрутизации и обеспечивающий ссылки на соответствующую информацию в базе MIB.
Новым расширением MIB является система удаленного мониторинга сетей (RMON; RFC-1513, -1271). RMON служит для мониторирования сети в целом, а не отдельных сетевых устройств. В RMON предусмотрено 9 объектных групп (см. табл. 4.4.13.1.8).
Таблица 4.4.13.1.8. Функциональные группы RMON
| Группа | Назначение |
| statistics | Таблица, которая отслеживает около 20 статистических параметров сетевого трафика, включая общее число кадров и количество ошибок |
| history | Позволяет задать частоту и интервалы для измерений трафика |
| alarm | Позволяет установить порог и критерии, при которых агенты выдают сигнал тревоги |
| host | Таблица, содержащая все узлы сети, данные по которым приводятся в сетевой статистике |
| hostTopN | Позволяет создать упорядоченные списки, которые базируются на пиковых значениях трафика группы ЭВМ |
| matrix | Две таблицы статистики трафика между парами узлов. Одна таблица базируется на адресах узлов-отправителей, другая - на адресах узлов-получателей |
| filter | Позволяет определить конкретные характеристики кадров в канале. Например, можно выделить TCP-трафик. |
| packet capture | Работает совместно с группой filter. Позволяет специфицировать объем ресурса памяти, выделяемой для запоминания кадров, которые отвечают критериям filter. |
| event | Позволяет специфицировать набор параметров или условий, которые должен контролировать агент. Когда условия выполняются, информация о событии записывается в специальный журнал |
Для того чтобы реализовать функционирование RMON-агента, сетевая карта должна быть способна работать в режиме 6 (promiscuous mode), когда воспринимаются все пакеты, следующие по кабельному сетевому сегменту.
Установление исходящего вызова
Для установления сессии используется обмен тремя сообщениями. Типичным является ниже приведенный обмен:
LAC LNS
| <- OCRQ |
OCRP ->
(Выполнить операцию вызова)
OCCN ->
| <- ZLB ACK |
Если в очереди нет больше сообщений для партнера, посылается ZLB ACK.
Установление контрольного соединения
Управляющее соединение является первичным, которое должно быть реализовано между LAC и LNS, прежде чем запускать сессию. Установление управляющего соединения включает в себя безопасную идентификацию партнера, а также определение версии L2TP, возможностей канала, кадрового обмена и т.д.. Для установления управляющего соединения осуществляется обмен тремя сообщениями. Типичным является ниже приведенный обмен:
LAC или LNS LAC или LNS
SCCRQ ->
| <- SCCRP |
SCCCN ->
| <- ZLB ACK |
Если в очереди нет больше сообщений для партнера, посылается ZLB ACK.
| Состояние | Событие | Действие | Новое состояние |
| Idle | Local Open request | Послать SCCRQ | wait-ctl-reply |
| Idle |
Получить SCCRQ, приемлемо | Послать SCCRP | wait-ctl-conn |
| idle |
Получить SCCRQ, не приемлемо |
Послать StopCCN, Clean up | idle |
| idle | Получить SCCRP |
Послать StopCCN Clean up | idle |
| Idle | Получить SCCCN | Clean up | idle |
| wait-ctl-reply |
Получить SCCRP, приемлемо |
Послать SCCCN, Послать tunnel-open ожидающей сессии | established |
| wait-ctl-reply |
Получить SCCRP, не приемлемо |
Послать StopCCN, Clean up | idle |
| wait-ctl-reply |
Получить SCCRQ, проигрыш tie-breaker |
Clean up, Re-queue SCCRQ для состояния idle | idle |
| wait-ctl-reply | Получить SCCCN |
Послать StopCCN Clean up | idle |
| wait-ctl-conn |
Получить SCCCN, приемлемо |
Послать tunnel-open ожидающей сессии | established |
| wait-ctl-conn |
Получить SCCCN, не приемлемо |
Послать StopCCN, Clean up | idle |
| wait-ctl-conn |
Получить SCCRP, SCCRQ |
Послать StopCCN, Clean up | idle |
| Established |
Local Open request (новый вызов) |
Послать tunnel-open ожидающей сессии | established |
| Еstablished |
Административное закрытие туннеля |
Послать StopCCN Clean up | idle |
| Established |
Получить SCCRQ, SCCRP, SCCCN |
Send StopCCN Clean up | idle |
|
Idle wait-ctl-reply, wait-ctl-conn, established | Получить StopCCN | Clean up | idle |
Состояниями, ассоциированными с LNS или LAC для установления управляющего соединения, являются:
Idle (пассивно)
Инициатор и получатель начинают функционирование из этого состояния. Инициатор посылает SCCRQ, в то время как получатель остается в пассивном состоянии вплоть до получения SCCRQ.
wait-ctl-reply (ожидание управляющего отклика)
Инициатор проверяет, не поступил ли запрос на установление еще одного соединения от того же самого партнера, и если это так, реагирует на столкновение, как это описано в разделе 5.8.
Когда получено SCCRP, оно проверяется на совместимость версии. Если версия отклика ниже версии посланного запроса, должна использоваться более старая (низшая) версия. Если версия отклика более ранняя, и она поддерживается, инициатор переходит в состояние “установлено”. Если версия более ранняя и не поддерживается, партнеру должно быть послано StopCCN, а инициатор переходит в исходное состояние и разрывает туннель.
wait-ctl-conn (ожидание управляющего соединения)
Состояние, когда ожидается SCCCN; после получения, проверяется отклик приглашения. Туннель оказывается установленным, или разорванным, если не прошла аутентификация.
Established (установлено)
Установленное соединение может быть аннулировано по местным причинам или в результате получения Stop-Control-Connection-Notification. В случае местного разрыва инициатор должен послать Stop-Control-Connection-Notification и ликвидировать туннель.
Если инициатор получает Stop-Control-Connection-Notification, он должен разорвать туннель.
Установление сессии
После успешного установления управляющего соединения, могут формироваться индивидуальные сессии. Каждая сессия соответствует одному PPP информационному потоку между LAC и LNS. В отличие от установления управляющего соединения, установление сессии является асимметричным в отношении LAC и LNS. LAC запрашивает LNS доступ к сессии для входных запросов, а LNS запрашивает LAC запустить сессию для работы с исходящими запросами.
Установление входящего вызова
Для установления сессии используется обмен тремя сообщениями. Типичным является ниже приведенный обмен:
LAC LNS
(Обнаружен вызов)
ICRQ ->
| <- ICRP |
ICCN ->
| <- ZLB ACK |
Если в очереди нет больше сообщений для партнера, посылается ZLB ACK.
Входящие вызовы
Сообщение Incoming-Call-Request генерируется LAC, когда зарегистрирован входящий вызов (например, звонки в телефонной линии). LAC выбирает ID-сессии и порядковый номер и индицирует тип носителя вызова. Модемы должны всегда индицировать аналоговый тип вызова. Вызовы ISDN должны индицировать цифровой тип вызова, когда доступно цифровое обслуживание и используется настройка скорости обмена, и аналоговый, если применен цифровой модем. Вызывающий номер, вызываемый номер и субадрес могут быть включены в сообщение, если они доступны через телефонную сеть.
Раз LAC посылает Incoming-Call-Request, он ждет отклика от LNS, но необязательно отвечает на вызов из телефонной сети. LNS может решить не воспринять вызов если:
Нет ресурсов для поддержки новых сессий;
Поля вызывающего, вызываемого и субадреса не соответствуют авторизованному пользователю;
Сервис носителя не авторизован или не поддерживается.
Если LNS решает принять вызов, он откликается посылкой Incoming-Call-Reply. Когда LAC получает Incoming-Call-Reply, он пытается подключить вызов. Последнее сообщение о подключении от LAC к LNS указывает, что статус вызова для LAC и LNS должнен перейти в состояние “установлено”. Если вызов завершается до того, как LNS успел принять его, LAC посылает Disconnect-Notify, чтобы индицировать эту ситуацию.
Когда телефонный клиент вешает трубку, LAC посылает сообщение Call-Disconnect-Notify. Если LNS хочет аннулировать вызов, он посылает сообщение Call-Disconnect-Notify и ликвидирует свою сессию.
Внешний протокол BGP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Протокол BGP (RFC-1267, BGP-3; RFC-1268; RFC-1467, BGP-4; -1265-66, 1655) разработан компаниями IBM и CISCO. Главная цель BGP - сократить транзитный трафик. Местный трафик либо начинается, либо завершается в автономной системе (AS); в противном случае - это транзитный трафик. Системы без транзитного трафика не нуждаются в BGP (им достаточно EGP для общения с транзитными узлами). Но не всякая ЭВМ, использующая протокол BGP, является маршрутизатором, даже если она обменивается маршрутной информацией с пограничным маршрутизатором соседней автономной системы. AS передает информацию только о маршрутах, которыми она сама пользуется. BGP-маршрутизаторы обмениваются сообщениями об изменении маршрутов (UPDATE-сообщения, рис. 4.4.11.4.1). Максимальная длина таких сообщений составляет 4096 октетов, а минимальная 19 октетов. Каждое сообщение имеет заголовок фиксированного размера. Объем информационных полей зависит от типа сообщения.

Рис. 4.4.11.4.1. Формат BGP-сообщений об изменениях маршрутов
Поле маркер содержит 16 октетов и его содержимое может легко интерпретироваться получателем. Если тип сообщения "OPEN", или если код идентификации в сообщении open равен нулю, то поле маркер должно быть заполнено единицами. Маркер может использоваться для обнаружения потери синхронизации в работе BGP-партнеров. Поле длина имеет два октета и определяет общую длину сообщения в октетах, включая заголовок. Значение этого поля должно лежать в пределах 19-4096. Поле тип представляет собой код разновидности сообщения и может принимать следующие значения:
| 1 | OPEN | (открыть) |
| 2 | UPDATE | (изменить) |
| 3 | NOTIFICATION | (внимание) |
| 4 | KEEPALIVE | (еще жив) |
После того как связь на транспортном протокольном уровне установлена, первое сообщение, которое должно быть послано - это OPEN. При успешном прохождении этого сообщения партнер должен откликнуться сообщением KEEPALIVE ("Еще жив"). После этого возможны любые сообщения. Кроме заголовка сообщение open содержит следующие поля (рис. 4.4.11.4.2):

Рис. 4.4.11.4.2 Формат сообщения open
Поле версия описывает код версии используемого протокола, на сегодня для BGP он равен 4. Двух-октетное поле моя автономная система определяет код AS отправителя. Поле время сохранения характеризует время в секундах, которое отправитель предлагает занести в таймер сохранения. После получения сообщения OPEN BGP-маршрутизатор должен выбрать значение времени сохранения. Обычно выбирается меньшее из полученного в сообщении open и значения, определенного при конфигурации системы (0-3сек). Время сохранения определяет максимальное время в секундах между сообщениями KEEPALIVE и UPDATE или между двумя UPDATE-сообщениями. Каждому узлу в рамках BGP приписывается 4-октетный идентификатор (BGP-identifier, задается при инсталляции и идентичен для всех интерфейсов локальной сети). Если два узла установили два канала связи друг с другом, то согласно правилам должен будет сохранен канал, начинающийся в узле, BGP-идентификатор которого больше. Предусмотрен механизм разрешения проблемы при равных идентификаторах.
Одно-октетный код идентификации позволяет организовать систему доступа, если он равен нулю, маркер всех сообщений заполняется единицами, а поле идентификационных данных должно иметь нулевую длину. При неравном нулю коде идентификации должна быть определена процедура доступа и алгоритм вычисления кодов поля маркера. Длина поля идентификационных данных определяется по формуле:
Длина сообщения = 29 + длина поля идентификационных данных.
Минимальная длина сообщения open составляет 29 октетов, включая заголовок.
Сообщения типа UPDATE (изменения) используются для передачи маршрутной информации между BGP-партнерами. Этот тип сообщения позволяет сообщить об одном новом маршруте или объявить о закрытии группы маршрутов, причем объявление об открытии нового и закрытии старых маршрутов возможно в пределах одного сообщения. Сообщение UPDATE всегда содержит стандартный заголовок и может содержать другие поля в соответствии со схемой:

Рис. 4.4.11.4.3 Формат update-сообщения
Если длина списка отмененных маршрутов равна нулю, ни один маршрут не отменен, а поле отмененные маршруты в сообщении отсутствует. Поле отмененные маршруты имеет переменную длину и содержит список IP-адресных префиксов маршрутов, которые стали недоступны. Каждая такая запись имеет формат:

Длина префикса (в битах), равная нулю означает, что префикс соответствует всем IP-адресам, а сам имеет нулевой размер. Поле префикс содержит IP-адресные префиксы, за которыми следуют разряды, дополняющие их до полного числа октетов. Значения этих двоичных разрядов смысла не имеют.
Нулевое значение полной длины списка атрибутов пути говорит о том, что информация о доступности сетевого уровня в UPDATE-сообщении отсутствует. Список атрибутов пути присутствует в любом UPDATE-сообщении. Этот список имеет переменную длину, а каждый атрибут содержит три составные части: тип атрибута, длину атрибута и значение атрибута. Тип атрибута представляет собой двух-октетное поле со структурой:

Старший бит (бит0) поля флаги атрибута определяет, является ли атрибут опционным (бит0=1) или стандартным (well-known, бит0=0). Бит 1 этого поля определяет, является ли атрибут переходным (бит1=1) или непереходным (бит1=0). Для обычных атрибутов этот бит должен быть равен 1. Третий бит (бит 2) поля Флагов атрибута определяет, является ли информация в опционном переходном атрибуте полной (бит2=0) или частичной (бит2=1). Для обычных и для опционных непереходных атрибутов этот бит должен быть равен нулю. Бит 3 поля флагов атрибута информирует о том, имеет ли длина атрибута один (бит3=0) октет или два октета (бит3=1). Бит3 может быть равен 1 только в случае, когда длина атрибута более 255 октетов. Младшие 4 бита октета флагов атрибута не используются (и должны обнуляться). Если бит3=0, то третий октет атрибута пути содержит длину поля данных атрибута в октетах. Если же бит3=1, то третий и четвертый октеты атрибута пути хранят длину поля данных атрибута. Остальные октеты поля атрибут пути характеризуют значение атрибута и интерпретируются согласно флагам атрибута.
Атрибуты пути бывают "стандартные обязательные" (well-known mandatory), "стандартные на усмотрение оператора", "опционные переходные" и "опционные непереходные". Стандартные атрибуты должны распознаваться любыми BGP-приложениями. Опционные атрибуты могут не распознаваться некоторыми приложениями. Обработка нераспознанных атрибутов задается битом 1 поля флагов. Пути с нераспознанными переходными опционными атрибутами должны восприниматься, как рабочие. Один и тот же атрибут может появляться в списке атрибутов пути только один раз.
Предусмотрены следующие разновидности кодов типа атрибута:
ORIGIN (код типа = 1) - стандартный обязательный атрибут, который определяет происхождение путевой информации. Генерируется автономной системой, которая является источником маршрутной информации. Значение атрибута в этом случае может принимать следующие значения:
| Код атрибута | Описание |
| 0 | IGP - информация достижимости сетевого уровня является внутренней по отношению к исходной автономной системе; |
| 1 | EGP - информация достижимости сетевого уровня получена с помощью внешнего протокола маршрутизации; |
| 2 | Incomplete - информация достижимости сетевого уровня получена каким-то иным способом. |
AS_PATH (код типа = 2) также является стандартным обязательным атрибутом, который составлен из совокупности сегментов пути. Атрибут определяет автономные системы, через которые доставлена маршрутная информация. Когда BGP-маршрутизатор передает описание маршрута, которое он получил от своего BGP-партнера, он модифицирует AS_PATH-атрибут, соответствующий этому маршруту, если информация передается за пределы автономной системы. Каждый сегмент AS_PATH состоит из трех частей <тип сегмента пути, длина сегмента пути и оценка сегмента пути>. Тип сегмента пути представляет в свою очередь однооктетное поле, которое может принимать следующие значения:
| Код типа сегмента | Описание |
| 1 | AS_set: неупорядоченный набор маршрутов в update сообщении; |
| 2 | AS_sequence: упорядоченный набор маршрутов автономной системы в UPDATE-сообщении. |
Длина сегмента пути представляет собой одно-октетное поле, содержащее число as, записанных в поле оценка сегмента пути. Последнее поле хранит один или более кодов автономной системы, по два октета каждый.
NEXT_HOP (код типа = 3) - стандартный обязательный атрибут, определяющий IP-адрес пограничного маршрутизатора, который должен рассматриваться как цель следующего шага на пути к точке назначения.
MULTI_EXIT_DISC (код типа = 4) представляет собой опционный непереходной атрибут, который занимает 4 октета и является положительным целым числом. Величина этого атрибута может использоваться при выборе одного из нескольких путей к соседней автономной системе.
LOCAL_PREF (код типа = 5) является опционным атрибутом, занимающим 4 октета. Он используется BGP-маршрутизатором, чтобы сообщить своим BGP-партнерам в своей собственной автономной системе степень предпочтения объявленного маршрута.
ATOMIC_AGGREGATE (код типа = 6) представляет собой стандартный атрибут, который используется для информирования партнеров о выборе маршрута, обеспечивающего доступ к более широкому списку адресов.
aggregator (код типа = 7) - опционный переходной атрибут с длиной в 6 октетов. Атрибут содержит последний код автономной системы, который определяет агрегатный маршрут (занимает два октета), и IP-адрес BGP-маршрутизатора, который сформировал этот маршрут (4 октета). Объем информации о достижимости сетевого уровня равен (в октетах):
Длина сообщения UPDATE - 23 - полная длина атрибутов пути - длина списка отмененных маршрутов. Информация о достижимости кодируется в следующей форме:

Поле длина определяет длину IP-адресного префикса в битах. Если длина равна нулю, префикс соответствует всем IP-адресам. Префикс содержит IP-адресные префиксы и двоичные разряды, дополняющие код до целого числа октетов.
Информация о работоспособности соседних маршрутизаторов получается из KEEPALIVE-сообщений, которые должны посылаться настолько часто, чтобы уложиться во время, отведенное таймером сохранения (hold).
Обычно это время не должно превышать одной трети от времени сохранения, но не должно быть и меньше 1 секунды. Если выбранное значение времени сохранения равно нулю, периодическая посылка KEEPALIVE-сообщений не обязательна.
NOTIFICATION-сообщения посылаются, когда обнаружена ошибка. BGP-связь при этом немедленно прерывается. Помимо заголовка NOTIFICATION-сообщение имеет следующие поля:

Код ошибки представляет собой одно-октетное поле и указывает на тип данного сообщения. Возможны следующие коды ошибки:
Таблица 4.4.11.4.1. Коды ошибок
| Код ошибки | Описание |
| 1 | Ошибка в заголовке сообщения. |
| 2 | Ошибка в сообщении open |
| 3 | Ошибка в сообщении update |
| 4 | Истекло время сохранения |
| 5 | Ошибка машины конечных состояний |
| 6 | Прерывание |
При отсутствии фатальной ошибки BGP-партнер может в любой момент прервать связь, послав NOTIFICATION-сообщение с кодом ошибки прерывание.
Одно-октетное поле cубкод ошибки предоставляет дополнительную информацию об ошибке. Каждый код ошибки может иметь один или более субкодов. Если поле содержит нуль, это означает, что никаких субкодов не определено.
Таблица 4.4.11.4.2 Субкоды ошибок
| Ошибка | Субкод | Описание |
| Заголовок | 1 2 3 | Соединение не синхронизовано Неверная длина сообщения Неверный тип сообщения |
| Сообщения OPEN | 1 2 3 4 5 6 | Неверный код версии Ошибочный код as-партнера Ошибочный идентификатор BGP Ошибка в коде идентификации Ошибка при идентификации Неприемлемое время сохранения |
| Сообщения UPDATE | 1 2 3 4 5 6 7 8 9 10 11 | Ошибка в списке атрибутов Не узнан стандартный атрибут Отсутствует стандартный атрибут Ошибка в флагах атрибута Ошибка в длине атрибута Неправильный атрибут origin Циклический маршрут Ошибка в атрибуте next_hop Ошибка в опционном атрибуте Ошибка в сетевом поле Ошибка в as_path |
Вся маршрутная информация хранится в специальной базе данных RIB (routing information base). Маршрутная база данных BGP состоит из трех частей:
| 1. | ADJ-RIBS-IN: | Запоминает маршрутную информацию, которая получена из update-сообщений. Это список маршрутов, из которого можно выбирать. (policy information base - PIB). |
| 2. | LOC-RIB: | Содержит локальную маршрутную информацию, которую BGP-маршрутизатор отобрал, руководствуясь маршрутной политикой, из ADJ-RIBS-IN. |
| 3. | ADJ-RIBS-OUT: | Содержит информацию, которую локальный BGP-маршрутизатор отобрал для рассылки соседям с помощью UPDATE-сообщений. |
Так как разные BGP- партнеры могут иметь разную политику маршрутизации, возможны осцилляции маршрутов. Для исключения этого необходимо выполнять следующее правило: если используемый маршрут объявлен не рабочим (в процессе корректировки получено сообщение с соответствующим атрибутом), до переключения на новый маршрут необходимо ретранслировать сообщение о недоступности старого всем соседним узлам.
Протокол BGP позволяет реализовать маршрутную политику, определяемую администратором AS (см. раздел ""). Политика отражается в конфигурационных файлах BGP. Маршрутная политика это не часть протокола, она определяет решения, когда место назначения достижимо несколькими путями, политика отражает соображения безопасности, экономические интересы и пр. Количество сетей в пределах одной AS не лимитировано. Один маршрутизатор на много сетей позволяет минимизировать таблицу маршрутов.
BGP использует три таймера:
Connectretry (сбрасывается при инициализации и коррекции; 120 сек),
Holdtime (запускается при получении команд Update или Keepalive; 90сек) и
keepalive (запускается при посылке сообщения Keepalive; 30сек).
BGP отличается от RIP и OSPF тем, что использует TCP в качестве транспортного протокола. Две системы, использующие BGP, связываются друг с другом и пересылают посредством TCP полные таблицы маршрутизации. В дальнейшем обмен идет только в случае каких-то изменений. ЭВМ, использующая BGP, не обязательно является маршрутизатором. Сообщения обрабатываются только после того, как они полностью получены.
BGP является протоколом, ориентирующимся на вектор расстояния. Вектор описывается списком AS по 16 бит на AS. BGP регулярно (каждые 30сек) посылает соседям TCP-сообщения, подтверждающие, что узел жив (это не тоже самое что "Keepalive" функция в TCP). Если два BGP-маршрутизатора попытаются установить связь друг с другом одновременно, такие две связи могут быть установлены. Такая ситуация называется столкновением, одна из связей должна быть ликвидирована.
При установлении связи маршрутизаторов сначала делается попытка реализовать высший из протоколов (например, BGP-4), если один из них не поддерживает эту версию, номер версии понижается.
Протокол BGP-4 является усовершенствованной версией (по сравнению с BGP-3). Эта версия позволяет пересылать информацию о маршруте в рамках одного IP-пакета. Концепция классов сетей и субсети находятся вне рамок этой версии. Для того чтобы приспособиться к этому, изменена семантика и кодирование атрибута AS_PASS. Введен новый атрибут LOCAL_PREF (степень предпочтительности маршрута для собственной AS), который упрощает процедуру выбора маршрута. Атрибут INTER_AS_METRICSпереименован в MULTI_EXIT_DISC (4 октета; служит для выбора пути к одному из соседей). Введены новые атрибуты ATOMIC_AGGREGATE и AGGREGATOR, которые позволяют группировать маршруты. Структура данных отражается и на схеме принятия решения, которая имеет три фазы:
Вычисление степени предпочтения для каждого маршрута, полученного от соседней AS, и передача информации другим узлам местной AS.
Выбор лучшего маршрута из наличного числа для каждой точки назначения и укладка результата в LOC-RIB.
Рассылка информации из loc_rib всем соседним AS согласно политике, заложенной в RIB. Группировка маршрутов и редактирование маршрутной информации.
Бесклассовая интердоменная маршрутизация (CIDR- classless interdomain routing, RFC-1520, -1519) - способ избежать того, чтобы каждая С-сеть требовала свою таблицу маршрутизации. Основополагающий принцип CIDR заключается в группировке (агрегатировании) IP-адресов таким образом, чтобы сократить число входов в таблицах маршрутизации (RFC-1519, RFC-1518, RFC-1467, RFC-1466). Протокол совместим с RIP-2, OSPF и BGP-4. Основу протокола составляет идея бесклассовых адресов, где нет деления между полем сети и полем ЭВМ. Дополнительная информация, например 32-разрядная маска, выделяющая поле адреса сети, передается в рамках протокола маршрутизации. При этом выдерживается строгая иерархия адресов: провайдер > предприятие > отдел/здание > сегмент локальной сети.
Групповой (агрегатный) адрес воспринимается маршрутизатором как один адрес. Группу может образовывать только непрерывная последовательность IP-адресов. Такой бесклассовый интернетовский адрес часто называется IP-префиксом. Так адрес 192.1.1.0/24 означает диапазон адресов 192.1.1.0 - 192.1.1.255, а адрес 192.1.128.0/17 описывает диапазон 192.1.128.0 - 192.1.255.255, таким образом, число, следующее после косой черты, задает количество двоичных разрядов префикса. Это представление используется при описании политики маршрутизации и самих маршрутов (см. разд.4.4.11.4 - ). Для приведенных примеров это в терминах масок выглядит следующим образом:

24 и 17 длины префикса сети.
Следует помнить, что маски с разрывами здесь недопустимы. Ниже приведена таблица метрик маршрутизации для различных протоколов.
| Протокол | Метрика | Диапазон | Код "маршрут недостижим" |
RIP hello BGP | Число скачков Задержка в ms Не определена | 0-15 0-29999 0-65534 | 16 30000 65535 |
Колонка "маршрут недостижим" содержит коды метрики, которые говорят о недоступности маршрута. Обычно предполагается, что если послан пакет из точки <А> в точку <B>, то маршруты их в одном и другом направлении совпадают. Но это не всегда так. Пример, когда маршруты пакетов "туда" и "обратно" не совпадают, представлен на рис. 4.4.11.4.4. В предложенной схеме имеется две ЭВМ "Место назначения" и "ЭВМ-отправитель", а также два маршрутизатора "GW-2" и "GW-1".

Рис. 4.4.11.4.4. Пример разных маршрутов для пути "туда" и "обратно".
Предполагается, что оператор находится в ЭВМ-отправителе. Команда traceroute 192.148.166.33 в этом случае выдаст:
| 1 GW-1 | (192.148.166.35) |
| 2 Место назначения | (192.148.166.33) |
Команда же traceroute 192.148.165.80 распечатает:
| 1 GW-1 | (192.148.166.35) |
| 2 GW-2 | (192.148.166.7) |
| 3 Место назначения | (192.148.165.80) |
Команда traceroute -g 192.148.165.80 сообщит вам:
| 1 GW-1 | (192.148.166.35) |
| 2 ***** | ; В этом режиме маршрутизатор не откликается |
3 Место назначения | (192.148.165.80) |
| 4 GW-1 | (192.148.166.35) |
| 5 ЭВМ-отправитель | (192.148.166.32) |
/p> Из приведенных примеров видна также полезность команды traceroute для понимания того, как движутся пакеты в сети. В некоторых случаях это может помочь оптимизировать маршрутизацию и улучшить пропускную способность сети.
Другой полезной командой является Netstat, которая позволяет получить разнообразную информацию о состоянии сети. Существует четыре модификации этой команды:
-a отображает состояния всех соединений;
-i отображает значения конфигурационных параметров;
-r отображает таблицу маршрутов;
-v отображает статистику обмена локального Ethernet-интерфейса.
Например, команда netstat -r может выдать:
Routing tables (таблицы маршрутизации)
| Destination | Gateway | Flags | Refcnt | Use | Interface | |
| Stavropol-GW.ITEP.RU | nb | UGHD | 0 | 109 | le0 | |
| ihep.su | itepgw | UGHD | 0 | 103 | le0 | |
| m10.ihep.su | itepgw | UGHD | 0 | 16 | le0 | |
| 194.85.66.50 | itepgw | UGHD | 0 | 455 | le0 | |
| Kharkov.ITEP-Kharkov | nb | UGHD | 0 | 105 | le0 | |
| Bryansk-GW.ITEP.Ru | nb | UGHD | 1 | 8113 | le0 | |
| 193.124.225.67 | nb | UGHD | 0 | 0 | le0 | |
| ixwin.ihep.su | itepgw | UGHD | 1 | 6450 | le0 | |
| ihep.su | itepgw | UGHD | 0 | 14 | le0 | |
| 192.148.166.21 | nb | UGHD | 0 | 109 | le0 | |
| ihep.su | itepgw | UGHD | 0 | 224 | le0 | |
| 193.124.225.71 | nb | UGHD | 0 | 10 | le0 | |
| 194.85.112.0 | ITEP-FDDI-BBone.ITEP | UGD | 0 | 253 | le0 | |
| default | itepgw | UG | 10 | 102497 | le0 | |
Здесь приведен только фрагмент маршрутной таблицы. Колонка destination указывает на конечную точку маршрута (default - маршрут по умолчанию), колонка gateway - имена маршрутизаторов, через которые достижим адресат. Флаг "U" (Up) свидетельствует о том, что канал в рабочем состоянии. Флаг "G" указывает на то, что маршрут проходит через маршрутизатор (gateway). При этом вторая колонка таблицы содержит имя этого маршрутизатора. Если флаг "G" отсутствует, ЭВМ непосредственно связана с указанной сетью. Флаг "D" указывает на то, что маршрут был добавлен динамически. Если маршрут связан только с конкретной ЭВМ, а не с сетью, он помечается флагом "H" (host), при этом первая колонка таблицы содержит его IP-адрес. Базовая команда netstat может обеспечить следующую информацию:
Active Internet connections (активные Интернет связи)
| Proto | Recv-Q | Send-Q | Local Address | Foreign Address | (state) |
| tcp | 0 | 0 | 127.0.0.1.1313 | 127.0.0.1.sunrpc | TIME_WAIT |
| tcp | 0 | 0 | ns.1312 | 193.124.18.65.smtp | SYN_SENT |
| tcp | 0 | 0 | 127.0.0.1.1311 | 127.0.0.1.sunrpc | TIME_WAIT |
| tcp | 0 | 0 | ns.1310 | ns.domain | TIME_WAIT |
| tcp | 0 | 0 | 127.0.0.1.1309 | 127.0.0.1.sunrpc | TIME_WAIT |
| tcp | 39 | 24576 | ns.nntp | Bryansk-GW.ITEP.1697 | ESTABLISHED |
| tcp | 0 | 0 | ns.telnet | semenov.1802 | ESTABLISHED |
| tcp | 0 | 188 | ns.1033 | xmart.desy.de.6000 | ESTABLISHED |
| udp | 0 | 0 | 127.0.0.1.domain | *.* | |
| udp | 0 | 0 | ns.domain | *.* | |
Active UNIX domain sockets (активные UNIX-соединители домена)
| Address | Type | Recv-Q | Send-Q | Vnode | Conn | Refs | Nextref Addr |
| ff64b38c | stream | 0 | 0 | ff13187c | 0 | 0 | 0 /dev/printer |
| ff64b28c | dgram | 0 | 0 | 0 | 0 | 0 | 0 |
| ff64698c | dgram | 0 | 0 | ff137fa8 | 0 | 0 | 0 /dev/log |
Внутренний протокол маршрутизации RIP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Этот протокол маршрутизации предназначен для сравнительно небольших и относительно однородных сетей (алгоритм Белмана-Форда). Протокол разработан в университете Калифорнии (Беркли), базируется на разработках фирмы Ксерокс и реализует те же принципы, что и программа маршрутизации routed, используемая в ОC Unix (4BSD). Маршрут здесь характеризуется вектором расстояния до места назначения. Предполагается, что каждый маршрутизатор является отправной точкой нескольких маршрутов до сетей, с которыми он связан. Описания этих маршрутов хранится в специальной таблице, называемой маршрутной. Таблица маршрутизации RIP содержит по записи на каждую обслуживаемую машину (на каждый маршрут). Запись должна включать в себя:
IP-адрес места назначения.
Метрика маршрута (от 1 до 15; число шагов до места назначения).
IP-адрес ближайшего маршрутизатора (gateway) по пути к месту назначения.
Таймеры маршрута.
Первым двум полям записи мы обязаны появлению термина вектор расстояния (место назначение - направление; метрика - модуль вектора). Периодически (раз в 30 сек) каждый маршрутизатор посылает широковещательно копию своей маршрутной таблицы всем соседям-маршрутизаторам, с которыми связан непосредственно. Маршрутизатор-получатель просматривает таблицу. Если в таблице присутствует новый путь или сообщение о более коротком маршруте, или произошли изменения длин пути, эти изменения фиксируются получателем в своей маршрутной таблице. Протокол RIP должен быть способен обрабатывать три типа ошибок:
Циклические маршруты. Так как в протоколе нет механизмов выявления замкнутых маршрутов, необходимо либо слепо верить партнерам, либо принимать меры для блокировки такой возможности.
Для подавления нестабильностей RIP должен использовать малое значение максимально возможного числа шагов (<16).
Медленное распространение маршрутной информации по сети создает проблемы при динамичном изменении маршрутной ситуации (система не поспевает за изменениями). Малое предельное значение метрики улучшает сходимость, но не устраняет проблему.
Несоответствие маршрутной таблицы реальной ситуации типично не только для RIP, но характерно для всех протоколов, базирующихся на векторе расстояния, где информационные сообщения актуализации несут в себе только пары кодов: адрес места назначение и расстояние до него. Пояснение проблемы дано на рис. 4.4.1.11.1 ниже.

Рис. 4.4.11.1. Иллюстрация, поясняющее возникновение циклических маршрутов при использовании вектора расстояния.
На верхней части рисунка показана ситуация, когда маршрутизаторы указывают маршрут до сети в соответствии со стрелками. На нижней части связь на участке GW1 <Сеть a> оборвана, а GW2 по-прежнему продолжает оповещать о ее доступности с числом шагов, равным 2. При этом GW1, восприняв эту информацию (если GW2 успел передать свою маршрутную информацию раньше GW1), может перенаправить пакеты, адресованные сети А, на GW2, а в своей маршрутной таблице будет характеризовать путь до сети А метрикой 3. При этом формируется замкнутая петля маршрутов. Последующая широковещательная передача маршрутных данных GW1 и GW2 не решит эту проблему быстро. Так после очередного обмена путь от gw2 до сети А будет характеризоваться метрикой 5. Этот процесс будет продолжаться до тех пор, пока метрика не станет равной 16, а это займет слишком много циклов обмена маршрутной информацией.
Проблема может быть решена следующим образом. Маршрутизатор запоминает, через какой интерфейс получена маршрутная информация, и через этот интерфейс эту информацию уже не передает. В рассмотренном выше примере GW2 не станет посылать информацию о пути к сети А маршрутизатору GW1, от которого он получил эти данные. В этом случае в маршрутной таблице GW1 путь до А исчезнет сразу. Остальные маршрутизаторы узнают о недостижимости сети А через несколько циклов. Существуют и другие пути преодоления медленных переходных процессов. Если производится оповещение о коротком пути, все узлы-получатели воспринимают эти данные немедленно. Если же маршрутизатор закрывает какой-то путь, его отмена фиксируется остальными лишь по тайм-ауту.
Универсальным методом исключения ошибок при маршрутизации является использование достаточно большой выдержки, перед тем как использовать информацию об изменении маршрутов. В этом случае к моменту изменения маршрута эта информация станет доступной всем участникам процесса маршрутизации. Но все перечисленные методы и некоторые другие известные алгоритмы, решая одну проблему, часто вносят другие. Многие из этих методов могут при определенных условиях вызвать лавину широковещательных сообщений, что также дезорганизует сеть. Именно малая скорость установления маршрутов в RIP (и других протоколах, ориентированных на вектор расстояния) и является причиной их постепенного вытеснения другими протоколами.
Но даже усовершенствование, изложенное выше, не всегда срабатывает. На рис. 4.4.11.1а приведен пример, когда переходной процесс, несмотря на усовершенствование будет идти долго. При обрыве связи В-Г узлы А и Б сообщают узлу В, что они потеряли связь с узлом Г. Узел В делает вывод, что Г не достижим, о чем и сообщает узлам А и Б. К сожалению А знает, что Б имеет проход к Г длиной 2, из чего он делает вывод о достижимости Г за три шага. Аналогично рассуждает Б о возможности достижимости Г через А. Далее при последующих рассылках метрика доступности Г, характеризуется все большими значениями, до тех пор пока не станет равной "бесконечности".

Рис. 4.4.11.1а. Пример топологии, где переходной процесс осуществляется медленно, даже при усовершенствовании алгоритма.
В RIP сообщения инкапсулируются в udp-дейтограммы, при этом передача осуществляется через порт 520. В качестве метрики RIP использует число шагов до цели. Если между отправителем и приемником расположено три маршрутизатора (gateway), считается, что между ними 4 шага. Такой вид метрики не учитывает различий в пропускной способности или загруженности отдельных сегментов сети. Применение вектора расстояния не может гарантировать оптимальность выбора маршрута, ведь, например, два шага по сегментам сети ethernet обеспечат большую пропускную способность, чем один шаг через последовательный канал на основе интерфейса RS-232.
Маршрут по умолчанию имеет адрес 0.0.0.0 (это верно и для других протоколов маршрутизации). Каждому маршруту ставится в соответствие таймер тайм-аута и "сборщика мусора". Тайм-аут-таймер сбрасывается каждый раз, когда маршрут инициализируется или корректируется. Если со времени последней коррекции прошло 3 минуты или получено сообщение о том, что вектор расстояния равен 16, маршрут считается закрытым. Но запись о нем не стирается, пока не истечет время "уборки мусора" (2мин). При появлении эквивалентного маршрута переключения на него не происходит, таким образом, блокируется возможность осцилляции между двумя или более равноценными маршрутами. Формат сообщения протокола RIP имеет вид, показанный на рис. 4.4.11.2. Поле команда определяет выбор согласно следующей таблице:
Таблица 4.4.11.1. Значения кодов поля команда
| Команда | Значение |
| 1 | Запрос на получение частичной или полной маршрутной информации; |
| 2 | Отклик, содержащий информацию о расстояниях из маршрутной таблицы отправителя; |
| 3 | Включение режима трассировки (устарело); |
| 4 | Выключение режима трассировки (устарело); |
| 5-6 | Зарезервированы для внутренних целей sun microsystem. |
Поле версия для RIP равно 1 (для RIP-2 двум). Поле набор протоколов сети i определяет набор протоколов, которые используются в соответствующей сети (для Интернет это поле имеет значение 2). Поле расстояние до сети i содержит целое число шагов (от 1 до 15) до данной сети. В одном сообщении может присутствовать информация о 25 маршрутах. При реализации RIP можно выделить следующие режимы:
Инициализация, определение всех "живых" интерфейсов путем посылки запросов, получение таблиц маршрутизации от других маршрутизаторов. Часто используются широковещательные запросы.
Получен запрос. В зависимости от типа запроса высылается адресату полная таблица маршрутизации, или проводится индивидуальная обработка.
Получен отклик. Проводится коррекция таблицы маршрутизации (удаление, исправление, добавление).
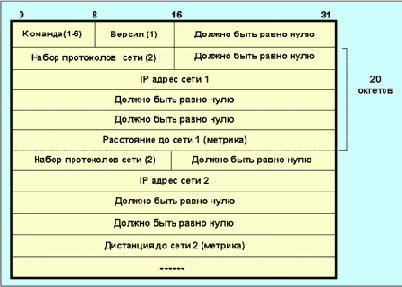
Рис. 4.4.11.2. Формат сообщения RIP.
Регулярные коррекции. Каждые 30 секунд вся или часть таблицы маршрутизации посылается всем соседним маршрутизаторам. Могут посылаться и специальные запросы при локальном изменении таблицы. RIP достаточно простой протокол, но, к сожалению не лишенный недостатков:
RIP не работает с адресами субсетей. Если нормальный 16-бит идентификатор ЭВМ класса B не равен 0, RIP не может определить является ли не нулевая часть cубсетевым ID, или полным IP-адресом.
RIP требует много времени для восстановления связи после сбоя в маршрутизаторе (минуты). В процессе установления режима возможны циклы.
Число шагов важный, но не единственный параметр маршрута, да и 15 шагов не предел для современных сетей.
Протокол RIP-2 (RFC-1388, 1993 год) является новой версией RIP, которая в дополнение к широковещательному режиму поддерживает мультикастинг; позволяет работать с масками субсетей. На рис. 4.4.11.3 представлен формат сообщения для протокола RIP-2. Поле маршрутный демон является идентификатором резидентной программы-маршрутизатора. Поле метка маршрута используется для поддержки внешних протоколов маршрутизации, сюда записываются коды автономных систем. При необходимости управления доступом можно использовать первые 20 байт с кодом набора протоколов сети 0xFFFF и меткой маршрута =2. Тогда в остальные 16 байт можно записать пароль.

Рис. 4.4.11.3 Формат сообщений протокола RIP-2
Проблемы аутентификации в протоколе RIP-2 c использованием дайджестов MD5 обсуждаются в документе RFC-2082
Временные параметры
Существует два временных параметра, соответствующие каждому элементу прохода или состоянию резервирования RSVP в узле: период обновления R между последовательными коррекциями состояния соседнего узла и время жизни локального состояния L. Каждое сообщение RSVP Resv или Path может содержать объект TIME_VALUES, специфицирующий значение R, которое было использовано при генерации данного сообщения обновления. Эта величина R затем используется для определения значения L. Величины R и L могут варьироваться от узла к узлу.
Более подробно: Флойд и Джакобсон [FJ94] показали, что периодические сообщения, генерируемые независимыми сетевыми узлами, могут взаимно синхронизоваться. Это может привести к деградации сетевых услуг, так как периодические сообщения могут сталкиваться с другими сетевыми пакетами. Так как RSVP периодически посылает сообщения обновления, он должен избегать синхронизации сообщений и гарантировать, чтобы любая возникшая синхронизация не была стабильной. По этой причине таймер обновления должен быть рэндомизован в диапазоне [0.5R, 1.5R].Чтобы избежать преждевременной потери состояния, L должно удовлетворять условию L ? (K + 0.5)*1.5*R, где K небольшое целое число. Тогда в худшем случае, K-1 последовательных сообщений могут быть потеряны без ликвидации состояния. Чтобы вычислить время жизни L для комбинации состояний с различными R R0, R1, ..., заменяем R на max(Ri). В настоящее время по умолчанию K = 3. Однако может быть необходимо установить большее значение K для узлов с высокой вероятностью потерь. K может устанавливаться при конфигурации интерфейса вручную или с помощью какой-либо адаптивной процедуры.Каждое сообщение Path или Resv несет в себе объект TIME_VALUES, содержащий время обновления R, использованное при генерации обновлений. Узел получателя использует это R для определения времени жизни L записанного состояния, созданного или обновленного данным сообщением. Время обновления R выбирается локально для каждого из узлов. Если узел не использует локального восстановления резервирования, нарушенного в результате изменения маршрута, меньшее значение R ускоряет адаптацию к изменениям маршрута, но увеличивает издержки RSVP. Узел может настраивать эффективное значение R динамически, чтобы контролировать уровень издержек, связанных с сообщениями обновления. В настоящее время по умолчанию выбирается R = 30 секундам. Однако значение по умолчанию Rdef должно выбираться индивидуально для каждого интерфейса.Когда R меняется динамически, существует предел того, как быстро оно может расти. Отношение величин R2/R1 не должно превосходить 1 + Slew.Max. В настоящее время, Slew.Max равно 0.30. При K = 3, один пакет может быть потерян без таймаута состояния, в то время как R увеличивается на 30% за период обновления.Чтобы улучшить надежность, узел может временно после изменения состояния посылать сообщения обновления более часто.Значения Rdef, K и Slew.Max, используемые в приложении, должны легко модифицироваться для каждого интерфейса.
Временные соображения
В силу того, что телефонная связь по своей природе работает в реальном времени, как LNS, так и LAC должны быть реализованы по многопроцессной схеме, такой чтобы сообщения, относящиеся к нескольким вызовам, не блокировались.
определяет механизм инкапсуляции для транспортировки
Протокол PPP [RFC1661] определяет механизм инкапсуляции для транспортировки мультипротокольных пакетов для соединений точка-точка сетевого уровня L2. Обычно, пользователь получает соединение L2 с сервером доступа NAS (Network Access Server) посредством одной из следующих технологий: посредством модема через коммутируемую телефонную сеть, ISDN, ADSL, и т.д. Далее через это соединение реализуется протокол PPP. В такой конфигурации терминальная точка L2 и сессии PPP находится в одном и том же физическом устройстве (NAS). Разрабатывается версия протокола для безопасного удаленногго доступа через L2TP (RFC-2888).
Протокол L2TP расширяет модель PPP, позволяя размещение терминальных точек L2 и PPP в различных физических устройствах, подключенных к сети с коммутацией пакетов. В L2TP, пользователь имеет соединение L2 с концентратором доступа (например, модемным пулом, ADSL DSLAM, и т.д.), а концентратор в свою очередь туннелирует индивидуальные PPP-кадры в NAS. Это позволяет разделить обработку PPP-пакетов и реализацию шлюза L2.
Очевидным преимуществом такого разделения является то, что вместо требования завершения соединения L2 в NAS, соединение может завершаться в локальном концентраторе, который затем продлевает логический канал PPP через общую инфраструктуру, такую как, например, Интернет. C точки зрения пользователя нет никакой разницы между завершением туннеля на уровне L2 в NAS или через L2TP.
Многоканальный PPP [RFC1990] требует, чтобы все каналы, образующие многоканальную связь, были объединены в группу с помощью одного NAS. Благодаря возможности формирования сессий PPP с оконечными адресами, отличными от точки присоединения, L2TP может использоваться для схем, когда все каналы приходят на вход одного NAS.
Протокол сетевого времени (NTP v3), описанный в документе RFC-1305 [MIL92], широко используется для синхронизации часов ЭВМ в глобальном Интернет. Он обеспечивает доступ к национальным системам точного времени. В большинстве мест Интернет протокол гарантирует точность синхронизации с точностью 1-50 мс, в зависимости от свойств источника синхронизации и сетевых задержек.
RFC-1305 специфицирует машину протокола NTP v3 в терминах событий, состояний, функций перехода и действий. Кроме того, там определены инженерные алгоритмы улучшения точности синхронизации и выбора из списка эталонных источников, некоторые из которых могут быть неисправны. Эти алгоритмы необходимы для компенсации влияния вариаций задержки пакетов в сети Интернет. Однако, во многих обстоятельствах приемлемы точности порядка доли секунды. В таких случаях используется более простые протоколы времени [POS83]. Эти протоколы обычно использует RPC-обмен, где клиент запрашивает время дня, а сервер присылает его значение в секундах после некоторого известного эталонного момента.
NTP создан для использования клиентами и серверами с широким диапазоном возможностей для широкого интервала сетевых задержек и большого временного разброса. Большинство пользователей NTP синхронизации используют программное обеспечение с полным набором опций и алгоритмов (смотри ).
SNTP v 4 предполагает совместимость с NTP и SNTP v 3 как для клиентов так и для серверов. Кроме того, клиенты и серверы SNTP v.4 могут реализовывать расширения для работы в эникаст режиме.
Клиенты SNTP должны работать только на самом верхнем уровне субсети в конфигурациях, где синхронизация NTP или SNTP клиентов не зависит от других клиентов. Серверы SNTP должны работать только на первом (базовом) уровне субсети и в конфигурациях, где нет других источников синхронизации кроме надежных радио или модемных служб точного времени.
Выполнение резервирования
Приложение-получатель использует вызов API для запроса резервирования RSVP. Этот вызов может опционно включать локальный IP-адрес получателя, т.е., адрес интерфейса для получения информационных пакетов. В случае мультикаст-сессий это интерфейс, к которому подключилась группа. Если этот параметр опущен, система использует значение по умолчанию.
Процесс RSVP должен посылать сообщения Resv приложению через специфицированный интерфейс. Однако, когда приложение исполняется в маршрутизаторе, а сессия является мультикастной, возникает более сложная ситуация. Предположим, что в этом случае приложение получателя присоединяется к группе через интерфейс Iapp, который отличается от Isp – ближайшего интерфейса по пути к отправителю. Теперь имеется два возможных пути для мультикастной маршрутизации при доставке информационных пакетов приложению. Процесс RSVP должен определить, какой вариант выбрать, просмотрев состояние прохода и решив, какой из входных интерфейсов следует использовать для посылки сообщений. Протокол мультикастной маршрутизации может создавать отдельные ветви дерева доставки к Iapp. В этом случае будет иметься состояние прохода для обоих интерфейсов Isp и Iapp. Состояние прохода в Iapp должно только соответствовать резервированию локального приложения. Оно должно быть помечено процессом RSVP как "Local_only". Если существует состояние прохода "Local_only" для Iapp, сообщение Resv должно посылаться через Iapp. Заметим, что имеется возможность для блоков состояния прохода Isp и Iapp иметь один и тот же следующий узел, если в маршрут вклинивается область, не поддерживающая RSVP.Протокол мультикастной маршрутизации может переадресовать данные в пределах маршрутизатора от Isp к Iapp. В этом случае Iapp появится в списке выходных интерфейсов состояния прохода Isp и сообщения Resv должны будут посылаться через Isp.Когда сообщения Path и PathTear переадресованы, состояние прохода, помеченное как "Local_Only", должно игнорироваться.
в отношении случайных потерь делает
TCP уязвимость в отношении случайных потерь делает трудным мультиплексирование информационного потока с трафиком реального времени при вариации скорости передачи со временем (мультимедиа), в особенности если оба вида трафика работают с общим буфером, что типично для большинства современных сетей. В сетях ATM, однако, TCP соединения могут поддерживаться с помощью классов трафика UBR или ABR, которые обычно буферизуются отдельно от высоко приоритетного VBR (Variable Bit Rate) или CBR (Constant Bit Rate) трафика. Если последние классы трафика имеют более высокий приоритет, TCP соединения обнаружат для себя емкость канала, варьируемую со временем, оставшуюся после обслуживания потоков VBR и CBR. Эти вариации могут приводить к “случайным потерям”, которые сильно ухудшают рабочие характеристики. Однако если буфер имеет достаточный объем, чтобы сгладить эти вариации и удержать вероятность потери для соединения точка-точка ниже обратного квадрата произведения полосы на задержку, тогда рабочие характеристики TCP не будут серьезно ухудшены. Включение селективного подтверждения в TCP облегчит эту проблему, так как размер окна не нужно резко сокращать для изолированных случайных потерь.
В дополнение к уязвимости от случайных потерь, тот факт, что потери являются основным средством обратной связи, используемым TCP, приводит к непомерным задержкам. Это происходит потому, что в сетях с высоким коэффициентом использования, размер окна для TCP соединения будет увеличиваться и, после того как возможности узкого участка канала окажутся полностью исчерпанными, а буфер переполненным, произойдет потеря. Задержка и рабочие характеристики при потерях могут быть существенно улучшены, если мы вместо этого используем схему, которая лишь пытается поддерживать ширину окна, чтобы достичь высокого использования канала. Такая схема как DECbit [] реализует это, используя явную обратную связь со стороны коммутаторов, подобные схемы имеет смысл рассмотреть, особенно потому, что Explicit Congestion Notification (явное оповещение о перегрузке) встроена в качестве опции для сетей ATM.
Заметим, однако, что схема DECbit в частности подвержена, как и TCP, проблемам при работе с соединениями при больших задержках распространения. Другой возможностью является более изощренная оценка RTT, сходная с тем, что сделано в работе []. Это конечно привлекательно, так как исключает необходимость явной обратной связи. Однако если задержка RTT может меняться существенно без изменения загрузки в канале (например, из-за того, что задержка обработки в узлах зависит от загрузки операционной системы или потому, что задержки связаны с особенностями работы мобильных приложений), тогда адаптация, базирующаяся на обработке задержек может оказаться менее устойчивой, чем адаптация на основе потерь или явной обратной связи. Кроме того, если различные соединения не изолированы друг от друга с точки зрения использования ими полосы и сетевых буферов, тогда соединение, которое более агрессивно в отношении получения полосы и поднимающее скорость передачи до тех пор, пока не произойдет потеря, забьет соединения, которые анализируют RTT, чтобы избежать перегрузки. Таким образом, изменения на транспортном уровне должны либо адаптироваться универсально, либо тесно сотрудничать с сетевым уровнем, отслеживающим “алчные” соединения.
Использование групповых подтверждений в TCP мотивирует в TCP-tahoe сокращение ширины окна до единицы после потери, чтобы избежать всплеска пакетов из-за повторной их передачи. Это в свою очередь приводит к экспоненциальному увеличению размера окна при медленном старте необходимому для сетей с большим произведением полосы на задержку. С другой стороны, это экспоненциальное увеличение вызывает серьезные флуктуации трафика, которые, если размер буфера меньше чем 1/3 от произведения полосы на задержку, вызывает переполнение буфера и второй медленный старт, понижая пропускную способность. TCP-reno пытается избежать этого явления путем сокращения окна вдвое, при обнаружении потери. В то время как это при идеальных условиях обеспечивает улучшенную пропускную способность, TCP-reno в его нынешнем виде слишком уязвим для фазовых эффектов и множественной потери пакетов, чтобы стать заменителем для TCP-tahoe.
Основной проблемой с TCP- reno является то, что могут быть множественные ограничения на окно, связанные с одним эпизодом перегрузки, и что множественные потери могут приводить к таймауту (который на практике вызывает значительное снижение пропускной способности, если используется таймеры с низким разрешением). Предложенная в последнее время версия TCP (TCP-Vegas) [,] пытается реализовать ряд усовершенствований, таких, как более изощренная обработка и оценка RTT. Но для флуктуаций RTT в Интернет существует много других причин помимо заполнения буфера. Для того чтобы существенно улучшить существующие версии TCP, необходимо избегать резких сокращений размеров окна как в TCP-tahoe, так и в TCP-reno за исключением случая, когда имеет место продолжительная перегрузка (которая вызывает массовые потери пакетов). Одним возможным средством обработки изолированных потерь без изменения размера окна является использование некоторой формы селективного подтверждения. В ожидании разработки удовлетворительного нового варианта предлагается использовать TCP-tahoe (в сочетании с управлением сетевого уровня, чтобы оптимизировать рабочие характеристики), так как этот вариант несравненно устойчивей, чем TCP-reno.
Несовершенство TCP для соединений с высокими задержками распространения может вызвать проблемы при мультиплексировании потоков на короткие и дальние расстояния в WAN. Короче говоря, эти эксплуатационные проблемы могут не проявиться, так как WAN может быть существенно недогружена и там может не оказаться узких мест (т.e. размер окна, необходимый для хорошей работы может быть слишком мал, чтобы вызвать переполнение буфера, так что достигается максимальное стационарная пропускная способность). Однако для гарантирования рабочих характеристик в высоко загруженных сетях, каждое TCP соединение должно иметь зарезервированный буфер и полосу пропускания вдоль всего сетевого маршрута. Обычно, выделение ресурсов осуществляется при формировании соединения и заставляет коммутаторы и маршрутизаторы формировать независимые очереди для каждого соединения [], [].
Так как администрирование ресурсов по принципу “наилучшего возможного” может оказаться весьма дорого, более приемлемой альтернативой может оказаться резервирование ресурсов для каждого класса трафика . В такой ситуации несовершенство будет сохраняться, если TCP поддерживается поверх ATM с классом трафика UBR. Однако если TCP поддерживается поверх класса трафика ABR, варьирующаяся со временем скорость передачи, доступная для каждого соединения определяется на сетевом уровне и администрируется отправителем, так чтобы различные TCP соединения были изолированы друг от друга, даже если они используют совместно буферы.
Так как предубеждение против соединений с большими задержками RTT связано с механизмом адаптации окна, оно в принципе может быть преодолено путем модификации механизма мониторирования полосы во время фазы избежания перегрузки, например, путем увеличения размера окна так, чтобы темп увеличения пропускной способности для всех соединений был одним и тем же (такая схема была рассмотрена, но не рекомендована в []). Однако невозможно выбрать универсальный временной масштаб для настройки окна, который бы работал для сетей с разной пропускной способностью и топологией. Например, зондирование дополнительной полосы с темпом 1 Mb/s в секунду может быть слишком быстрым для сети с каналом 1 Mb/s, но слишком медленным для гигабитной сети. Таким образом, чтобы заставить работать такую схему, некоторый обмен между сетевым и транспортным уровнем был бы крайне существенным. Во-вторых, такая схема будет все же подвержена сильному воздействию некоторых недостатков TCP, таких как деградация рабочих характеристик при наличии случайных потерь и чрезмерных задержек, связанных с попытками использования дополнительной полосы в условиях полного использования канала. Таким образом, эта модификация не может считаться лучшим подходом к проблеме оптимальности.
Суммируя, можно сказать, что мы идентифицировали несколько недостатков TCP, мы также представили возможные средства получения хороших рабочих характеристик посредством решений сетевого уровня, таких как изоляция соединений друг от друга, и предоставление буферов достаточного объема, чтобы устранить быстрые вариации доступной канальной емкости.
Но нужно помнить, что нельзя увеличивать объем буфера беспредельно, так как это может привести к таймаутам и в конечном итоге к большим потерям пропускной способности. Особенно интересным является вопрос, как наилучшим образом поддержать TCP поверх ATM классов услуг ABR и UBR, так как это включает адаптацию сетевого и транспортного уровней. Другой важной областью исследований является разработка альтернативного механизма управления окном, который устранит некоторые недостатки TCP, сохранив его децентрализованную структуру. Децентрализованное адаптивное управление скоростью передачи, при сохранении справедливости распределения ресурсов является трудным, если вообще возможным, но некоторое улучшение TCP несомненно реально. Возможные усовершенствования могут превзойти алгоритм исключение перегрузки за счет более изощренной оценки задержек RTT, и использования селективного подтверждения, чтобы улучшить рабочие характеристики при наличии случайных потерь.
Здесь уместно сказать, что радикальным решением могло бы быть исчерпывающее информирование отправителя о состояние и динамике заполнения всех буферов вдоль виртуального соединения. Такой алгоритм можно реализовать лишь при условии, что все сетевое оборудование вдоль виртуального пути способно распознавать сегменты-отклики и выдавать требующиеся данные в рамках определенного протокола (в том числе и оборудование уровня L2!). Здесь предполагается, что маршрут движения сегментов туда и обратно идентичны. В последнее время появилось оборудование L2 (Ethernet), способное фильтровать трафик по IP-адресам и даже номерам портов (а это уже уровень L4). Так что это уже не представляется чем-то совершенно фантастическим. Такие сетевые приборы могли бы помещать в пакеты откликов ACK информацию о состоянии своих буферов. Учитывая, что объемы буферов в разных устройствах могут отличаться весьма сильно, имеет смысл выдавать не число занятых позиций, а относительную долю занятого буферного пространства. Проблема здесь в том, что длительное время даже в локальных сетях, я уже не говорю про Интернет, будут сосуществовать сетевые устройства, как поддерживающие этот новый протокол, так и старые - не поддерживающие.
Но даже в таких условиях этот протокол будет давать заметный выигрыш. Ведь новые устройства будут ставиться в первую очередь именно в “узких” местах сети, где потери были наиболее значимы. Условия загрузки нового устройства останутся теми же, но о них отправитель получит исчерпывающую информацию и за счет этого оптимизировать трафик. При этом отправитель должен отслеживать не просто состояние на текущий момент, но и темп заполнения и освобождения буферов. Ширина окна в этом случае может определяться на основе прогноза состояния буфера на момент, когда туда придет соответствующий ТСР-сегмент. Для этого отправителю придется выделить дополнительную память для хранения коэффициентов заполнения буферов. Задержка в цепи отслеживания состояния тракта при этом будет минимальной.
Проблема усложнена разнообразием технологий L2, ведь трудно себе представить, чтобы нужную информацию о состоянии буферов будет выдавать ATM или SDH. Но наметившаяся тенденция использования Ethernet не только в LAN, но в региональных сетях, может упростить задачу.
Альтернативой этому алгоритму могла бы служить схема, где каждому виртуальному соединению в каждом вовлеченном сетевом устройстве (включая L2) выделялся свой независимый буфер известного объема.
Любое из названных решений требует замены огромного объема оборудования. Но, во-первых, раз в 2-5 лет оборудование все равно обновляется, во-вторых, это даст выигрыш в пропускной способности не менее двух раз и существенно упростит задачу обеспечения требуемого уровня QoS.
Первым шагом на пути внедрения отслеживания уровня заполнения буфера может служить ECN-алгоритм, описанный выше.
Разрабатывая новые версии драйверов ТСР-протокола надо с самого начала думать и о сетевой безопасности, устойчивости программ против активных атак.
Новые трудности в реализации модели протокола ТСР возникли при работе современными быстрыми (1-10 Гбит/с) и длинными (RTT>200мсек) каналами. Для пакетов с длиной 1500 байт время формирования окна оптимального размера достигает 83333 RTT (режим предотвращения перегрузки), что при RTT=100мсек составляет 1,5 часа! При этом требования к вероятности потери пакетов становятся невыполнимыми.
В норме для таких каналов BER лежит в пределах 10-7 - 10-8. Разрешение проблемы возможно путем использования опции Jumbo пакетов или за счет открытия нескольких параллельных ТСР-соединений. В последнее время предложено несколько новых моделей реализации ТСР: High Speed TCP (HSTCP - ), Scalable TCP (STCP - T.Kelly), FAST (), XCP (http://portal.acm.org/citation.cfm?doid=633035), SABUL (Y.Gu, X.Hong). Модификации HSTCP и STCP характеризуются тем, что при нескольких потоках с разными RTT они некорректно распределяют полосу. В этих условиях заметный трудности создает синхронизация потерь для конкурирующих потоков. Специально для случая высокой скорости и больших задержек разработана модификация BI-TCP (Binary Increase TCP - , Lisong Xu, Khaled Harfoush and Injong Rhee, Binary Increase Congestion Control for Fast, Long Distance Networks).
Протокол BI-TCP имеет следующие свойства:
Масштабируемость. Он может масштабировать свою долю полоы до 10 Гбит/c при BER ~ 3,5-8
RTT fairness (равенство условий). При больших значениях окна RTT fairness пропорциональна отношению RTT (как в AIMD)
TCP friendliness (дружественность). Он достигает ограниченной ТСР-fairness для всех разиерах окна. Для высокиой вероятности потерь, где ТСР работает хорошо, ТСР-friendliness сопоставима с STCP.
Эквивалентность (fairness) и сходимость. По сравнению с HSTCP и STCP он позволяет получить большую эквивалентность полос пропускания в широком временном диапазоне и быструю сходимость к уровням справедливых долей.
Ниже в таблице приведены результаты расчета отношений пропускной способности для разных отношений RTT при быстроодействии канала 2,5 Гбит/с.
Таблица 1. Отношения пропускной способности протоколов при 2,5 Гбит/c
| Отношение RTT | 1 | 3 | 6 |
| AIMD | 1,05 | 6,56 | 22,55 |
| HSTCP | 0,99 | 47,42 | 131,03 |
| STCP | 0,92 | 140,52 | 300,32 |
AIMD демонстрирует квадратичный рост пропускной способности при увеличении отношения RTT (линейный рост "несправедливости"). Для других протоколов степень несправедливости еще выше.
Функция отклика протокола на перегрузку определяется отношением скоростей передачи пакетов в зависимости от вероятности их потери.
BI-TCP встраивается в TCP-SACK. В протоколе используются следующие фиксированные параметры:
Low_window - если размер окна больше чем этот порог, используется BI-TCP, в противном случае обычный ТСР.
Smax - максимальное приращение
Smin - минимальное приращение
b - мултипликативный коэффициент сокращений ширины окна.
default_max_win - значение максимума окна по умолчанию
В протоколе используются следующие переменные параметры:
max_win - максимальное значение ширины окна, в начале равно величине по умолчанию.
min_win - минимальная ширина окна
prev_win - максимальное значение ширины окна до установления нового максимума.
target_win - средняя точка между максимумом и минимумом ширины окна.
cwnd - размер окна перегрузки
is_BITCP_ss - Булева переменная, указывающая, находится ли протокол в режиме медленного старта. В начале = false
ss_cwnd - переменная, отслеживающая эвлюцию cwnd при медленном старте.
ss_target - значение cwnd после одного RTT при медленном старте BI-TCP.
При входе в режим быстрого восстановления:
if (low_window <= cwnd) {
prev_max = max_win; max_win = cwnd; cwnd = cwnd *(1-b); min_win = cwnd; if (prev_max > max _win) //Fast. Conv. max_win = (max_win + min_win)/2; target_win = (max_win + min_win)/2;
} else {
cwnd = cwnd*0,5; //normal TCP
Когда система не находится в режиме быстрого восстановления и приходит подтверждение для нового пакета, то
if (low_window > cwnd) { cwnd =cwnd + 1/cwnd; // normal TCP return
} if (is_BITCP_ss is false) { //bin.increase if (target_win - cwnd < Smax) // bin.search cwnd += (target_win - cwnd)/cwnd; else
cwnd += Smax/cwnd; // additive incre. if (max_win > cwnd) { min_win = cwnd; target_win = (max_win + min_win)/2;
} else {
is_BITCP_ss = true
ss_cwnd =1; ss_target = cwnd+1; max_win = default_max_win; }
} else { cwnd = cwnd + ss_cwnd/cwnd; if(cwnd >= ss_target) { ss_cwnd = 2*ss_cwnd; ss_target = cwnd + ss_cwnd; } if(ss_cwnd >= Smax) is_BITCP_ss = false; }
WAN-Error-Notify (WEN)
Сообщение WAN-Error-Notify является L2TP управляющим сообщением, посылаемым от LAC к LNS для индикации условий ошибки WAN (условия, которые реализовались в интерфейсе, поддерживающим PPP). Счетчики в этом сообщении являются накопительными. Это сообщение должно посылаться, только когда произошла ошибка, и не чаще чем раз в 60 секунд. Счетчики сбрасываются, когда реализуется новый вызов. Следующие AVP должны присутствовать в WEN:
Тип сообщения (Message Type)
Ошибки вызова (Call Errors)
Заголовки расширения IPv
В IPv6, опционная информация уровня Интернет записывается в отдельных заголовках, которые могут быть помещены между IPv6 заголовком и заголовком верхнего уровня пакета. Существует небольшое число таких заголовков, каждый задается определенным значением кода поля следующий заголовок. В настоящее время определены заголовки: маршрутизации, фрагментации, аутентификации, инкапсуляции, опций hop-by-hop, места назначения и отсутствия следующего заголовка. Как показано в примерах ниже, IPv6 пакет может нести нуль, один, или более заголовков расширения, каждый задается предыдущим полем следующий заголовок (рис. 4.4.1.1.15):

Рис. 4.4.1.1.15. Структура вложения пакетов для IPv6
Заголовки расширения не рассматриваются и не обрабатываются узлами по пути доставки. Содержимое и семантика каждого заголовка расширения определяет, следует или нет обрабатывать следующий заголовок. Следовательно, заголовки расширения должны обрабатываться строго в порядке их выкладки в пакете. Получатель, например, не должен просматривать пакет, искать определенный тип заголовка расширения и обрабатывать его до обработки предыдущих заголовков.
Единственное исключение из этого правила касается заголовка опций hop-by-hop, несущего в себе информацию, которая должна быть рассмотрена и обработана каждым узлом по пути доставки, включая отправителя и получателя. Заголовок опций hop-by-hop, если он присутствует, должен следовать непосредственно сразу после IPv6-заголовка. Его присутствие отмечается записью нуля в поле следующий заголовок заголовка IPv6.
Если в результате обработки заголовка узлу необходимо перейти к следующему заголовку, а код поля следующий заголовок не распознается, необходимо игнорировать данный пакет и послать соответствующее сообщение ICMP (parameter problem message) отправителю пакета. Это сообщение должно содержать код ICMP = 2 ("unrecognized next header type encountered " - встретился нераспознаваемый тип следующего заголовка) и поле - указатель на не узнанное поле в пакете. Аналогичные действия следует предпринять, если узел встретил код следующего заголовка равный нулю в заголовке, отличном от IPv6-заголовка.
Каждый заголовок расширения имеет длину кратную 8 октетам. Многооктетные поля в заголовке расширения выравниваются в соответствии с их естественными границами, т.е., поля с шириной в n октетов помещаются в n октетов, начиная с начала заголовка, для n = 1, 2, 4 или 8.
IPv6 включает в себя следующие заголовки расширения:
Опции hop-by-hop
Маршрутизация (routing;тип 0)
Фрагмент
Опции места назначения
Проверка прав доступа (authentication)
Поле безопасных вложений (encapsulating security payload)
Последние два описаны в RFC-1826 и RFC-1827.
Заголовок фрагмента
Заголовок фрагмента используется отправителем IPv6 для посылки пакетов длиннее, чем MTU пути до места назначения. (Замечание: в отличие от IPv4, фрагментация в IPv6 выполняется только узлами-отправителями, а не маршрутизаторами вдоль пути доставки). Заголовок фрагментации идентифицируется кодом поля следующий заголовок, равным 44 и имеет следующий формат (рис. 4.4.1.1.21):

Рис. 4.4.1.1.21. Формат заголовка фрагментации
| Следующий заголовок | 8-битовый селектор. Идентифицирует тип исходного заголовка фрагментируемой части исходного пакета. Использует те же коды протоколов, что и IPv4 [RFC-1700]. |
| Резерв | 8-битовое резервное поле. Инициализируется нулем при передаче и игнорируется при приеме. |
| Fragment offset | 13-битовое число без знака. Смещение в 8-октетном блоке, для данных, которые следуют за этим заголовком, началом отсчета является начало фрагментируемой части исходного пакета. |
| Резерв (второй) | 2-битовое резервное поле. Инициализируется нулем при передаче и игнорируется при приеме. |
| m флаг | 1 = есть еще фрагменты; 0 = последний фрагмент. |
| Идентификация | 32 бита |
Для того чтобы послать пакет с длиной больше MTU пути, узел-отправитель может разделить пакет на фрагменты и послать каждый фрагмент в виде отдельного пакета, сборка исходного пакета будет проведена получателем.
Для каждого пакета, который должен быть фрагментирован, узел-отправитель генерирует код идентификации. Этот код должен отличаться от аналогичных кодов идентификации, используемых для других фрагментируемых пакетов, которые пересылаются в данный момент. Под "данным моментом" подразумевается период времени жизни пакета, включая время распространения кадра от источника до получателя и время, необходимое для сборки исходного (оригинального) пакета получателем. Однако не предполагается, чтобы отправитель знал максимальное время жизни пакета. Скорее предполагается, что данное требование будет удовлетворено с помощью простого 32-разрядного счетчика, инкрементируемого всякий раз, когда очередной пакет должен быть фрагментирован.
Схема реализации генератора кода идентификации оставляется на усмотрение приложения. Если присутствует заголовок маршрутизации, под адресом получателя подразумевается конечное место назначения.
Под исходным большим, не фрагментированным пакетом подразумевается “оригинальный” пакет. Предполагается, что он состоит из двух частей, как показано на рисунке 4.4.1.1.22:
Исходный пакет:

Рис. 4.4.1.1.22.
Не фрагментированная часть состоит из IPv6 заголовка плюс любых заголовков расширения, которые должны быть обработаны узлами по пути до места назначения. Таким образом, нефрагментированная часть включает в себя все заголовки вплоть до заголовка маршрутизации, если таковой присутствует, или до заголовка опций hop-by-hop, если он присутствует.
Фрагментируемая часть представляет собой остальную часть пакета, т.е. включает в себя заголовки расширений, которые должны быть обработаны в узле места назначения, заголовок верхнего уровня и данные.
Фрагментируемая часть оригинального пакета делится на фрагменты с длиной кратной 8 октетам. Фрагменты пересылаются независимо с помощью пакетов-фрагментов. Как показано на рис. Рис. 4.4.1.1.23
Исходный пакет:

Пакеты-фрагменты:


o
o

Рис. 4.4.1.1.23.
Каждый пакет-фрагмент состоит из:
(1) Не фрагментируемой части оригинального пакета, с длиной поля данных оригинального IPv6 заголовка, измененной для того чтобы соответствовать длине фрагмента пакета (исключая длину самого IPv6-заголовка), а код поля следующий заголовок последнего заголовка не фрагментируемой части меняется на 44.
(2) Заголовка фрагмента, включающего в себя:
Код поля следующий заголовок, идентифицирующий первый заголовок фрагментируемой части оригинального пакета.
Смещение фрагмента, выражаемое в 8-октетных блоках и отсчитываемое от начала фрагментируемой части оригинального пакета. Смещение первого фрагмента (самого левого) равно нулю.
Код M-флага равен нулю, если фрагмент является последним (самым правым), в противном случае флаг равен 1.
(3) Сам фрагмент.
Длина фрагментов должна выбираться такой, чтобы пакеты-фрагменты соответствовали значению MTU для маршрута к месту назначения (назначений).
В узле места назначения из пакетов-фрагментов восстанавливается оригинальный пакет в не фрагментированной форме.
Восстановленный оригинальный пакет:

Рис. 4.4.1.1.24.
В процессе восстановления должны выполняться следующие правила:
Оригинальный пакет восстанавливается из фрагментов, которые имеют одни и те же адреса отправителя и получателя, а также код идентификации.
Не фрагментируемая часть восстанавливаемого пакета состоит из всех заголовков вплоть до (но не включая) заголовок фрагмента первого пакета-фрагмента (пакет со смещением равным нулю). При этом производятся следующие изменения:
Поле следующий заголовок последнего заголовка не фрагментируемой части берется из поля следующий заголовок заголовка первого фрагмента.
Длина поля данных восстановленного пакета вычисляется с использованием длины не фрагментируемой части, а также длины и смещения последнего фрагмента. Например, формула расчета длины поля данных восстановленного пакета имеет вид:
pl.orig = pl.first - fl.first - 8 + (8 * fo.last) + fl.last
где
pl.orig - поле длины данных восстановленного пакета.
pl.first - поле длины данных первого пакета-фрагмента.
fl.first - длина фрагмента, следующего за заголовком первого пакета-фрагмента.
fo.last - Поле смещения фрагмента в заголовке последнего пакета-фрагмента.
fl.last - длина фрагмента, следующего за заголовком фрагмента последнего пакета-фрагмента.
Фрагментируемая часть восстановленного пакета состоит из частей, следующих за заголовками в каждом из пакетов-фрагментов. Длина каждого фрагмента вычисляется путем вычитания из длины поля данных длины заголовков, размещенных между IPv6 заголовком и самим фрагментом. Их относительное положение в фрагментируемой части вычисляется на основе значения смещения фрагмента. Заголовок фрагмента отсутствует в восстановленном пакете.
В процессе сборки могут возникнуть следующие ошибки:
Если в пределах 60 секунд после прихода первого фрагмента получено недостаточно фрагментов для завершения сборки, процедура сборки должна быть прервана и все полученные фрагменты выкинуты.
Если первый фрагмент (т.e., пакет с нулевым смещением) получен, посылается ICMP сообщение “Time exceeded -- Fragment reassemble time exceeded”.
Если длина фрагмента, полученная из поля длины данных пакета, не является кратным 8 октетам, а M флаг фрагмента равен 1, фрагмент должен быть выброшен и должно быть послано сообщение ICMP (parameter problem, код 0) с указателем на поле длины данных пакета-фрагмента.
Если длина и смещение фрагмента таковы, что восстановленная длина поля данных фрагмента превосходит 65,535 октетов, фрагмент выбрасывается, посылается сообщение ICMP (parameter problem, код 0) с указателем на поле смещения фрагмента пакета-фрагмента.
Следующие условия не должны реализоваться, но они также рассматриваются как ошибка, если это произойдет:
Число и содержимое заголовков, предшествующих заголовку фрагмента, отличаются для разных фрагментов одного и того же исходного пакета. Какие бы заголовки ни предшествовали, заголовку фрагмента, они обрабатываются по прибытии на место назначения до постановки фрагментов в очередь на восстановление. Только эти заголовки из пакета с нулевым смещением сохраняются в восстановленном пакете.
Значение поля следующий заголовок в заголовках фрагментов различных фрагментов исходного пакета могут отличаться. Для последующей сборки используется только значение из пакета-фрагмента с нулевым смещением.
Заголовок опций места назначения
Заголовок опции места назначения используется для передачи опционной информации, которая должна анализироваться только узлом (узлами) назначения. Заголовок опции места назначения идентифицируется кодом поля следующий заголовок равным 60 предшествующего заголовка и имеет формат (рис. 4.4.1.1.25):

Рис. 4.4.1.1.25. Формат заголовка опции места назначения
Следующий заголовок - 8-битовый селектор. Идентифицирует тип заголовка, который непосредственно следует за заголовком опций места назначения. Использует те же коды протокола, что и IPv4 [RFC-1700].
Hdr Ext Len - 8-битовое целое без знака. Длина заголовка опций места назначения в 8-октетных блоках, исключая первые 8 октетов.
Опции - поле переменной длины, кратное 8 октетам. Содержит одну или более TLV-закодированных опций.
Здесь определены только две опции места назначения Pad1 и padn. Обратите внимание, что существует два способа кодировки опционной информации места назначения для пакетов IPv6: в заголовке опций места назначения, или в виде отдельного заголовка расширения. Заголовок фрагмента и заголовок идентификации являются примерами последнего подхода. Какой из подходов будет применен, зависит от того, какая операция желательна в узле места назначения:
если желательно, чтобы узел назначения уничтожил пакет и, если адрес места назначения не является мультикастинговым, отправителю посылается сообщение ICMP unrecognized type, затем информация может быть закодирована в отдельном заголовке или в опции места назначения с кодом типа опции, равным 11 в старших двух битах. Выбор может зависеть от таких факторов как число необходимых октетов, проблема выравнивания или более простой анализ пакета.
если желательна какая-либо иная операция, информация должна быть закодирована в виде опции места назначения с типом опции 00, 01 или 10 в старших двух битах.
Запрос исходящего вызова OCRQ (Outgoing-Call-Request)
Outgoing-Call-Request (OCRQ) является управляющим сообщением, посылаемым от LNS к LAC для индикации того, что необходимо осуществить исходящий вызов LAC. Оно является первым сообщением из трех, которые используются для установления сессии в пределах L2TP-туннеля.
OCRQ используется для индикации того, что сессия для данного вызова между LNS и LAC установлена и предоставляет LAC параметры L2TP-сессии и вызова.
LNS должен получить от LAC AVP Bearer Capabilities (возможностей носителя) на фазе установления туннеля, для того чтобы послать LAC исходящий вызов. Следующие AVP должны присутствовать в OCRQ:
Тип сообщения (Message Type)
ID, присвоенное сессии (Assigned Session ID)
Call Serial Number
Минимальный BPS
Максимальный BPS
Тип несущего канала (Bearer Type)
Тип кадрового обмена (Framing Type)
Телефонный номер адресата (Called Number)
| Следующие AVP могут присутствовать в OCRQ: | Sub-Address |
Запрос входящего вызова ICRQ (Incoming-Call-Request)
Incoming-Call-Request (ICRQ) является управляющим сообщением, посылаемым LAC к LNS, когда зарегистрирован входящий вызов. Это первое из трех сообщений обмена, используемых для установления сессии в пределах L2TP туннеля.
ICRQ используется для индикации того, что для данного вызова должна быть установлена сессия между LAC и LNS, и предоставляет LNS параметры сессии. LAC может отложить ответ на вызов, до тех пор пока он не получит ICRP от LNS, указывающий, что должна быть запущена сессия. Этот механизм позволяет LNS получить достаточно информации о вызове, прежде чем будет определено, следует ли на него отвечать. В качестве альтернативы LAC может ответить на вызов, согласовать аутентификацию LCP и PPP, и использовать информацию, полученную для выбора LNS. В этом случае, к моменту получения сообщения ICRP на вызов уже получен ответ; в этом случае LAC просто разыгрывает шаги "call indication" и "call answer". Следующие AVP должны присутствовать в ICRQ:
Тип сообщения
ID, Присвоенный сессии (Assigned Session ID)
Call Serial Number
Следующие AVP могут присутствовать в ICRQ:
Тип носителя (Bearer Type)
ID физического канала (Physical Channel ID)
Вызывающий номер (Calling Number)
Вызванный номер (Called Number)
Субадрес (Sub-Address)
Значения поля кода ошибки
Значения 0-7 определены в разделе 4.4.2. Значения 8-32767 доступны для присвоения через согласование с IETF [RFC 2434]. Оставшиеся значения поля кода ошибки доступны для присвоения в соответствии с алгоритмом “первый пришел - первым обслужен” [RFC 2434].
Значения поля кода результата
AVP кода результата может быть включено в сообщения CDN и StopCCN. Допустимые значения поля кода результата AVP зависят от значения типа сообщения AVP. Для сообщения StopCCN, значения 0-7 определены в разделе 4.4.2; для сообщения StopCCN, значения 0-11 определены в том же разделе. Оставшиеся значения поля кода результата для обоих сообщений доступны для присвоения через согласование с IETF [RFC 2434].
Значения результирующих кодов AVP
Как это определено в разделе 4.4.2, результирующий код AVP (тип атрибута 1) содержит три поля. Два из них (поля кодов результата и ошибки) имеют значения, обслуживаемые IANA.
Значения типа сообщения AVP
Как определено в разделе 4.4.1, AVP типа сообщения (тип атрибута 0) имеет значение поддерживаемое IANA. Значения 0-16 определены в разделе 3.2, остальные - могут присваиваться по согласованию с IETF [RFC 2434]
Значения типов прокси аутентификации AVP
AVP типа прокси Authen (тип атрибута 29) имеет ассоциированное значение, поддерживаемое IANA. Значения 0-5 определены в разделе 4.4.5, оставшиеся значения доступны для присвоения по схеме “первым пришел - первым обслужен” [RFC 2434].